Clear Sky Science · it
Apprendimento multimodale cross-dominio per la previsione del livello di stress: un framework ibrido di deep learning che integra dataset indipendenti di EEG ed espressioni facciali
Perché il monitoraggio dello stress è importante
Molte persone percepiscono lo stress introdursi nella vita quotidiana, ma è difficile misurarlo in modo chiaro e oggettivo. Questo studio esplora come i computer possano leggere segnali sia dal cervello sia dal volto per classificare il livello di stress di una persona in basso, moderato o alto. Combinando ciò che avviene all’interno della testa con ciò che si manifesta sul viso, i ricercatori puntano ad andare oltre i semplici check dell’umore e a creare strumenti che potrebbero, in futuro, supportare il benessere sul lavoro, a casa e nei dispositivi digitali.
Due finestre sullo stress
Il lavoro si concentra su due segnali molto diversi ma connessi allo stress. Uno è l’attività elettrica del cervello, catturata come EEG, che riflette reazioni interiori non visibili agli altri. L’altro è l’espressione facciale, che rivela segnali esterni come tensione, preoccupazione o calma. Invece di raccogliere nuovi dati dagli stessi volontari, gli autori riutilizzano due collezioni pubbliche ampiamente usate: DEAP per le registrazioni EEG e FER2013 per le immagini del volto. Nessuno dei due dataset è etichettato con punteggi clinici di stress, quindi il team definisce con cura tre fasce di stress basate sull’intensità di attivazione cerebrale e sulle emozioni visibili sul volto. Testano inoltre quanto i risultati siano sensibili a piccole variazioni nella scelta di queste etichette.
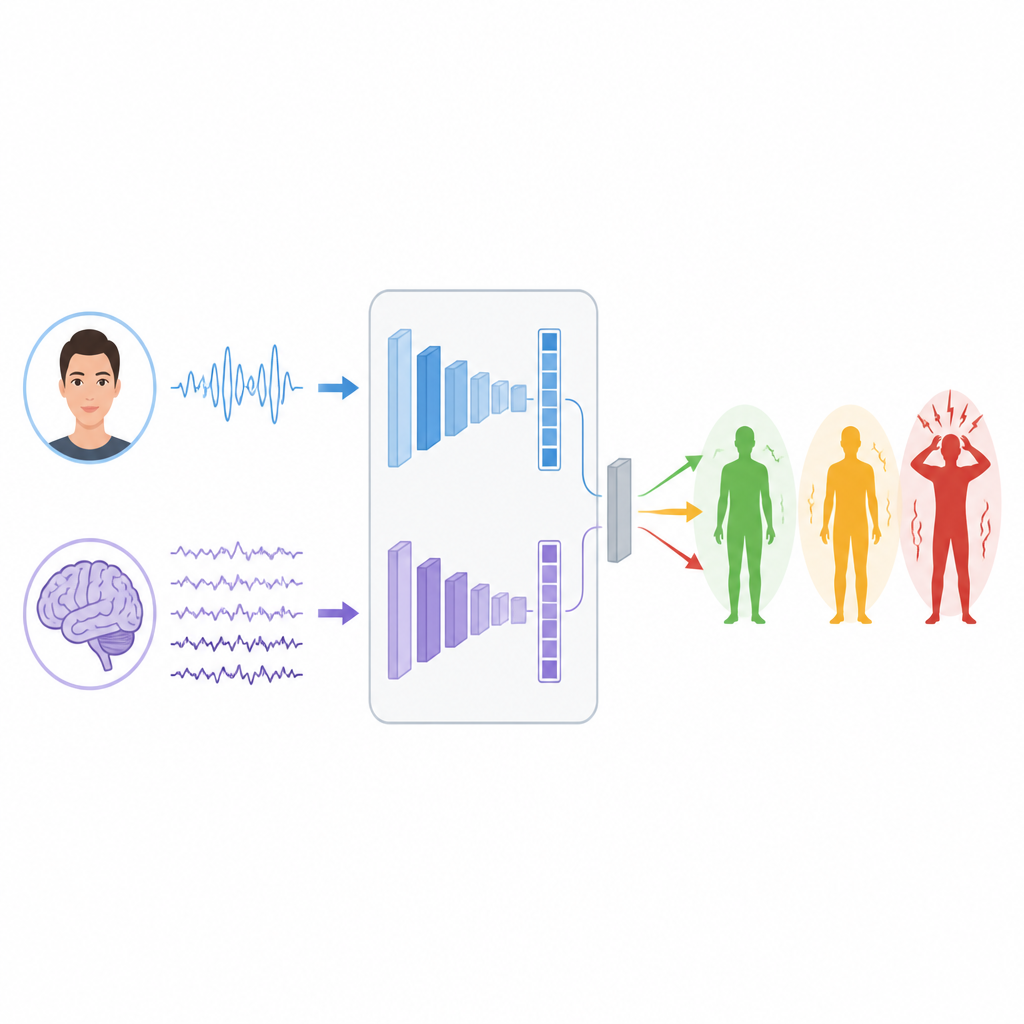
Insegnare alle macchine a leggere i segnali
