Clear Sky Science · sv
Multimodal inlärning över domäner för stressnivåprediktion: ett hybridramverk med djupinlärning som integrerar oberoende EEG- och ansiktsuttrycks-datamängder
Varför stressmätning är viktig
De flesta upplever att stress kryper in i vardagen, men det är svårt att mäta den på ett tydligt, objektivt sätt. Den här studien undersöker hur datorer kan läsa signaler från både hjärnan och ansiktet för att sortera en persons stressnivå i låg, måttlig eller hög. Genom att kombinera vad som händer inuti huvudet med vad som syns i ansiktet strävar forskarna efter att gå bortom enkla humörkontroller och skapa verktyg som så småningom kan stödja välmående på jobbet, i hemmet och i digitala enheter.
Två fönster mot stress
Arbetet fokuserar på två mycket olika signaler som relaterar till stress. Den ena är elektrisk aktivitet i hjärnan, fångad som EEG, vilket speglar inre reaktioner som andra inte kan se. Den andra är ansiktsuttryck, som avslöjar yttre tecken som spänning, oro eller lugn. Istället för att samla nya data från samma frivilliga återanvänder författarna två välkända publika samlingar: DEAP för EEG-inspelningar och FER2013 för ansiktsbilder. Ingen av uppsättningarna är märkta med medicinska stresspoäng, så teamet definierar noggrant tre stressband baserat på hur intensiv hjärnarousal är och vilka känslor som syns i ansiktet. De testar också hur känsliga resultaten är för små förändringar i dessa etikettval.
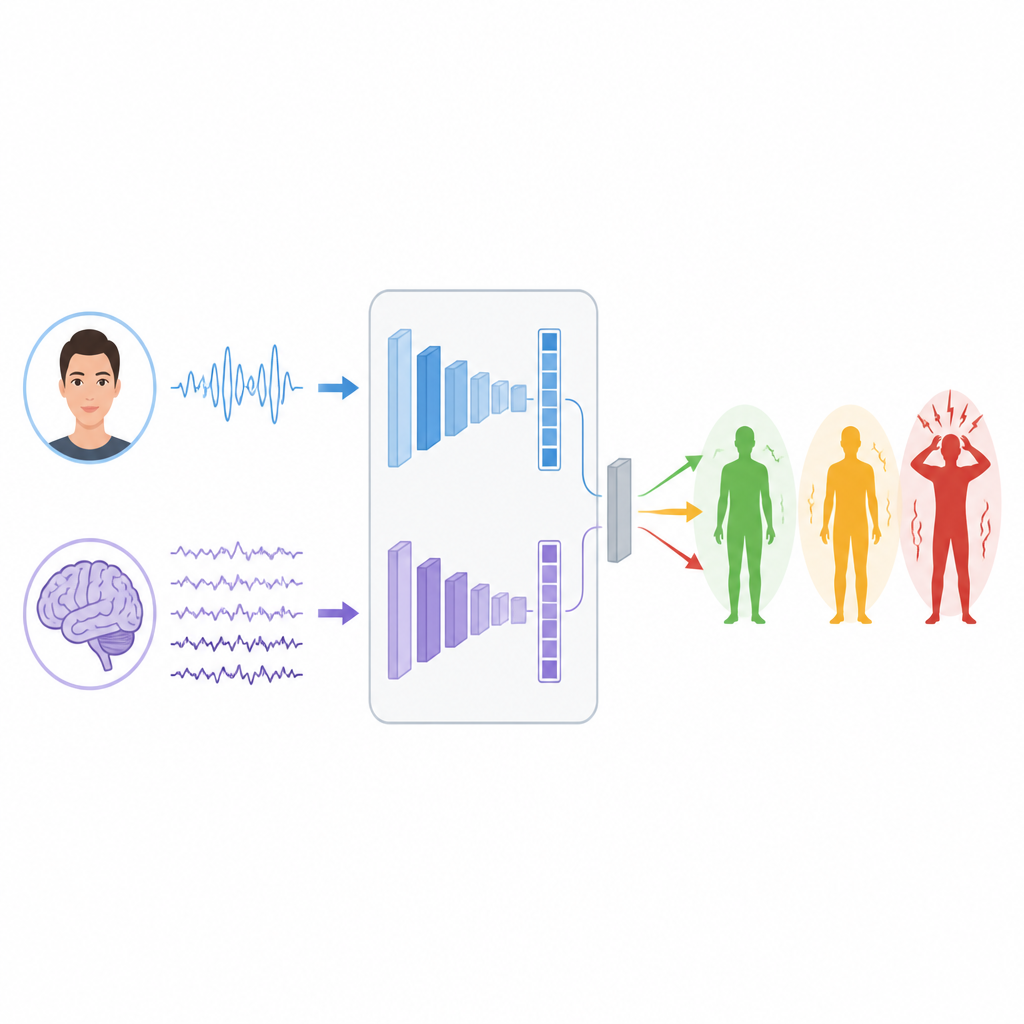
Att lära maskiner att läsa signaler
