Clear Sky Science · nl
Multidomein multimodale leerbenadering voor stressniveaus voorspellen: een hybride deep learning-kader dat onafhankelijke EEG- en gezichtsuitdrukkingsdatasets integreert
Waarom stressmonitoring ertoe doet
De meeste mensen ervaren dat stress hun dagelijks leven binnensluipt, maar het is moeilijk om dat op een heldere, objectieve manier te meten. Deze studie onderzoekt hoe computers signalen uit zowel de hersenen als het gezicht kunnen lezen om iemands stressniveau in laag, matig of hoog in te delen. Door te combineren wat zich in het hoofd afspeelt met wat op het gezicht te zien is, willen de onderzoekers verder gaan dan eenvoudige stemmingchecks en tools ontwikkelen die uiteindelijk welzijn op het werk, thuis en in digitale apparaten kunnen ondersteunen.
Twee vensters op stress
Het werk richt zich op twee heel verschillende signalen die met stress samenhangen. Het ene is elektrische activiteit in de hersenen, vastgelegd als EEG, wat innerlijke reacties weerspiegelt die anderen niet kunnen zien. Het andere is gezichtsuitdrukking, die uiterlijke tekenen zoals spanning, bezorgdheid of kalmte onthult. In plaats van nieuwe data van dezelfde proefpersonen te verzamelen, hergebruiken de auteurs twee bekende openbare datasets: DEAP voor EEG-opnames en FER2013 voor gezichtsbeelden. Geen van beide sets is gelabeld met medische stressscores, dus definieert het team zorgvuldig drie stresscategorieën op basis van hoe intens de hersenarousal is en welke emoties op het gezicht te zien zijn. Ze testen ook hoe gevoelig hun resultaten zijn voor kleine wijzigingen in deze labelkeuzes.
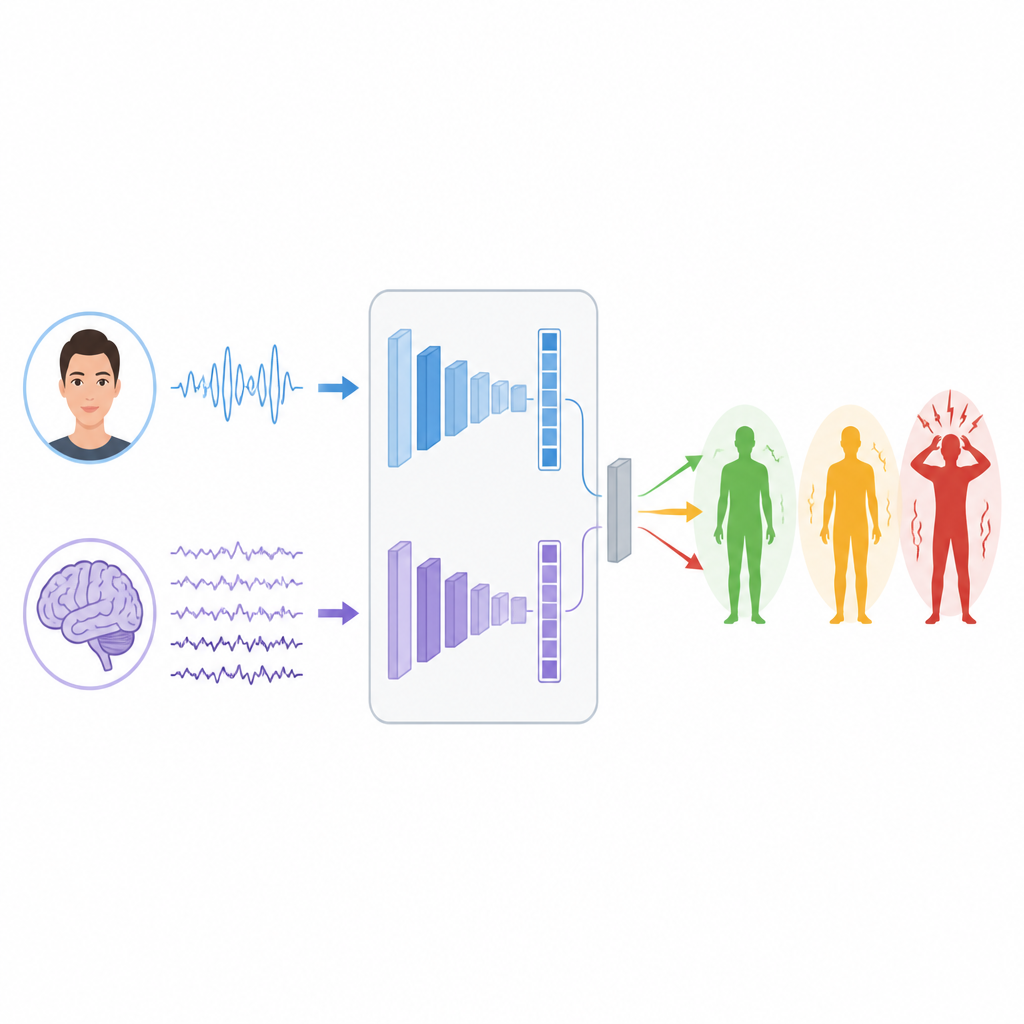
Machines leren signalen te lezen
