Clear Sky Science · fr
Apprentissage multimodal inter-domaines pour la prédiction du niveau de stress : un cadre hybride d’apprentissage profond intégrant des jeux de données EEG et d’expressions faciales indépendants
Pourquoi le suivi du stress est important
La plupart des gens ressentent le stress s’immiscer dans leur quotidien, mais il est difficile à mesurer de manière claire et objective. Cette étude explore comment des ordinateurs peuvent lire des signaux à la fois du cerveau et du visage pour classer le niveau de stress d’une personne en faible, modéré ou élevé. En combinant ce qui se passe à l’intérieur de la tête et ce qui se manifeste sur le visage, les chercheurs visent à aller au‑delà des simples auto‑évaluations d’humeur et à créer des outils susceptibles, à terme, de soutenir le bien‑être au travail, à la maison et dans les appareils numériques.
Deux fenêtres sur le stress
Le travail se concentre sur deux signaux très différents liés au stress. Le premier est l’activité électrique du cerveau, enregistrée par EEG, qui reflète des réactions internes invisibles aux autres. Le second est l’expression faciale, qui révèle des signes externes comme la tension, l’inquiétude ou le calme. Plutôt que de collecter de nouvelles données auprès des mêmes volontaires, les auteurs réutilisent deux bases publiques populaires : DEAP pour les enregistrements EEG et FER2013 pour les images faciales. Aucun des deux ensembles n’est étiqueté avec des scores médicaux de stress, aussi l’équipe définit‑elle soigneusement trois bandes de stress sur la base de l’intensité de l’éveil cérébral et des émotions visibles sur le visage. Ils testent également la sensibilité de leurs résultats à de petites variations dans ces choix d’étiquetage.
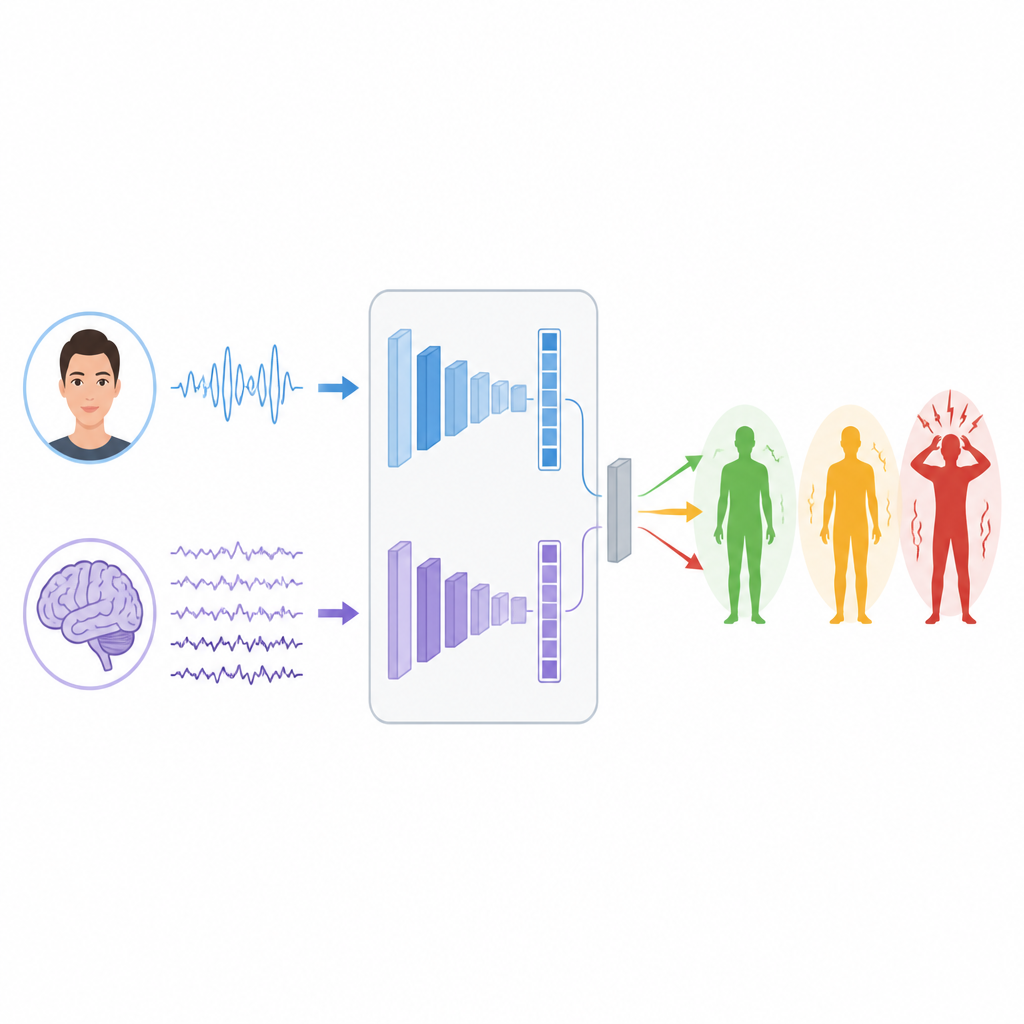
Apprendre aux machines à lire les signaux
