Clear Sky Science · es
Aprendizaje multimodal entre dominios para la predicción del nivel de estrés: un marco híbrido de aprendizaje profundo que integra conjuntos de datos independientes de EEG y expresiones faciales
Por qué importa el seguimiento del estrés
La mayoría de las personas siente que el estrés se infiltra en su vida diaria, pero resulta difícil medirlo de forma clara y objetiva. Este estudio explora cómo los ordenadores pueden leer señales tanto del cerebro como del rostro para clasificar el nivel de estrés de una persona en bajo, moderado o alto. Al combinar lo que sucede dentro de la cabeza con lo que se muestra en el rostro, los investigadores pretenden ir más allá de simples comprobaciones del estado de ánimo y crear herramientas que, en el futuro, puedan apoyar el bienestar en el trabajo, en el hogar y en dispositivos digitales.
Dos ventanas hacia el estrés
El trabajo se centra en dos señales muy diferentes relacionadas con el estrés. Una es la actividad eléctrica del cerebro, capturada como EEG, que refleja reacciones internas que otros no pueden ver. La otra es la expresión facial, que revela señales externas como tensión, preocupación o calma. En lugar de recopilar nuevos datos de los mismos voluntarios, los autores reutilizan dos colecciones públicas populares: DEAP para registros EEG y FER2013 para imágenes faciales. Ninguno de los conjuntos está etiquetado con puntuaciones médicas de estrés, por lo que el equipo define cuidadosamente tres bandas de estrés basadas en la intensidad de la activación cerebral y en las emociones visibles en el rostro. También evalúan la sensibilidad de sus resultados ante pequeños cambios en estas opciones de etiquetado.
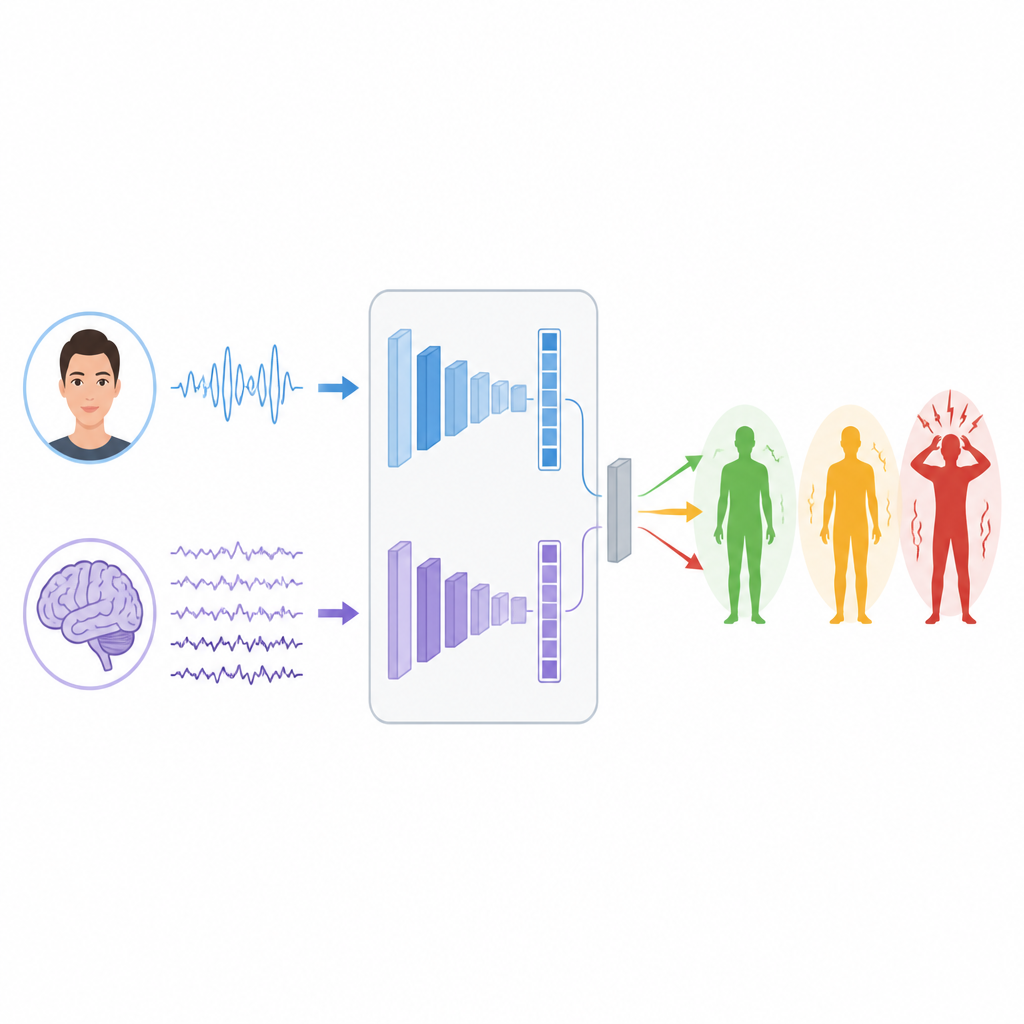
Enseñar a las máquinas a leer señales
