Clear Sky Science · it
Previsione del glucosio nel sangue consapevole del futuro usando distillazione della conoscenza con modelli sequence-to-sequence basati su transformer
Perché prevedere la glicemia è importante
Per le persone con diabete di tipo 1, la glicemia può salire e scendere rapidamente dopo i pasti, l’esercizio, lo stress o le dosi di insulina. Essere in grado di vedere non solo qual è il livello di glucosio ora, ma dove si sta dirigendo nelle prossime ore, può aiutarli a evitare ipoglicemie e iperglicemie pericolose, regolare l’insulina in tempo e pianificare le attività quotidiane con maggiore sicurezza. Questo studio esplora un nuovo modo per insegnare ai computer a prevedere il glucosio futuro utilizzando «di nascosto» informazioni su pasti e insulina in arrivo durante l’addestramento, mantenendo però il funzionamento nel mondo reale in cui il futuro è sconosciuto.
Uno sguardo più intelligente per la cura del diabete
I monitor continui del glucosio di oggi forniscono letture ogni pochi minuti e gli algoritmi moderni già sfruttano questi dati per prevedere il glucosio nel prossimo futuro. La maggior parte degli strumenti esistenti, tuttavia, guarda solo indietro: analizza letture di glucosio passate e talvolta altri segnali come frequenza cardiaca o movimento. Nella pratica ignorano spesso l’impatto potente di eventi futuri come il prossimo pasto o un bolo di insulina, perché tali eventi non sono prevedibili con affidabilità. Di conseguenza, le previsioni tendono a peggiorare proprio quando i livelli di glucosio oscillano più rapidamente, ad esempio subito dopo aver mangiato o dopo correzioni di iperglicemia. Gli autori sostengono che, per supportare davvero le decisioni quotidiane nel diabete, le previsioni devono in qualche modo apprendere questi disturbi futuri senza aspettarsi che siano disponibili al momento dell’uso.
Insegnare con indizi extra, poi testare senza
I ricercatori introducono un framework di apprendimento «consapevole del futuro» che separa addestramento e distribuzione. Durante l’addestramento utilizzano registrazioni ricche provenienti da due grandi dataset di persone con diabete di tipo 1, che includono letture del glucosio, dosi di insulina e informazioni sui pasti. Costruiscono un potente modello «insegnante» basato su un transformer, un’architettura di deep learning nota per gestire sequenze lunghe. Questo insegnante vede sia i dati glicemici passati sia i pasti e l’insulina in arrivo per le due ore successive, e impara come quegli eventi futuri modellano i pattern glicemici. Parallelamente, progettano un modello «studente» con una struttura input–output simile, ma lo studente vede solo dati passati, proprio come farebbe un dispositivo nel mondo reale.
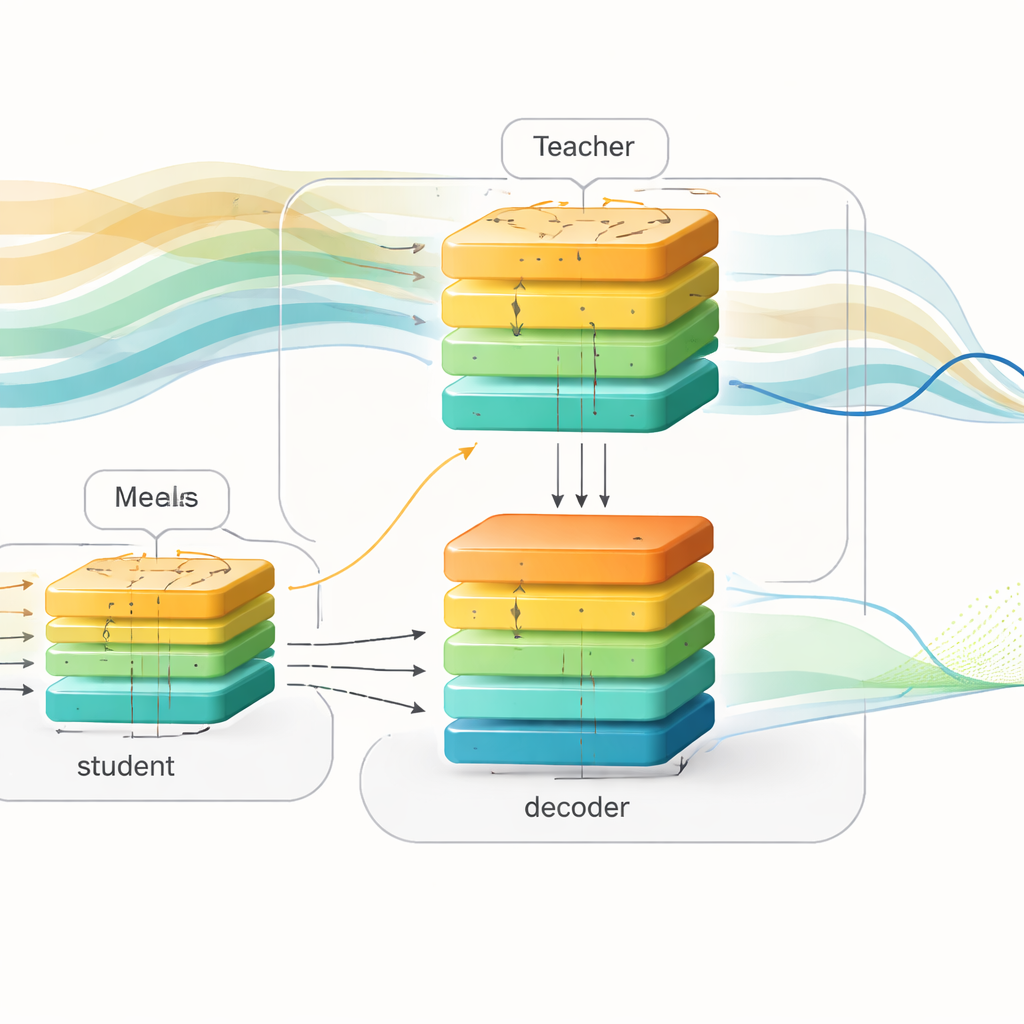
Trasferire la conoscenza dall’insegnante allo studente
