Clear Sky Science · ru
Мультимодальное междоменное обучение для прогнозирования уровня стресса: гибридная глубинная архитектура, интегрирующая раздельные наборы данных ЭЭГ и выражений лица
Почему важно отслеживание стресса
У большинства людей стресс незаметно проникает в повседневную жизнь, но измерить его четко и объективно сложно. В этом исследовании изучается, как компьютеры могут считывать сигналы и из мозга, и с лица, чтобы отнести уровень стресса человека к низкому, умеренному или высокому. Объединив то, что происходит в голове, с тем, что видно по лицу, авторы стремятся выйти за рамки простых самопроверок настроения и создать инструменты, которые в будущем могли бы поддерживать благополучие на работе, дома и в цифровых устройствах.
Два окна в стресс
Работа фокусируется на двух очень разных сигналах, связанных со стрессом. Один — электрическая активность мозга, фиксируемая как ЭЭГ, отражающая внутренние реакции, которые другие не видят. Другой — выражение лица, показывающее внешние признаки, такие как напряжение, тревога или спокойствие. Вместо сбора новых данных у тех же добровольцев авторы повторно используют два популярных публичных набора: DEAP для записей ЭЭГ и FER2013 для изображений лиц. Ни один из наборов не помечен медицинскими оценками стресса, поэтому команда аккуратно определяет три диапазона стресса на основе интенсивности возбуждения мозга и видимых эмоций на лице. Они также проверяют чувствительность результатов к небольшим изменениям этих меток.
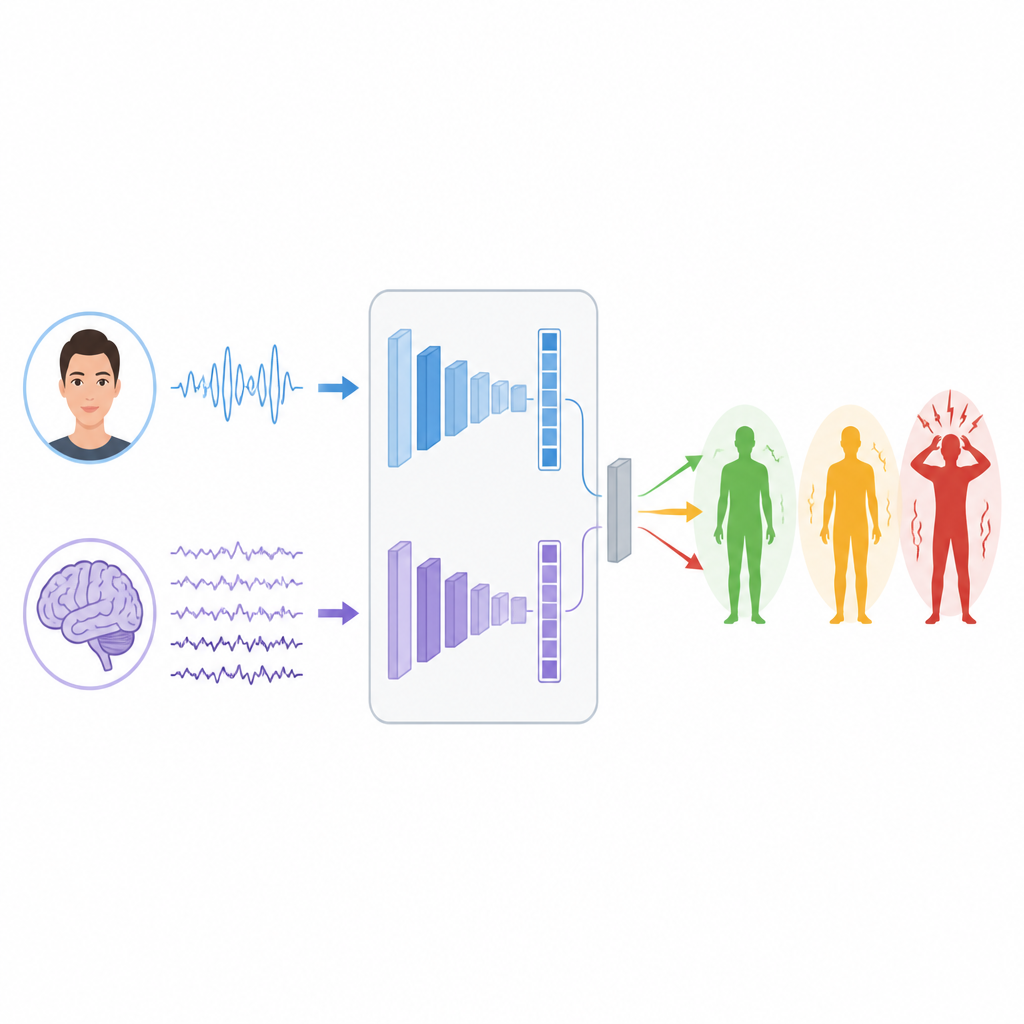
Обучение машин чтению сигналов
