Clear Sky Science · ar
التعلّم متعدد الأنماط عبر نطاقات مختلفة لتوقُّع مستوى التوتر: إطار عمل هجين للتعلّم العميق يدمج مجموعات بيانات EEG وتعبيرات الوجه مستقلة
لماذا متابعة التوتر مهمة
يشعر معظم الناس بدخول التوتر لحياتهم اليومية، ومع ذلك يصعب قياسه بطريقة واضحة وموضوعية. تستكشف هذه الدراسة كيفية قراءة الحواسيب لإشارات كل من الدماغ والوجه لفرز مستوى توتر الشخص إلى منخفض أو متوسط أو عالٍ. من خلال الجمع بين ما يحدث داخل الرأس وما يظهر على الوجه، يهدف الباحثون إلى تجاوز فحوصات المزاج البسيطة وابتكار أدوات قد تدعم في النهاية الرفاهية في العمل والمنزل والأجهزة الرقمية.
نافذتان على التوتر
تركز الدراسة على إشارتين مختلفتين تتعلّقان بالتوتر. الأولى هي النشاط الكهربائي في الدماغ، الملتقط عبر EEG، والذي يعكس ردود فعل داخلية لا يستطيع الآخرون رؤيتها. والثانية هي تعابير الوجه، التي تكشف عن علامات خارجية مثل التوتر أو القلق أو الهدوء. بدلاً من جمع بيانات جديدة من نفس المشاركين، تعيد الفِرق استخدام مجموعتين عامتين شائعتين: DEAP لتسجيلات EEG وFER2013 لصور الوجوه. لا تحتوي أي من المجموعتين على تسميات بمقاييس طبية للتوتر، لذلك يحدد الفريق بعناية ثلاث نطاقات للتوتر بناءً على شدة الاستثارة الدماغية والعواطف الظاهرة على الوجه. كما يختبرون مدى حساسية نتائجهم للتغيرات الصغيرة في اختيار هذه التسميات.
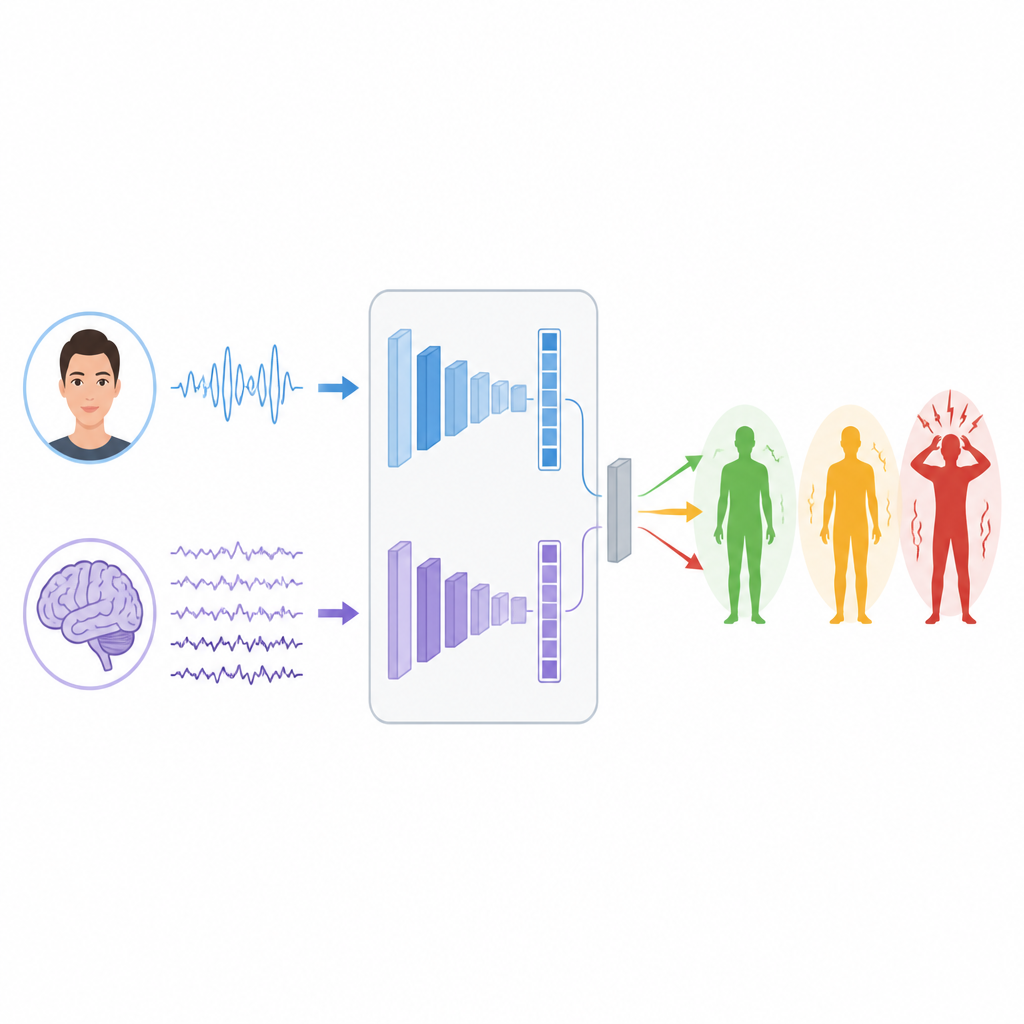
تدريب الآلات على قراءة الإشارات