Om patronen in deze signalen te leren, bouwen de onderzoekers twee afzonderlijke deep learning-takken. Voor EEG gebruiken ze een type netwerk genaamd LSTM dat goed is in het volgen van hoe informatie in de tijd verandert, waardoor het ritmes en uitbarstingen in hersengolven kan volgen die met stress samenhangen. Voor gezichten combineren ze een Vision Transformer, die aandacht besteedt aan het hele beeld, met een klassiek convolutioneel netwerk dat zich richt op lokale details zoals het aanspannen van spieren rond ogen of mond. Elke tak zet zijn ruwe input om in een compacte set kenmerken die samenvatten wat het heeft geleerd over mogelijke stressniveaus.
Hersenen en gezicht samenbrengen
De kernvraag is hoe je deze twee gezichtspunten samenvoegt als ze afkomstig zijn van totaal verschillende mensen en experimenten. De auteurs testen drie fusiestrategieën. Bij early fusion voegen ze eenvoudigweg de kenmerklijsten van brein en gezicht samen voordat ze een classifier voeden. Bij late fusion doet elke tak zijn eigen voorspelling en gemiddeld of stemt het systeem over het eindantwoord. Bij stacked fusion leert een model op tweede niveau hoe de twee voorspellingssets te combineren, zodat het kan ontdekken wanneer het het ene signaal meer moet vertrouwen dan het andere. Zorgvuldige stappen worden genomen om trainings- en testgegevens gescheiden te houden zodat de resultaten eerlijk en vergelijkbaar blijven.
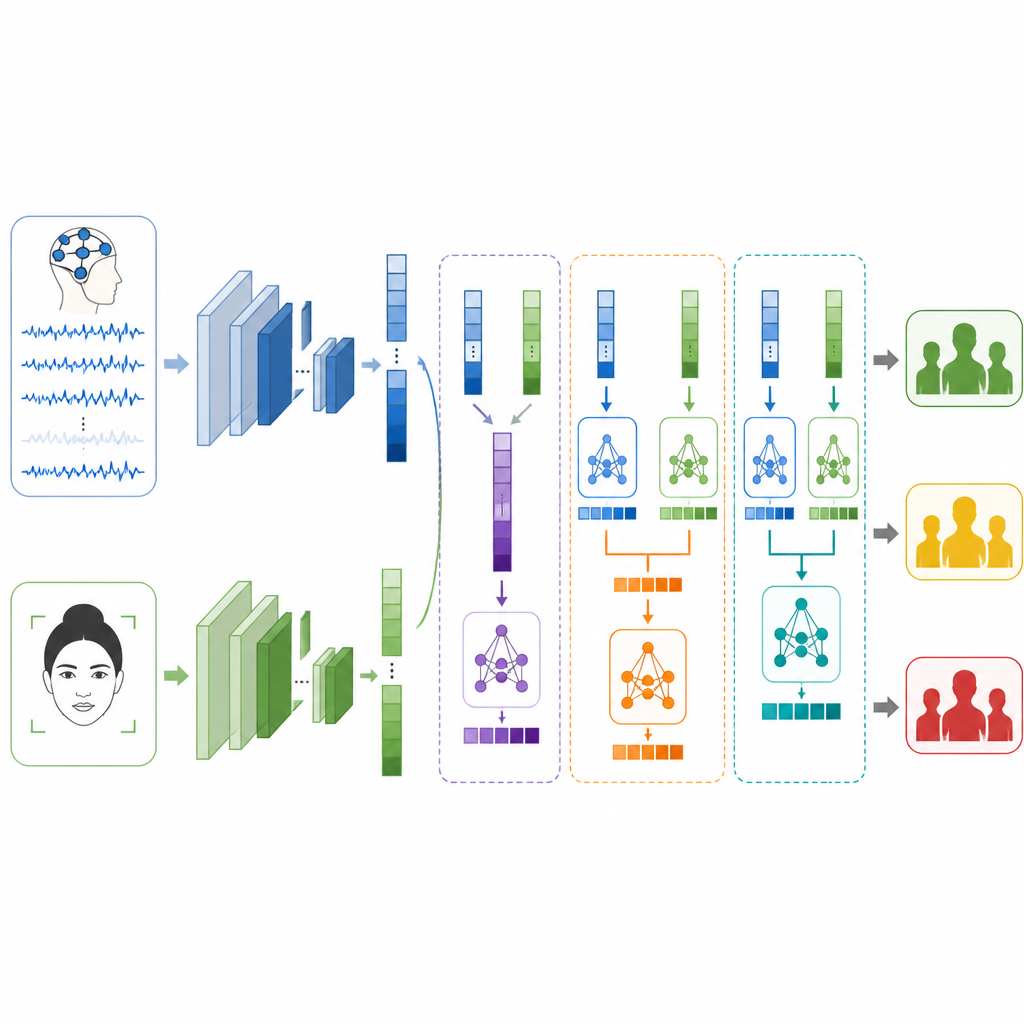
Wat het systeem wel en niet kan
Op zichzelf classificeert het gezichtmodel stressniveaus in ongeveer vier van de vijf gevallen correct, terwijl het breinmodel iets meer dan drie van de vijf goed doet. Wanneer ze worden gefuseerd, verbetert de prestatie over de hele linie. Early fusion overtreft al beide afzonderlijke