Para aprender patrones en estas señales, los investigadores construyen dos ramas de aprendizaje profundo separadas. Para EEG usan un tipo de red llamada LSTM, adecuada para seguir cómo cambia la información en el tiempo, lo que ayuda a rastrear ritmos y ráfagas en las ondas cerebrales que pueden relacionarse con el estrés. Para las caras combinan un Vision Transformer, que presta atención a la imagen completa, con una red convolucional clásica que se centra en detalles locales como el tensado de músculos alrededor de los ojos o la boca. Cada rama convierte su entrada cruda en un conjunto compacto de características que resumen lo aprendido sobre los posibles niveles de estrés.
Unir cerebro y rostro
La pregunta clave es cómo fusionar estas dos visiones cuando provienen de personas y experimentos completamente distintos. Los autores prueban tres estrategias de fusión. En la fusión temprana, simplemente unen las listas de características de cerebro y rostro antes de pasarlas a un clasificador. En la fusión tardía, cada rama hace su propia predicción y el sistema promedia o vota para obtener la respuesta final. En la fusión apilada, un modelo de segundo nivel aprende a combinar los dos conjuntos de predicciones, descubriendo cuándo confiar más en una señal que en la otra. Se toman medidas cuidadosas para mantener separados los datos de entrenamiento y prueba, de modo que los resultados sean honestos y comparables.
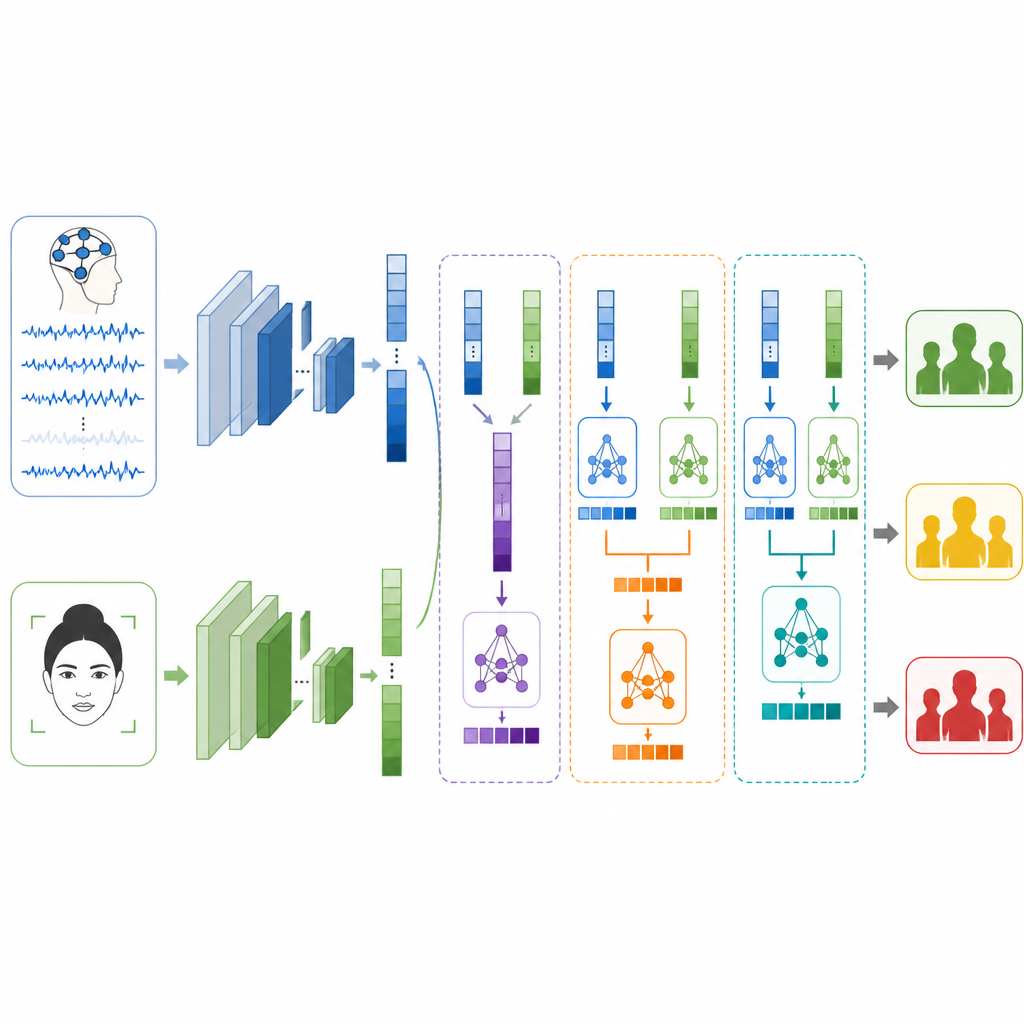
Lo que el sistema puede y no puede hacer
Por sí solo, el modelo de rostro clasifica niveles de estrés con alrededor de cuatro de cada cinco casos correctos, mientras que el modelo cerebral lo hace un poco mejor que tres de cada cinco. Al fusionarlos, el rendimiento mejora en todos los casos. La fusión temprana ya supera a ambas fuentes individuales, pero la fusión