Per apprendere i modelli in questi segnali, i ricercatori costruiscono due rami distinti di deep learning. Per l’EEG utilizzano un tipo di rete chiamata LSTM, adatta a seguire come l’informazione cambia nel tempo, aiutando a tracciare ritmi e picchi nelle onde cerebrali che possono essere correlati allo stress. Per i volti combinano un Vision Transformer, che presta attenzione all’intera immagine, con una rete convoluzionale classica che si concentra su dettagli locali come la tensione muscolare intorno agli occhi o alla bocca. Ogni ramo trasforma il proprio input grezzo in un insieme compatto di caratteristiche che riassumono ciò che ha appreso sui possibili livelli di stress.
Unire cervello e volto
La questione chiave è come fondere queste due prospettive quando provengono da persone ed esperimenti completamente diversi. Gli autori testano tre strategie di fusione. Nell’early fusion uniscono semplicemente le liste di caratteristiche di cervello e volto prima di inviarle a un classificatore. Nella late fusion ogni ramo fornisce una propria previsione e il sistema media o vota per la risposta finale. Nella stacked fusion, un modello di secondo livello impara come combinare i due insiemi di previsioni, scoprendo quando fidarsi di più di un segnale rispetto all’altro. Vengono adottate misure attente per mantenere separati i dati di addestramento e di test, in modo che i risultati rimangano onesti e comparabili.
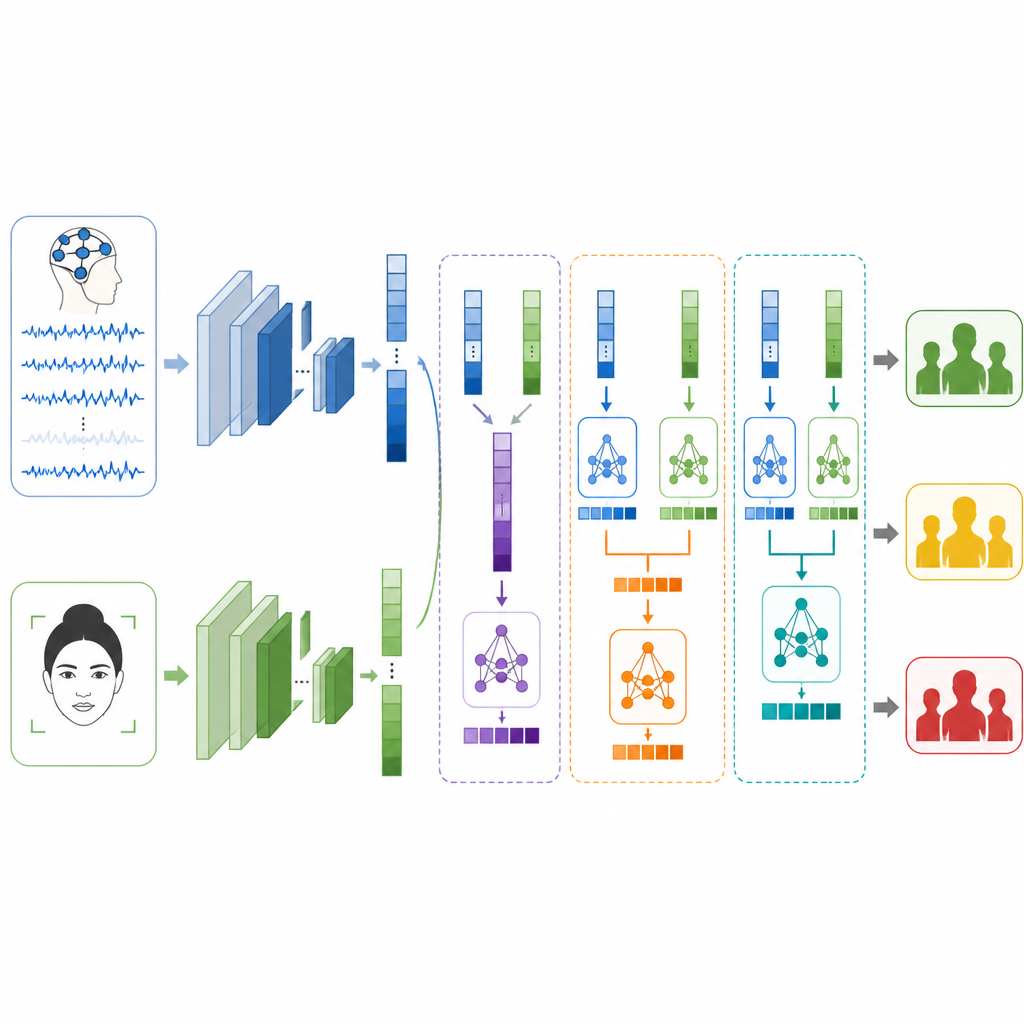
Cosa può e non può fare il sistema
Da soli, il modello sul volto classifica i livelli di stress con circa quattro casi su cinque corretti, mentre il modello cerebrale ottiene un risultato poco superiore a tre casi su cinque. Quando vengono fusi, le prestazioni migliorano in tutti i casi. L’early fusion supera già entrambe le singole sorgenti, ma