Pour apprendre les motifs présents dans ces signaux, les chercheurs construisent deux branches d’apprentissage profond séparées. Pour l’EEG, ils utilisent un type de réseau appelé LSTM, adapté au suivi des évolutions temporelles, ce qui aide à suivre les rythmes et les rafales des ondes cérébrales qui peuvent être liées au stress. Pour les visages, ils combinent un Vision Transformer, qui porte attention à l’image dans son ensemble, avec un réseau convolutionnel classique qui se concentre sur des détails locaux comme la contraction musculaire autour des yeux ou de la bouche. Chaque branche transforme son entrée brute en un jeu de caractéristiques compactes qui résument ce qu’elle a appris sur les niveaux de stress possibles.
Rassembler cerveau et visage
La question clé est de savoir comment fusionner ces deux perspectives lorsqu’elles proviennent de personnes et d’expériences totalement différentes. Les auteurs testent trois stratégies de fusion. En fusion précoce (early fusion), ils joignent simplement les listes de caractéristiques issue du cerveau et du visage avant de les transmettre à un classificateur. En fusion tardive (late fusion), chaque branche émet sa propre estimation et le système moyenne ou vote pour la réponse finale. En fusion empilée (stacked fusion), un modèle de second niveau apprend à combiner les deux jeux d’estimations, découvrant quand faire davantage confiance à un signal plutôt qu’à l’autre. Des précautions sont prises pour garder les données d’entraînement et de test séparées afin que les résultats restent honnêtes et comparables.
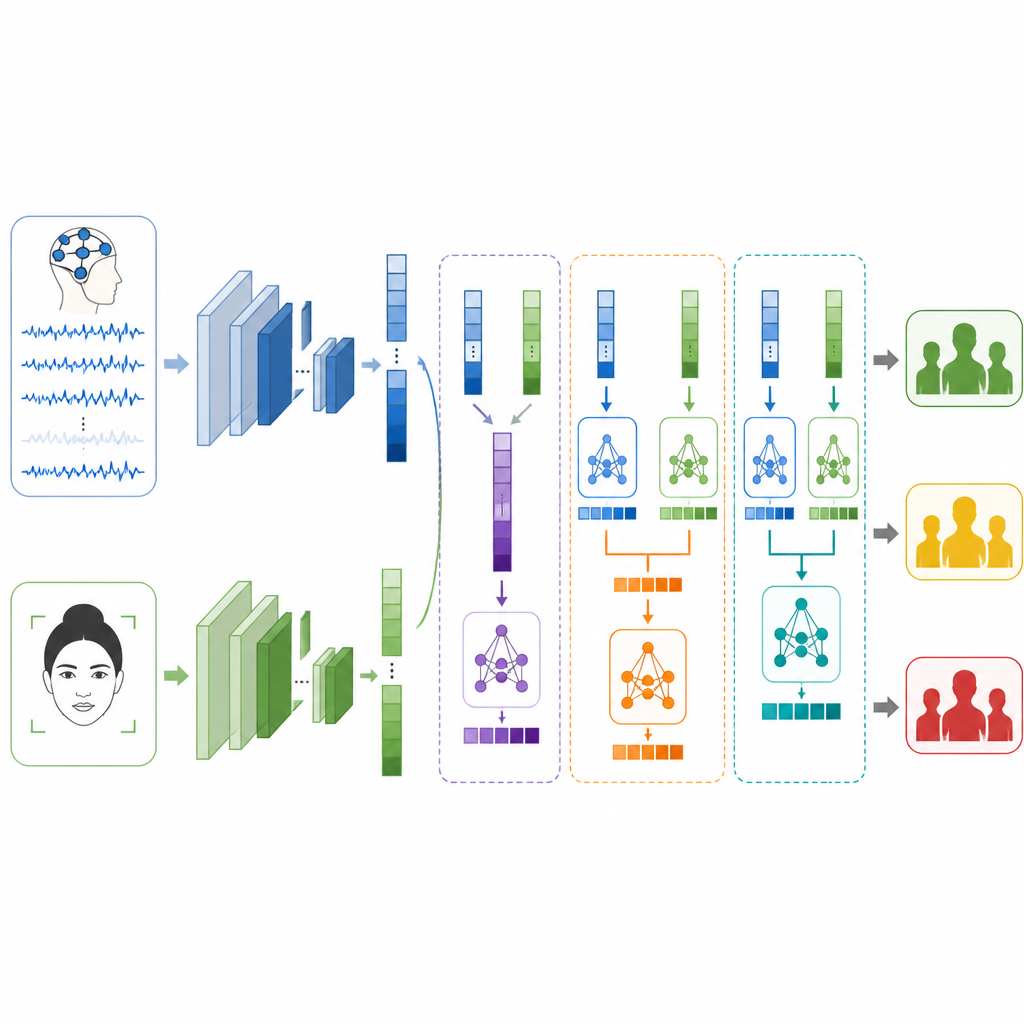
Ce que le système peut et ne peut pas faire
Pris isolément, le modèle facial classe les niveaux de stress avec environ quatre cas corrects sur cinq, tandis que le modèle cérébral atteint un peu plus de trois cas corrects sur cinq. Une fois fusionnés, les performances s’améliorent globalement. La fusion précoce dépasse déjà les deux sources