Clear Sky Science · en
Cross-domain multimodal learning for stress-level prediction: a hybrid deep learning framework integrating independent EEG and facial expression datasets
Why stress tracking matters
Most people feel stress creeping into their daily lives, yet it is hard to measure in a clear, objective way. This study explores how computers can read signals from both the brain and the face to sort a person’s stress level into low, moderate, or high. By combining what is happening inside the head with what shows on the face, the researchers aim to move beyond simple mood checks and create tools that could eventually support well being at work, at home, and in digital devices.
Two windows into stress
The work focuses on two very different signals that relate to stress. One is electrical activity in the brain, captured as EEG, which reflects inner reactions that other people cannot see. The other is facial expression, which reveals outward signs such as tension, worry, or calm. Instead of collecting new data from the same volunteers, the authors reuse two popular public collections: DEAP for EEG recordings and FER2013 for face images. Neither set is labeled with medical stress scores, so the team carefully defines three stress bands based on how intense the brain arousal is and which emotions are visible on the face. They also test how sensitive their results are to small changes in these label choices.
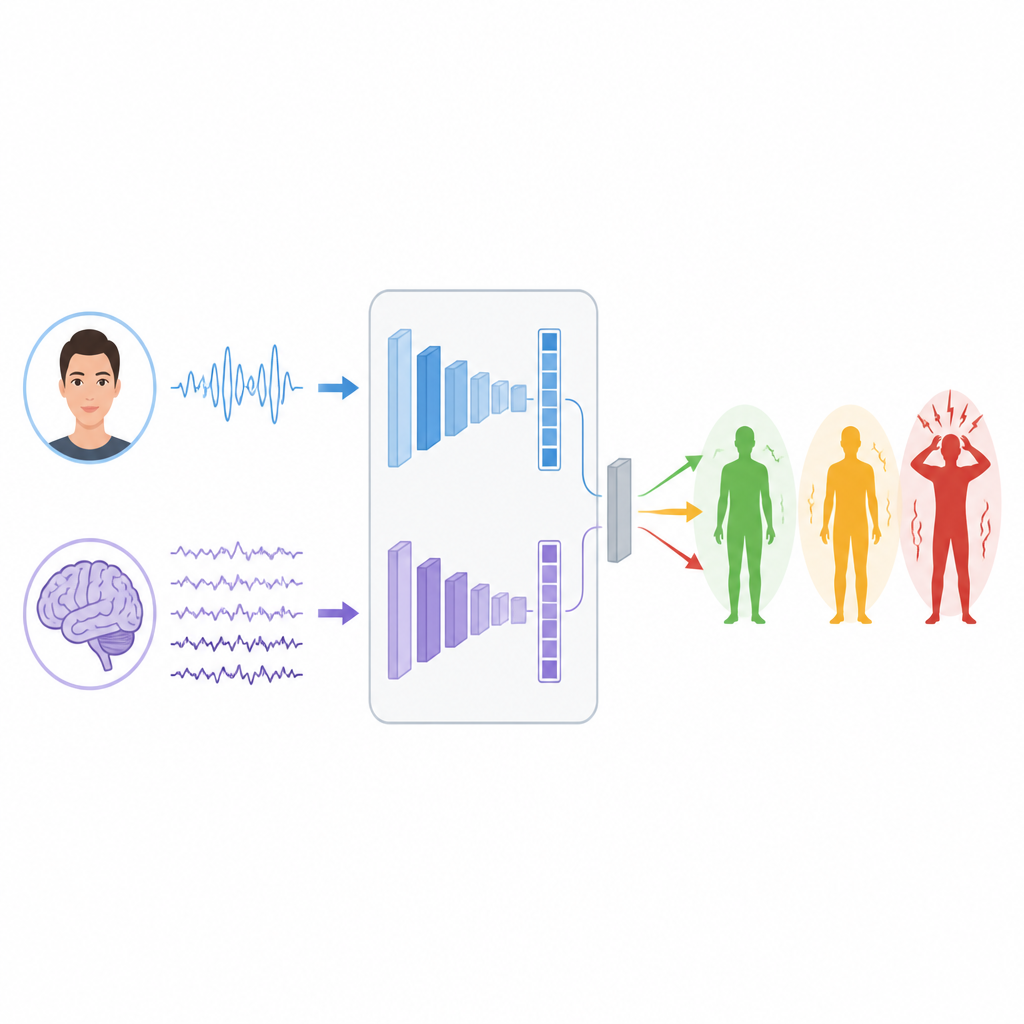
Teaching machines to read signals
To learn patterns in these signals, the researchers build two separate deep learning branches. For EEG, they use a type of network called LSTM that is good at tracking how information changes over time, helping it follow rhythms and bursts in brain waves that may relate to stress. For faces, they combine a Vision Transformer, which pays attention to the whole image, with a classic convolutional network that focuses on local details like muscle tightening around the eyes or mouth. Each branch turns its raw input into a compact set of features that summarize what it has learned about possible stress levels.
