Clear Sky Science · pl
Uczenie wielodomenowe multimodalne do przewidywania poziomu stresu: hybrydowe głębokie uczenie integrujące niezależne zbiory danych EEG i mimiki twarzy
Dlaczego śledzenie stresu ma znaczenie
Większość ludzi odczuwa narastający stres w codziennym życiu, jednak trudno go zmierzyć w sposób jasny i obiektywny. Badanie analizuje, jak komputery mogą odczytywać sygnały zarówno z mózgu, jak i z twarzy, aby przypisać poziom stresu osoby do kategorii niskiego, umiarkowanego lub wysokiego. Łącząc to, co dzieje się wewnątrz głowy, z tym, co widoczne na twarzy, autorzy dążą do wyjścia poza proste oceny nastroju i stworzenia narzędzi, które mogłyby w przyszłości wspierać dobre samopoczucie w pracy, w domu i w urządzeniach cyfrowych.
Dwa okna na stres
Praca koncentruje się na dwóch bardzo różnych sygnałach powiązanych ze stresem. Pierwszym jest aktywność elektryczna mózgu rejestrowana jako EEG, która odzwierciedla wewnętrzne reakcje niewidoczne dla innych. Drugim jest mimika twarzy, ukazująca zewnętrzne oznaki, takie jak napięcie, niepokój czy spokój. Zamiast zbierać nowe dane od tych samych ochotników, autorzy korzystają z dwóch popularnych publicznych zbiorów: DEAP dla zapisów EEG i FER2013 dla obrazów twarzy. Żaden z zestawów nie ma oznaczeń medycznych dotyczących stresu, więc zespół precyzyjnie definiuje trzy pasma stresu na podstawie intensywności pobudzenia mózgowego i emocji widocznych na twarzy. Testują też, jak wrażliwe są ich wyniki na drobne zmiany w tych przyporządkowaniach etykiet.
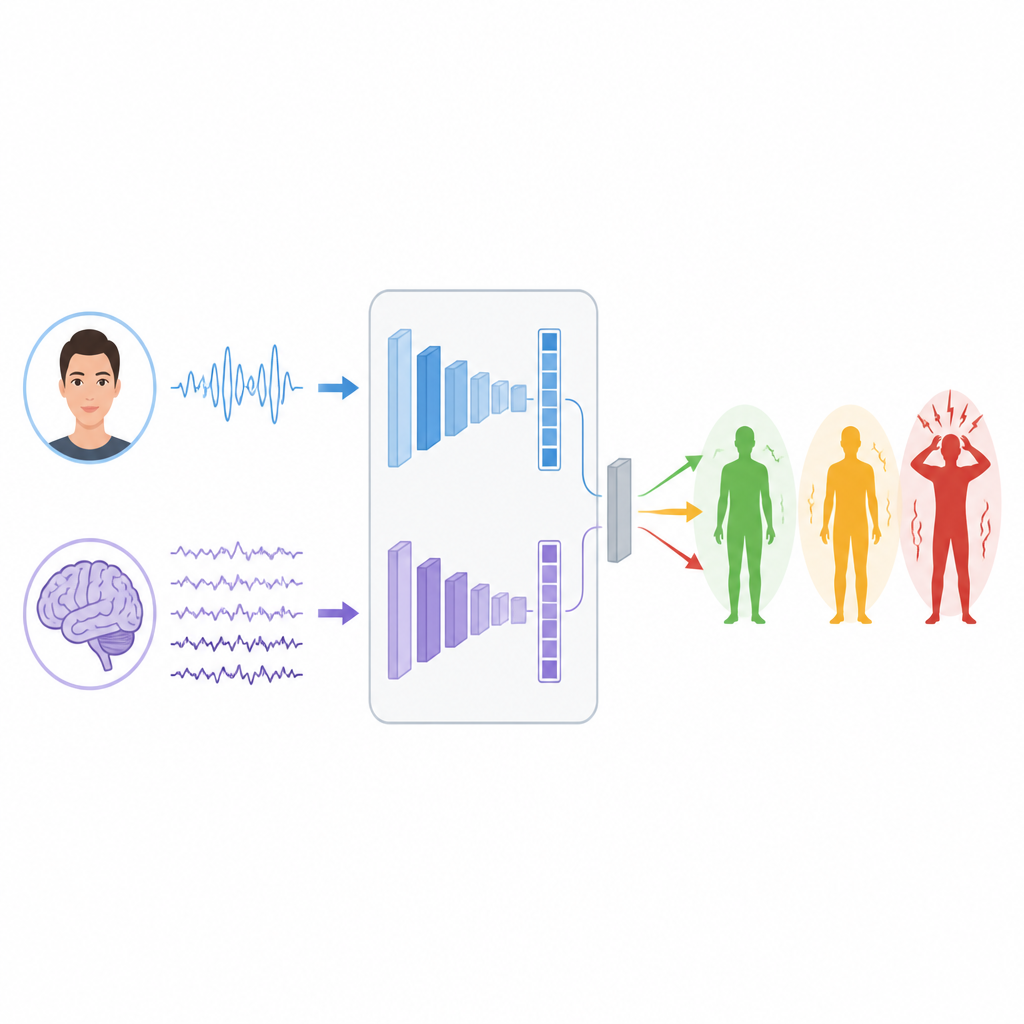
Uczenie maszyn do odczytu sygnałów