individuelles, mais la fusion tardive fait mieux, ce qui suggère que laisser chaque branche se spécialiser est bénéfique. La méthode de fusion empilée obtient les meilleurs résultats, assignant correctement le niveau de stress dans plus de neuf cas sur dix et obtenant de bons scores en précision, rappel et F1. Les auteurs soulignent cependant que leurs étiquettes ne sont que des substitutions basées sur l’émotion et l’excitation, et non des diagnostics cliniques, et que les données EEG et faciales proviennent de volontaires différents, ce qui limite la façon dont la méthode reflète directement le stress dans la vie réelle.
Ce que cela signifie pour la vie quotidienne
En termes simples, cette recherche montre qu’un ordinateur peut classer de manière plus fiable les personnes en groupes de stress faible, modéré et élevé lorsqu’il apprend à la fois à partir de l’activité cérébrale et des expressions faciales plutôt qu’à partir de l’un ou l’autre seul, même lorsque ces sources de données ont été collectées séparément. Le cadre fournit une recette pour construire des systèmes futurs capables de détecter une montée de stress dans les bureaux, les soins de santé ou les dispositifs interactifs sans exiger des capteurs parfaitement synchronisés. Avant que de tels outils puissent orienter des décisions de santé personnelles, ils devront être testés sur de nouvelles données avec de véritables mesures de stress et des enregistrements appariés, mais cette étude pose une base technique importante.
Citation: Pechetti, S., Chennu, L., Chintakunta, V. et al. Cross-domain multimodal learning for stress-level prediction: a hybrid deep learning framework integrating independent EEG and facial expression datasets. Sci Rep 16, 15303 (2026). https://doi.org/10.1038/s41598-026-41250-7
Mots-clés: détection du stress, signaux EEG, expressions faciales, apprentissage multimodal, apprentissage profond