la late fusion fa meglio, suggerendo che lasciare che ogni ramo si specializzi è utile. Il metodo di stacked fusion è il migliore di tutti, assegnando correttamente il livello di stress in più di nove casi su dieci nei test e ottenendo punteggi elevati in precisione, richiamo e F1. Tuttavia, gli autori sottolineano che le loro etichette sono solo surrogati basati su emozione e attivazione, non diagnosi cliniche, e che i dati EEG e del volto provengono da volontari diversi, il che limita quanto direttamente il metodo rifletta lo stress nella vita reale.
Cosa significa per la vita quotidiana
In termini semplici, questa ricerca mostra che un computer può classificare in modo più affidabile le persone in gruppi di stress basso, moderato e alto quando apprende sia dall’attività cerebrale sia dalle espressioni facciali piuttosto che da una sola fonte, anche quando queste sorgenti di dati sono state raccolte separatamente. Il framework offre una ricetta per costruire sistemi futuri che potrebbero monitorare l’aumento dello stress in uffici, strutture sanitarie o dispositivi interattivi senza richiedere sensori perfettamente sincronizzati. Prima che tali strumenti possano guidare decisioni sulla salute personale, dovranno essere testati su nuovi dati con misure di stress reali e registrazioni corrispondenti, ma questo studio pone una solida base tecnica.
Citazione: Pechetti, S., Chennu, L., Chintakunta, V. et al. Cross-domain multimodal learning for stress-level prediction: a hybrid deep learning framework integrating independent EEG and facial expression datasets. Sci Rep 16, 15303 (2026). https://doi.org/10.1038/s41598-026-41250-7
Parole chiave: rilevamento dello stress, segnali EEG, espressioni facciali, apprendimento multimodale, deep learning