لتعلّم الأنماط في هذه الإشارات، يبني الباحثون فرعين منفصلين للتعلّم العميق. بالنسبة لـ EEG، يستخدمون نوعاً من الشبكات يُدعى LSTM، وهو مناسب لتتبع كيفية تغيّر المعلومات عبر الزمن، ما يساعده على متابعة الإيقاعات والتفجّرات في موجات الدماغ التي قد ترتبط بالتوتر. بالنسبة للوجوه، يجمعون بين محول بصري (Vision Transformer) الذي يولي اهتماماً للصورة ككل، وشبكة تلافيفية كلاسيكية تركّز على التفاصيل المحلية مثل تشدُّد العضلات حول العين أو الفم. يحوّل كل فرع مدخله الخام إلى مجموعة مدمجة من الميزات التي تلخّص ما تعلّمه عن مستويات التوتر المحتملة.
دمج الدماغ والوجه
السؤال الرئيسي هو كيفية دمج هذين المشهدين عندما يأتيان من أشخاص وتجارب مختلفة تماماً. يختبر المؤلفون ثلاث استراتيجيات للدمج. في الدمج المبكر، ينضمون ببساطة إلى قوائم الميزات من الدماغ والوجه قبل تمريرها إلى المصنّف. في الدمج المتأخر، يقدم كل فرع توقعاته الخاصة ويُجمع النظام الإجابة النهائية بالمتوسط أو بالتصويت. في الدمج المكدّس، يتعلّم نموذج من المستوى الثاني كيفية دمج مجموعتي التوقّعات، مكتشفاً متى يثق في إشارة أكثر من الأخرى. تُتَّخذ خطوات حذرة للحفاظ على فصل بيانات التدريب والاختبار حتى تظل النتائج أمينة وقابلة للمقارنة.
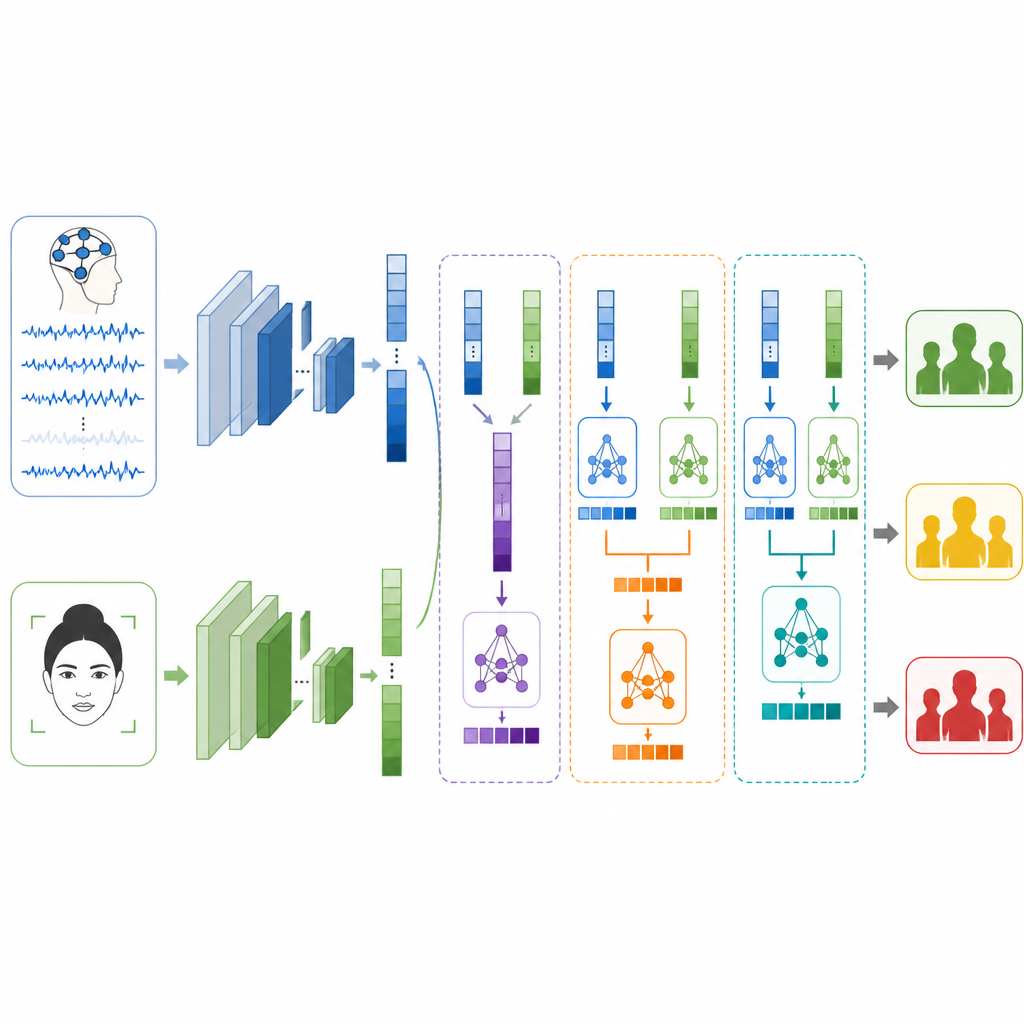
ما الذي يستطيع النظام فعله وما الذي لا يستطيع
بمفردها، يصنّف نموذج الوجه مستويات التوتر بدقة تقارب أربع حالات من كل خمس، بينما يقدّم نموذج الدماغ أداءً أفضل قليلاً من ثلاث حالات من كل خمس. عند الدمج، يتحسّن الأداء عبر اللوحة. يتفوق الدمج المبكر بالفعل على كل مصدر منفرد، لكن الدمج المتأخر يحقق أداءً أفضل، ما يشير إلى أن ترك كل فرع يتخصص مفيد. تُعطي