För att lära sig mönster i dessa signaler bygger forskarna två separata djupinlärningsgrenar. För EEG använder de en typ av nätverk kallat LSTM som är bra på att följa hur information förändras över tid, vilket hjälper till att följa rytmer och utbrott i hjärnvågorna som kan relatera till stress. För ansikten kombinerar de en Vision Transformer, som uppmärksammar hela bilden, med ett klassiskt konvolutionsnät som fokuserar på lokala detaljer som muskelspänningar runt ögon eller mun. Varje gren omvandlar sin råa input till en kompakt uppsättning funktioner som sammanfattar vad den har lärt sig om möjliga stressnivåer.
Att föra samman hjärna och ansikte
Nyckelfrågan är hur man slår ihop dessa två vyer när de kommer från helt olika personer och experiment. Författarna testar tre fusionsstrategier. Vid tidig fusion kopplar de helt enkelt ihop funktionslistorna från hjärna och ansikte innan de skickas till en klassificerare. Vid sen fusion ger varje gren sin egen gissning och systemet medelvärderar eller röstar om slutgiltigt svar. Vid staplad fusion lär sig en modell på andra nivån hur de två uppsättningarna av gissningar bäst kombineras, och upptäcker när den ska lita mer på den ena signalen än den andra. Noggranna åtgärder vidtas för att hålla tränings- och testdata separata så att resultaten förblir ärliga och jämförbara.
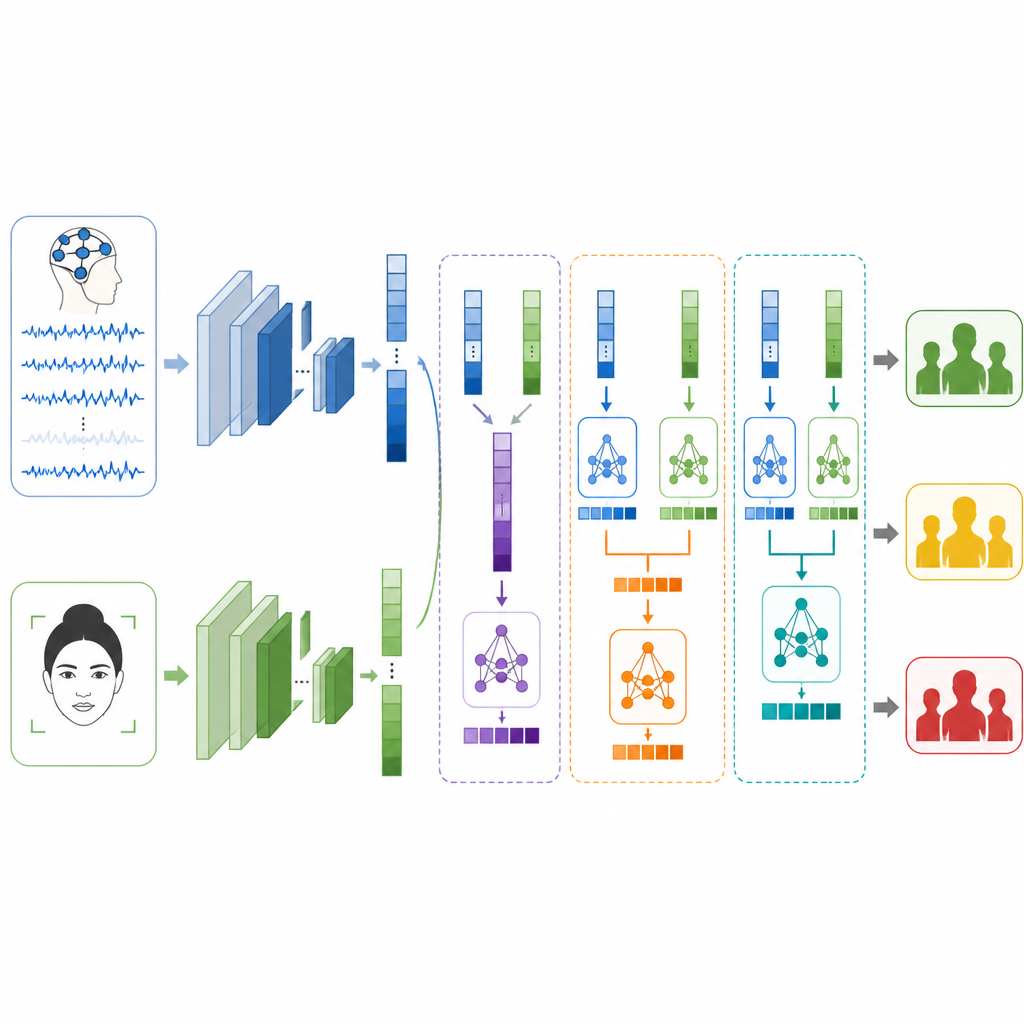
Vad systemet kan och inte kan göra
På egen hand klassificerar ansiktsmodellen stressnivåer med ungefär fyra av fem fall korrekta, medan hjärnmodellen klarar sig något bättre än tre av fem. När de sammansmälts förbättras prestandan över hela linjen. Tidig fusion slår redan båda enkla