Aby wydobyć wzorce z tych sygnałów, badacze budują dwie oddzielne gałęzie głębokiego uczenia. Dla EEG używają typu sieci zwanego LSTM, dobrze nadającego się do śledzenia zmian w czasie, co pozwala wychwycić rytmy i wybuchy w falach mózgowych mogące wiązać się ze stresem. Dla twarzy łączą Vision Transformera, który „zwraca uwagę” na całość obrazu, z klasyczną siecią konwolucyjną koncentrującą się na lokalnych szczegółach, takich jak napięcie mięśni wokół oczu czy ust. Każda gałąź przekształca surowe wejście w zwarte cechy podsumowujące to, czego nauczyła się o możliwych poziomach stresu.
Łączenie mózgu i twarzy
Kluczowe pytanie brzmi, jak scalić te dwa widoki, gdy pochodzą od zupełnie różnych osób i eksperymentów. Autorzy testują trzy strategie fuzji. W fuzji wczesnej po prostu łączą listy cech z mózgu i twarzy przed podaniem ich do klasyfikatora. W fuzji późnej każda gałąź samodzielnie wydaje trafienie, a system uśrednia lub głosuje nad ostateczną odpowiedzią. W fuzji kaskadowej model drugiego poziomu uczy się, jak łączyć dwa zestawy predykcji, odkrywając, kiedy bardziej zaufać jednemu sygnałowi niż drugiemu. Podejmowane są staranne kroki, aby zachować rozdział danych treningowych i testowych, dzięki czemu wyniki pozostają uczciwe i porównywalne.
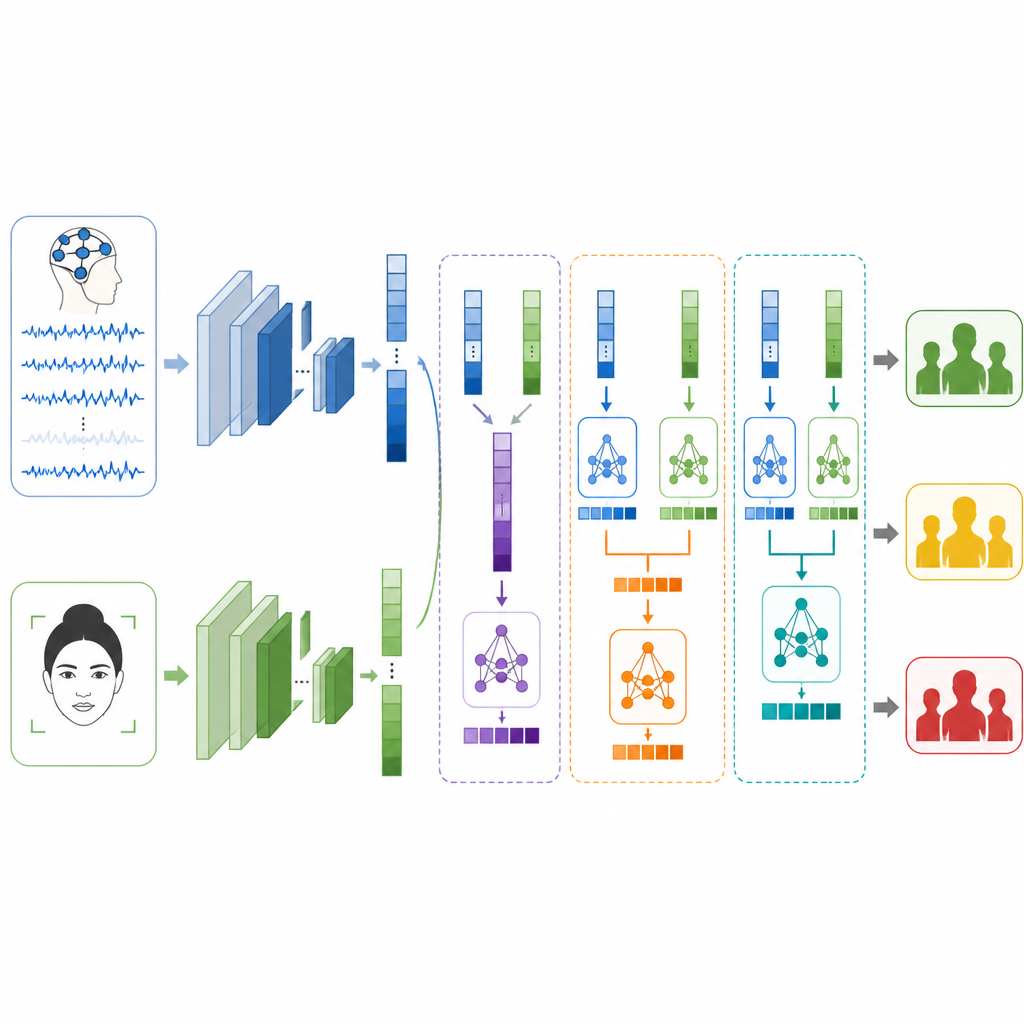
Co system potrafi, a czego nie
Samoistnie model twarzy klasyfikuje poziomy stresu z trafnością wynoszącą około czterech na pięć przypadków, podczas gdy model mózgowy radzi sobie nieco lepiej niż trzy na pięć. Po połączeniu wydajność poprawia się we wszystkich aspektach. Fuzja wczesna przewyższa już oba pojedyncze źródła, ale fuzja późna wypada lepiej, co sugeruje, że pozwalanie każdej gałęzi