tardía funciona mejor, lo que sugiere que permitir que cada rama se especialice resulta beneficioso. El método de fusión apilada ofrece el mejor rendimiento de todos, asignando correctamente el nivel de estrés en más de nueve de cada diez ejemplos de prueba y obteniendo puntuaciones altas en precisión, recall y F1. Aun así, los autores subrayan que sus etiquetas son solo sustitutos basados en emoción y activación, no diagnósticos clínicos, y que los datos de EEG y faciales proceden de voluntarios diferentes, lo que limita cuánto refleja el método el estrés en la vida real.
Qué supone esto para la vida cotidiana
En términos sencillos, esta investigación muestra que un ordenador puede clasificar de forma más fiable a las personas en grupos de estrés bajo, moderado y alto cuando aprende tanto de la actividad cerebral como de las expresiones faciales, en lugar de hacerlo con solo una de las fuentes, incluso cuando esas fuentes se recopilaron por separado. El marco ofrece una receta para construir sistemas futuros que puedan detectar el aumento del estrés en oficinas, atención sanitaria o dispositivos interactivos sin exigir sensores perfectamente sincronizados. Antes de que tales herramientas puedan orientar decisiones de salud personales, deberán probarse con nuevos datos que incluyan mediciones reales de estrés y grabaciones emparejadas, pero este estudio sienta una importante base técnica.
Cita: Pechetti, S., Chennu, L., Chintakunta, V. et al. Cross-domain multimodal learning for stress-level prediction: a hybrid deep learning framework integrating independent EEG and facial expression datasets. Sci Rep 16, 15303 (2026). https://doi.org/10.1038/s41598-026-41250-7
Palabras clave: detección de estrés, señales EEG, expresiones faciales, aprendizaje multimodal, aprendizaje profundo