källorna, men sen fusion gör det bättre, vilket tyder på att det är användbart att låta varje gren specialisera sig. Den staplade fusionmetoden presterar bäst av alla, och tilldelar rätt stressnivå i mer än nio av tio testexempel samt får höga poäng på precision, recall och F1-mått. Författarna betonar dock att deras etiketter endast är substitut baserade på känsla och arousal, inte kliniska diagnoser, och att EEG- och ansiktsdata kommer från olika frivilliga, vilket begränsar hur direkt metoden speglar verklig stress.
Vad detta innebär för vardagen
Enkelt uttryckt visar denna forskning att en dator mer tillförlitligt kan sortera människor i låga, måttliga och höga stressgrupper när den lär sig från både hjärnaktivitet och ansiktsuttryck snarare än från någon av källorna ensam, även när dessa datakällor samlats in separat. Ramverket erbjuder ett recept för att bygga framtida system som kan uppmärksamma stigande stress på kontor, inom vården eller i interaktiva enheter utan att kräva perfekt synkroniserade sensorer. Innan sådana verktyg kan vägleda personliga hälsobeslut måste de dock testas på nya data med verkliga stressmätningar och matchade inspelningar, men denna studie lägger en viktig teknisk grund.
Citering: Pechetti, S., Chennu, L., Chintakunta, V. et al. Cross-domain multimodal learning for stress-level prediction: a hybrid deep learning framework integrating independent EEG and facial expression datasets. Sci Rep 16, 15303 (2026). https://doi.org/10.1038/s41598-026-41250-7
Nyckelord: stressdetektion, EEG-signaler, ansiktsuttryck, multimodal inlärning, djupinlärning