Чтобы выучить закономерности в этих сигналах, исследователи строят две отдельные ветви глубинного обучения. Для ЭЭГ они используют тип сети LSTM, хорошо подходящий для отслеживания изменения информации во времени, что помогает улавливать ритмы и всплески в мозговых волнах, связанные со стрессом. Для лиц они комбинируют Vision Transformer, который учитывает изображение целиком, с классической сверточной сетью, фокусирующейся на локальных деталях, таких как напряжение мышц вокруг глаз или рта. Каждая ветвь преобразует свои исходные данные в компактный набор признаков, суммирующий то, что она узнала о возможных уровнях стресса.
Скрепляя мозг и лицо
Ключевой вопрос — как объединить эти два взгляда, когда они получены от совершенно разных людей и экспериментов. Авторы тестируют три стратегии слияния. При ранней фьюжн они просто объединяют списки признаков от мозга и лица перед подачей в классификатор. При поздней фьюжн каждая ветвь выдает собственный прогноз, и система усредняет или голосует за итоговый ответ. В стекированной фьюжн модель второго уровня учится комбинировать два набора прогнозов, выявляя, когда одному сигналу стоит доверять больше, чем другому. Приняты тщательные меры по раздельному формированию обучающих и тестовых данных, чтобы результаты оставались честными и сопоставимыми.
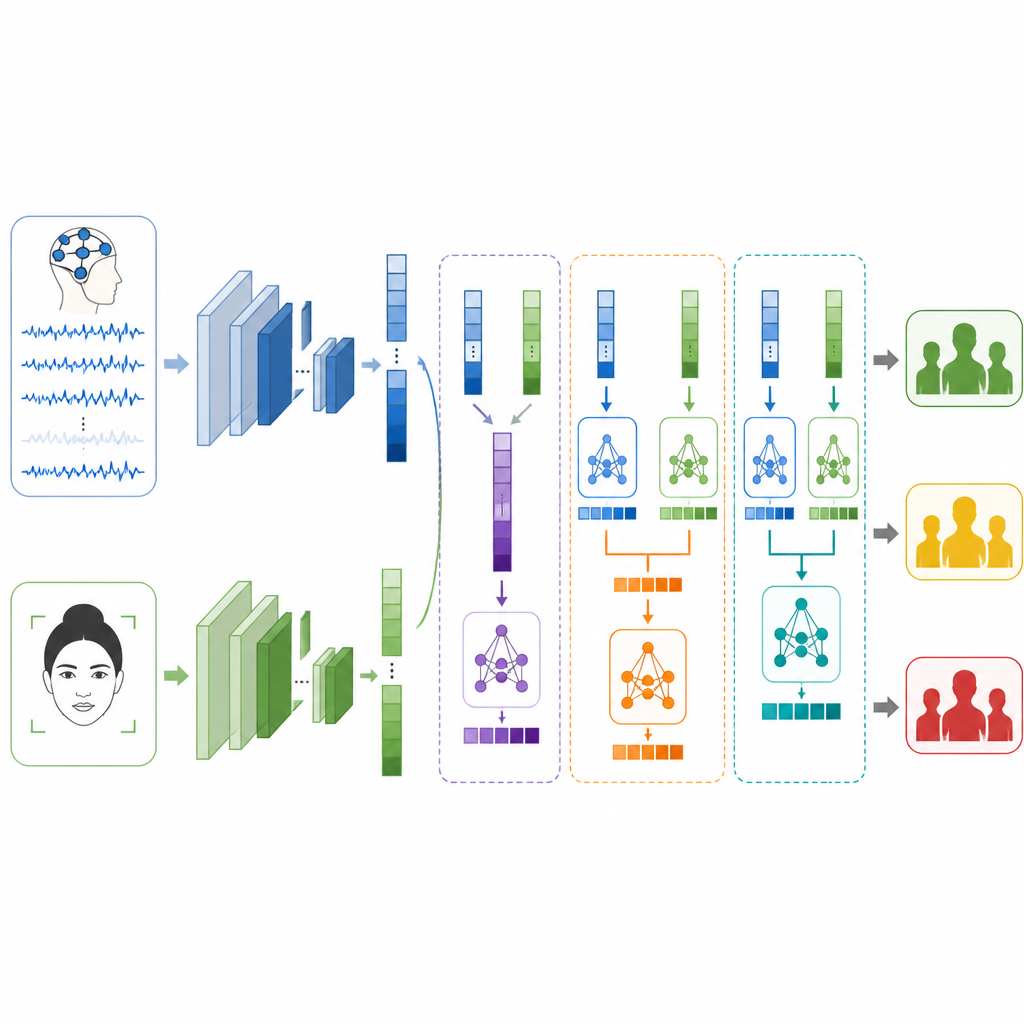
Что система может и чего не может
По отдельности модель по лицу классифицирует уровни стресса примерно в четырех из пяти случаев правильно, тогда как модель по мозгу показывает чуть более трех из пяти. При слиянии показатели улучшаются по всем направлениям. Ранняя фьюжн уже превосходит обе одиночные модели, но поздняя фьюжн дает еще лучшие результаты, что указывает на полезность специализации