na specjalizację jest korzystne. Metoda fuzji kaskadowej daje najlepsze rezultaty, prawidłowo przypisując poziom stresu w ponad dziewięciu na dziesięć przykładach testowych i osiągając wysokie wyniki w miarach precyzji, odzysku (recall) i F1. Nadal jednak autorzy podkreślają, że ich etykiety są jedynie zastępcze, oparte na emocjach i pobudzeniu, a nie na diagnozach klinicznych, oraz że dane EEG i twarzy pochodzą od różnych ochotników, co ogranicza bezpośrednie odzwierciedlenie rzeczywistego stresu.
Co to oznacza w codziennym życiu
Mówiąc prosto, badanie pokazuje, że komputer może bardziej wiarygodnie przypisywać ludzi do grup niskiego, umiarkowanego i wysokiego stresu, gdy uczy się na podstawie zarówno aktywności mózgu, jak i mimiki twarzy, zamiast z jednego źródła, nawet gdy te dane były zbierane niezależnie. Ramy te oferują przepis na budowę przyszłych systemów, które mogłyby wykrywać narastający stres w biurach, opiece zdrowotnej czy urządzeniach interaktywnych bez wymogu idealnie zsynchronizowanych czujników. Zanim takie narzędzia będą mogły wspierać decyzje dotyczące zdrowia osobistego, trzeba je przetestować na nowych danych z rzeczywistymi pomiarami stresu i zsynchronizowanymi nagraniami, ale to badanie kładzie ważne techniczne podstawy.
Cytowanie: Pechetti, S., Chennu, L., Chintakunta, V. et al. Cross-domain multimodal learning for stress-level prediction: a hybrid deep learning framework integrating independent EEG and facial expression datasets. Sci Rep 16, 15303 (2026). https://doi.org/10.1038/s41598-026-41250-7
Słowa kluczowe: wykrywanie stresu, sygnały EEG, mimika twarzy, uczenie multimodalne, głębokie uczenie