Bringing brain and face together
The key question is how to merge these two views when they come from entirely different people and experiments. The authors test three fusion strategies. In early fusion, they simply join the feature lists from brain and face before feeding them to a classifier. In late fusion, each branch makes its own guess and the system averages or votes on the final answer. In stacked fusion, a second-level model learns how to combine the two sets of guesses, discovering when to trust one signal more than the other. Careful steps are taken to keep training and testing data separate so the results stay honest and comparable.
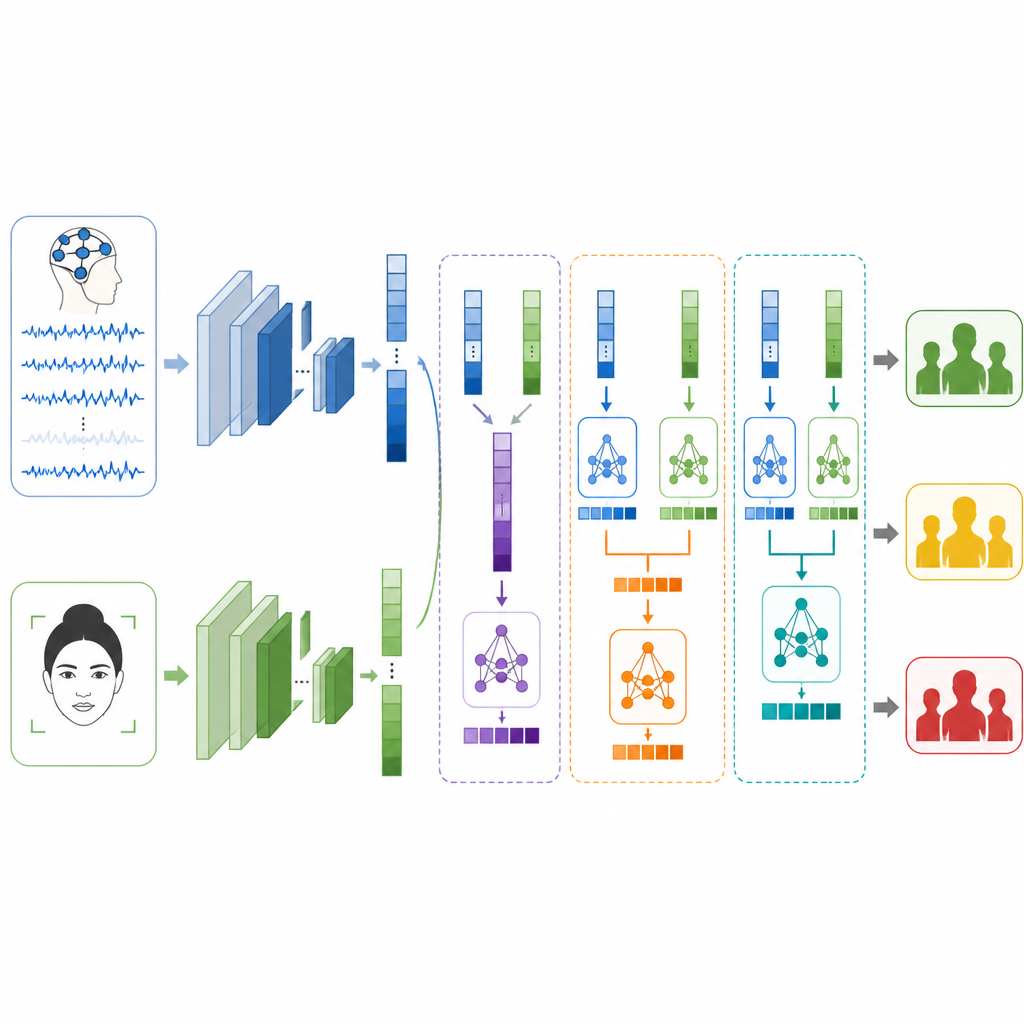
What the system can and cannot do
On their own, the face model classifies stress levels with about four out of five cases correct, while the brain model does a bit better than three out of five. When fused, performance improves across the board. Early fusion already beats both single sources, but late fusion does better, suggesting that letting each branch specialize is helpful. The stacked fusion method performs best of all, correctly assigning stress level in more than nine out of ten test examples and scoring highly on precision, recall, and F1 measures. Still, the authors stress that their labels are only stand ins based on emotion and arousal, not clinical diagnoses, and that the EEG and face data come from different volunteers, which limits how directly the method reflects real life stress.
What this means for everyday life
In simple terms, this research shows that a computer can more reliably sort people into low, moderate, and high stress groups when it learns from both brain activity and facial expressions rather than from either alone, even when those data sources were collected separately. The framework offers a recipe for building future systems that could watch for rising stress in offices, health care, or interactive devices without demanding perfectly synchronized sensors. Before such tools can guide personal health decisions, they will need to be tested on new data with true stress measurements and matched recordings, but this study lays an important technical foundation.
Citation: Pechetti, S., Chennu, L., Chintakunta, V. et al. Cross-domain multimodal learning for stress-level prediction: a hybrid deep learning framework integrating independent EEG and facial expression datasets. Sci Rep 16, 15303 (2026). https://doi.org/10.1038/s41598-026-41250-7
Keywords: stress detection, EEG signals, facial expressions, multimodal learning, deep learning