каждой ветви. Метод стекированного фьюжн показывает наилучшие результаты, правильно определяя уровень стресса более чем в девяти из десяти тестовых примеров и демонстрируя высокие значения точности, полноты и F1. Тем не менее авторы подчеркивают, что их метки — лишь заместители, основанные на эмоции и возбуждении, а не на клинических диагнозах, и что данные ЭЭГ и лица получены от разных добровольцев, что ограничивает прямую переносимость метода на реальную жизнь.
Что это значит для повседневной жизни
Проще говоря, исследование показывает, что компьютер может надежнее распределять людей по низкому, среднему и высокому уровням стресса, когда он обучается на данных как мозговой активности, так и выражений лица, а не на одном источнике, даже если эти источники собраны раздельно. Предложенная архитектура дает рецепт для создания будущих систем, которые могли бы отслеживать растущий стресс в офисах, системе здравоохранения или интерактивных устройствах без требования идеально синхронизированных сенсоров. Прежде чем такие инструменты смогут управлять личными решениями о здоровье, их нужно будет протестировать на новых данных с истинными измерениями стресса и сопоставленными записями, но это исследование закладывает важный технический фундамент.
Цитирование: Pechetti, S., Chennu, L., Chintakunta, V. et al. Cross-domain multimodal learning for stress-level prediction: a hybrid deep learning framework integrating independent EEG and facial expression datasets. Sci Rep 16, 15303 (2026). https://doi.org/10.1038/s41598-026-41250-7
Ключевые слова: обнаружение стресса, сигналы ЭЭГ, выражения лица, мультимодальное обучение, глубинное обучение