Per colmare il divario tra queste due visioni del mondo, gli autori usano una tecnica chiamata distillazione della conoscenza. Invece di limitarsi a far corrispondere le predizioni finali dell’insegnante, richiedono anche che lo studente imiti la rappresentazione interna dell’insegnante su come il glucosio è destinato a evolvere. Sia l’insegnante sia lo studente inviano i loro segnali interni allo stesso decoder che trasforma pattern astratti in curve glicemiche future. Durante l’addestramento lo studente viene guidato su tre fronti contemporaneamente: deve prevedere il vero glucosio futuro, mantenere i propri pattern interni vicini a quelli dell’insegnante e approssimare le previsioni dell’insegnante. Col tempo lo studente impara a «pensare» indirettamente ai pasti e all’insulina in arrivo, inferendo probabili oscillazioni future unicamente dalle forme della storia recente.
Test su dati reali di pazienti con diabete
Il team valuta l’approccio su due dataset indipendenti: OhioT1DM, che segue 12 adulti per otto settimane di vita quotidiana, e AZT1D, che traccia 25 persone che utilizzano sistemi di erogazione insulinica automatizzati. Dopo un’attenta gestione delle letture del sensore mancanti, confrontano il loro modello studente con diversi solidi baseline di reti neurali, tra cui LSTM, LSTM bidirezionali, reti convoluzionali–ricorrenti e modelli transformer che non impiegano l’addestramento future-aware. Su orizzonti di previsione da 30 a 120 minuti, il nuovo metodo riduce consistentemente misure d’errore comuni come la root mean squared error e la mean absolute error. L’affidabilità clinica è esaminata tramite la Clarke error grid, che valuta le predizioni in base al potenziale danno nelle decisioni cliniche; più del 90% delle previsioni di questo modello ricade nelle zone considerate sicure o accettabili per guidare la terapia.
Cosa potrebbe significare per la vita quotidiana
Semplificando, lo studio mostra che permettere a un modello di esercitarsi con un’anteprima del futuro e poi distillare quell’esperienza in una versione più snella che funziona senza conoscenza del futuro può rendere le previsioni del glucosio più accurate—soprattutto da 60 a 120 minuti di anticipo. Sono queste previsioni a lungo raggio che aiutano le persone a decidere se mangiare uno spuntino ora per evitare un’ipoglicemia più tardi, o regolare una dose di insulina in tempo per prevenire un’iperglicemia imminente. Pur rimanendo lavoro di ricerca e basandosi su routine relativamente regolari, il lavoro indica la strada verso strumenti di supporto decisionale più intelligenti e sistemi insulinici a ciclo chiuso che anticipano meglio le oscillazioni glicemiche future, anche quando l’unica informazione disponibile è ciò che è già accaduto.
Citazione: Sun, X., Li, H. & Yu, X. Future-aware blood glucose forecasting using knowledge distillation with transformer-based sequence-to-sequence models. Sci Rep 16, 11404 (2026). https://doi.org/10.1038/s41598-026-41787-7
Parole chiave: previsione del glucosio nel sangue, diabete di tipo 1, deep learning, modelli transformer, distillazione della conoscenza