Clear Sky Science · de
Domänenübergreifendes multimodales Lernen zur Stressniveau-Vorhersage: ein hybrides Deep-Learning-Framework, das unabhängige EEG- und Gesichtsausdrucksdaten integriert
Warum Stressüberwachung wichtig ist
Die meisten Menschen empfinden, dass Stress in ihren Alltag schleicht, doch er lässt sich nur schwer klar und objektiv messen. Diese Studie untersucht, wie Computer Signale aus Gehirn und Gesicht lesen können, um das Stressniveau einer Person in niedrig, mäßig oder hoch einzuordnen. Indem sie das, was im Kopf passiert, mit dem, was sich im Gesicht zeigt, kombinieren, wollen die Forschenden über einfache Stimmungschecks hinausgehen und Werkzeuge entwickeln, die langfristig das Wohlbefinden bei der Arbeit, zu Hause und in digitalen Geräten unterstützen könnten.
Zwei Fenster auf Stress
Die Arbeit konzentriert sich auf zwei ganz unterschiedliche Stresssignale. Das eine ist elektrische Aktivität im Gehirn, erfasst als EEG, das innere Reaktionen widerspiegelt, die andere Menschen nicht sehen können. Das andere ist der Gesichtsausdruck, der äußere Anzeichen wie Anspannung, Sorge oder Gelassenheit zeigt. Anstatt neue Daten von denselben Versuchspersonen zu erheben, verwenden die Autorinnen und Autoren zwei bekannte öffentliche Datensätze erneut: DEAP für EEG-Aufnahmen und FER2013 für Gesichtsaufnahmen. Keiner der Datensätze ist mit medizinischen Stresswerten gelabelt, daher definiert das Team sorgfältig drei Stressbänder basierend auf der Intensität der Gehirnarousal und den sichtbaren Emotionen im Gesicht. Sie prüfen auch, wie empfindlich ihre Ergebnisse gegenüber kleinen Änderungen dieser Label-Entscheidungen sind.
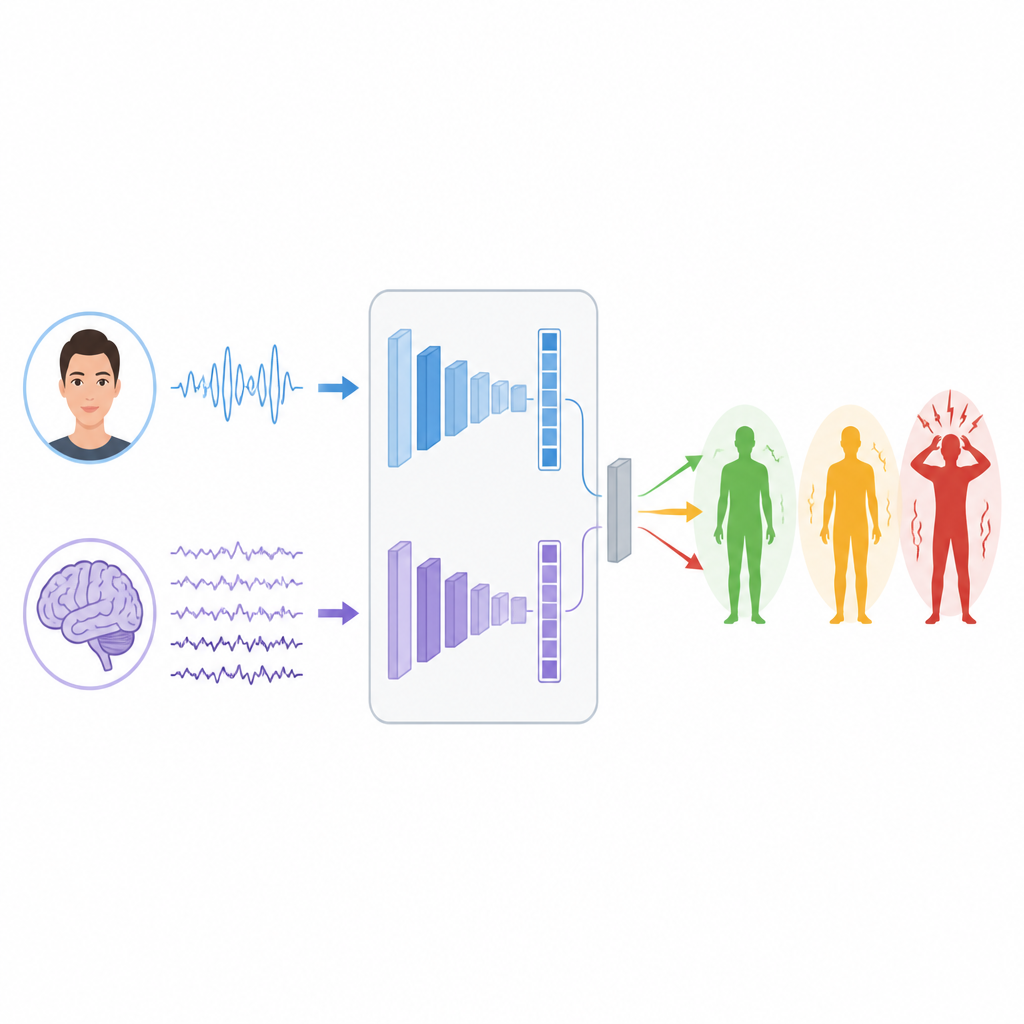
Maschinen das Lesen von Signalen beibringen