bronnen, maar late fusion doet het beter, wat suggereert dat het nuttig is om elke tak te laten specialiseren. De stacked fusion-methode presteert het best van allemaal: die wijst het stressniveau correct toe in meer dan negen van de tien testvoorbeelden en scoort hoog op precisie, recall en F1-maten. Toch benadrukken de auteurs dat hun labels slechts proxy's zijn op basis van emotie en arousal, geen klinische diagnoses, en dat de EEG- en gezichtsgegevens van verschillende vrijwilligers komen, wat de directe toepasbaarheid op echte stress beperkt.
Wat dit betekent voor het dagelijks leven
In eenvoudige bewoordingen toont dit onderzoek aan dat een computer mensen betrouwbaarder in lage, matige en hoge stressgroepen kan indelen wanneer hij leert van zowel hersenactiviteit als gezichtsuitdrukkingen in plaats van van één bron alleen, zelfs wanneer die databronnen apart zijn verzameld. Het kader biedt een recept voor het bouwen van toekomstige systemen die kunnen waarschuwen voor oplopende stress op kantoren, in de gezondheidszorg of in interactieve apparaten zonder perfect gesynchroniseerde sensoren te vereisen. Voordat zulke tools persoonlijke gezondheidsbeslissingen kunnen ondersteunen, moeten ze echter worden getest op nieuwe data met echte stressmetingen en gekoppelde opnames, maar deze studie legt een belangrijke technische basis.
Bronvermelding: Pechetti, S., Chennu, L., Chintakunta, V. et al. Cross-domain multimodal learning for stress-level prediction: a hybrid deep learning framework integrating independent EEG and facial expression datasets. Sci Rep 16, 15303 (2026). https://doi.org/10.1038/s41598-026-41250-7
Trefwoorden: stressdetectie, EEG-signalen, gezichtsuitdrukkingen, multimodaal leren, deep learning