طريقة الدمج المكدّس أفضل أداء على الإطلاق، حيث تُعيّن مستوى التوتر بشكل صحيح في أكثر من تسع حالات من كل عشر أمثلة اختبار وتحصل على درجات عالية في مقاييس الدقة والاسترجاع وF1. ومع ذلك، يؤكد المؤلفون أن تسمياتهم ليست تشخيصات طبية بل تمثيلات مبنية على العاطفة والاستثارة، وأن بيانات EEG والوجه مأخوذة من متطوعين مختلفين، مما يحد من مدى انعكاس هذه الطريقة للتوتر في الحياة الواقعية.
ما الذي يعنيه هذا للحياة اليومية
بعبارات بسيطة، تُظهر هذه الدراسة أن الحاسوب يمكنه فرز الأشخاص إلى مجموعات توتُّر منخفضة ومتوسطة وعالية بشكل أكثر موثوقية عندما يتعلّم من كل من نشاط الدماغ وتعبيرات الوجه بدلاً من أي منهما بمفرده، حتى عندما جمعت مصادر البيانات تلك بشكل منفصل. يقدم الإطار وصفة لبناء أنظمة مستقبلية قد تراقب ارتفاع التوتر في المكاتب أو الرعاية الصحية أو الأجهزة التفاعلية دون اشتراط أجهزة حسّاسَة متزامنة تماماً. قبل أن تتمكن مثل هذه الأدوات من توجيه قرارات صحية شخصية، سيكون من الضروري اختبارها على بيانات جديدة تحمل قياسات حقيقية للتوتر وتسجيلات متطابقة، لكن هذه الدراسة تؤسس لقاعدة فنية مهمة.
الاستشهاد: Pechetti, S., Chennu, L., Chintakunta, V. et al. Cross-domain multimodal learning for stress-level prediction: a hybrid deep learning framework integrating independent EEG and facial expression datasets. Sci Rep 16, 15303 (2026). https://doi.org/10.1038/s41598-026-41250-7
الكلمات المفتاحية: كشف التوتر, إشارات EEG, تعبيرات الوجه, التعلّم متعدد الأنماط, التعلّم العميق