Um Muster in diesen Signalen zu lernen, bauen die Forschenden zwei separate Deep-Learning-Zweige. Für EEG verwenden sie eine Netzwerkart namens LSTM, die gut darin ist, wie sich Informationen über die Zeit verändern zu verfolgen, sodass sie Rhythmen und Schübe in Gehirnwellen folgen kann, die mit Stress zusammenhängen. Für Gesichtsbilder kombinieren sie einen Vision Transformer, der dem gesamten Bild Aufmerksamkeit schenkt, mit einem klassischen Faltungsnetzwerk, das sich auf lokale Details wie Muskelanspannung um Augen oder Mund konzentriert. Jeder Zweig transformiert seine Rohdaten in einen kompakten Satz von Merkmalen, die zusammenfassen, was er über mögliche Stressniveaus gelernt hat.
Gehirn und Gesicht zusammenführen
Die zentrale Frage ist, wie diese beiden Perspektiven zusammengeführt werden können, wenn sie von völlig unterschiedlichen Personen und Experimenten stammen. Die Autorinnen und Autoren testen drei Fusionsstrategien. Bei der Early Fusion verbinden sie einfach die Merkmalssätze von Gehirn und Gesicht, bevor sie sie einem Klassifikator übergeben. Bei der Late Fusion gibt jeder Zweig eine eigene Einschätzung ab und das System bildet den Endwert durch Mittelung oder Abstimmung. Bei der Stacked Fusion lernt ein Modell der zweiten Ebene, wie die beiden Einschätzungen zu kombinieren sind, und erkennt, wann einem Signal mehr Vertrauen geschenkt werden sollte. Es werden sorgfältige Maßnahmen ergriffen, um Trainings- und Testdaten getrennt zu halten, damit die Ergebnisse ehrlich und vergleichbar bleiben.
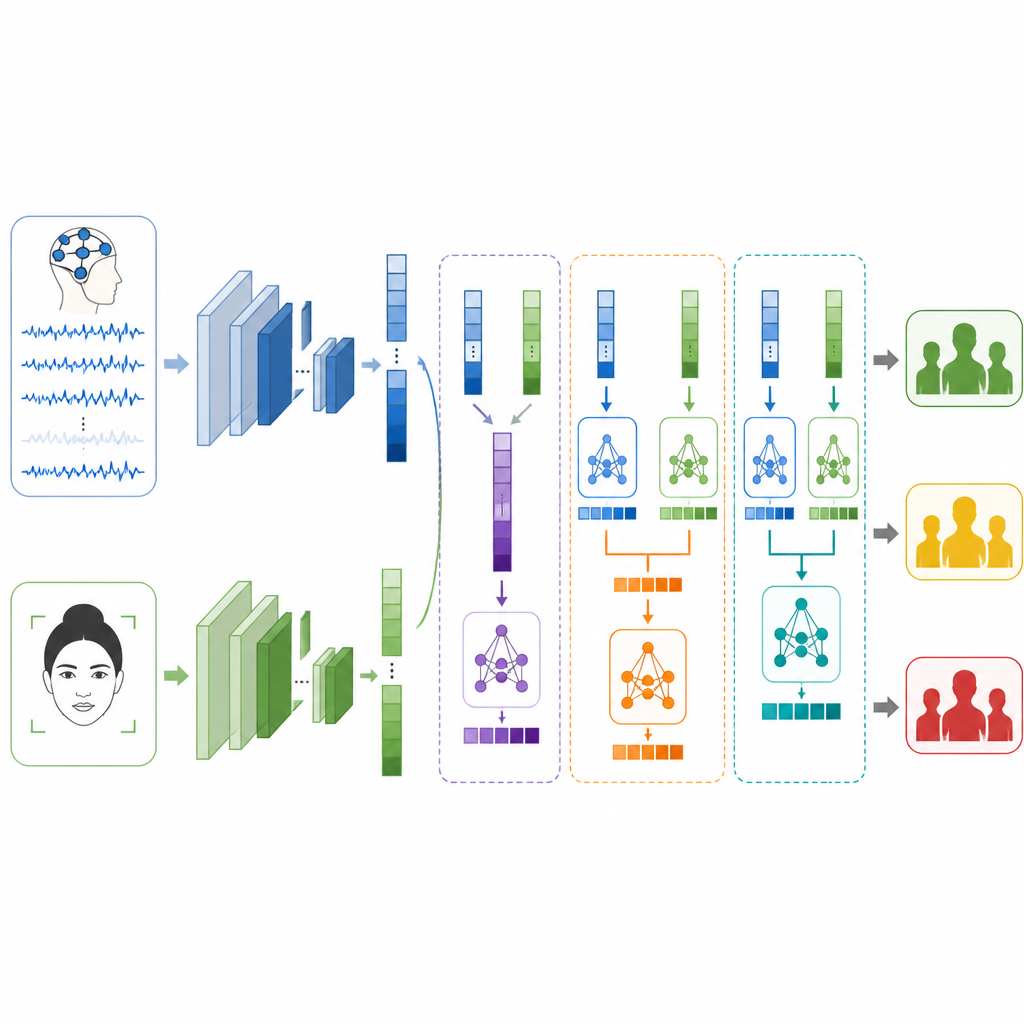
Was das System kann und was nicht
Alleinstehend klassifiziert das Gesichtsmodell Stressniveaus in etwa vier von fünf Fällen korrekt, während das Gehirnmodell etwas besser als drei von fünf liegt. Bei Fusion verbessert sich die Leistung durchgängig. Early Fusion übertrifft bereits beide Einzelquellen, doch Late Fusion schneidet besser ab, was darauf hindeutet, dass Spezialisierung der Zweige hilfreich ist. Die Stacked Fusion erzielt die besten Ergebnisse und ordnet das Stressniveau in mehr als neun von zehn Testbeispielen korrekt zu; zudem erzielt sie hohe Werte bei Precision, Recall und F1. Die Autorinnen und Autoren betonen jedoch, dass ihre Labels lediglich Stellvertreter sind, basierend auf Emotion und Arousal und nicht auf klinischen Diagnosen, und dass EEG- und Gesichtsdaten von unterschiedlichen Teilnehmenden stammen, was die direkte Abbildung von realem Stress einschränkt.
Was das für den Alltag bedeutet
Vereinfacht zeigt diese Forschung, dass ein Computer Menschen zuverlässiger in niedrige, mittlere und hohe Stressgruppen einordnen kann, wenn er sowohl aus Gehirnaktivität als auch aus Gesichtsausdrücken lernt, statt nur aus einer Quelle — selbst wenn diese Daten getrennt erhoben wurden. Das Framework liefert ein Rezept für den Aufbau künftiger Systeme, die steigenden Stress in Büros, im Gesundheitswesen oder in interaktiven Geräten erkennen könnten, ohne perfekt synchronisierte Sensoren zu verlangen. Bevor solche Werkzeuge persönliche Gesundheitsentscheidungen unterstützen können, müssen sie jedoch an neuen Daten mit echten Stressmessungen und synchronisierten Aufnahmen getestet werden; diese Studie legt jedoch eine wichtige technische Grundlage.
Zitation: Pechetti, S., Chennu, L., Chintakunta, V. et al. Cross-domain multimodal learning for stress-level prediction: a hybrid deep learning framework integrating independent EEG and facial expression datasets. Sci Rep 16, 15303 (2026). https://doi.org/10.1038/s41598-026-41250-7
Schlüsselwörter: Stresserkennung, EEG-Signale, Gesichtsausdrücke, multimodales Lernen, Deep Learning