Clear Sky Science · sv
En optimerad ensemble-ram för felupptäckt i maskiner i IoT-miljöer
Att förhindra att fabriksmaskiner går sönder
Moderna fabriker förlitar sig alltmer på nätverk av smarta sensorer för att hålla sina maskiner i gott skick. Ändå inträffar oväntade haverier även med all denna data, vilket kostar både tid och pengar. Denna studie undersöker ett nytt sätt att sålla bland strömmar av sensormätningar—såsom temperatur, vibration, hastighet och spänning—för att upptäcka tidiga varningstecken på problem i industrimaskiner som är uppkopplade via Internet of Things (IoT). Målet är enkelt men kraftfullt: upptäcka fel tidigare, mer tillförlitligt och med mindre beräkningsinsats så att stillestånd kan minskas dramatiskt.
Varför det är svårt att övervaka maskiner
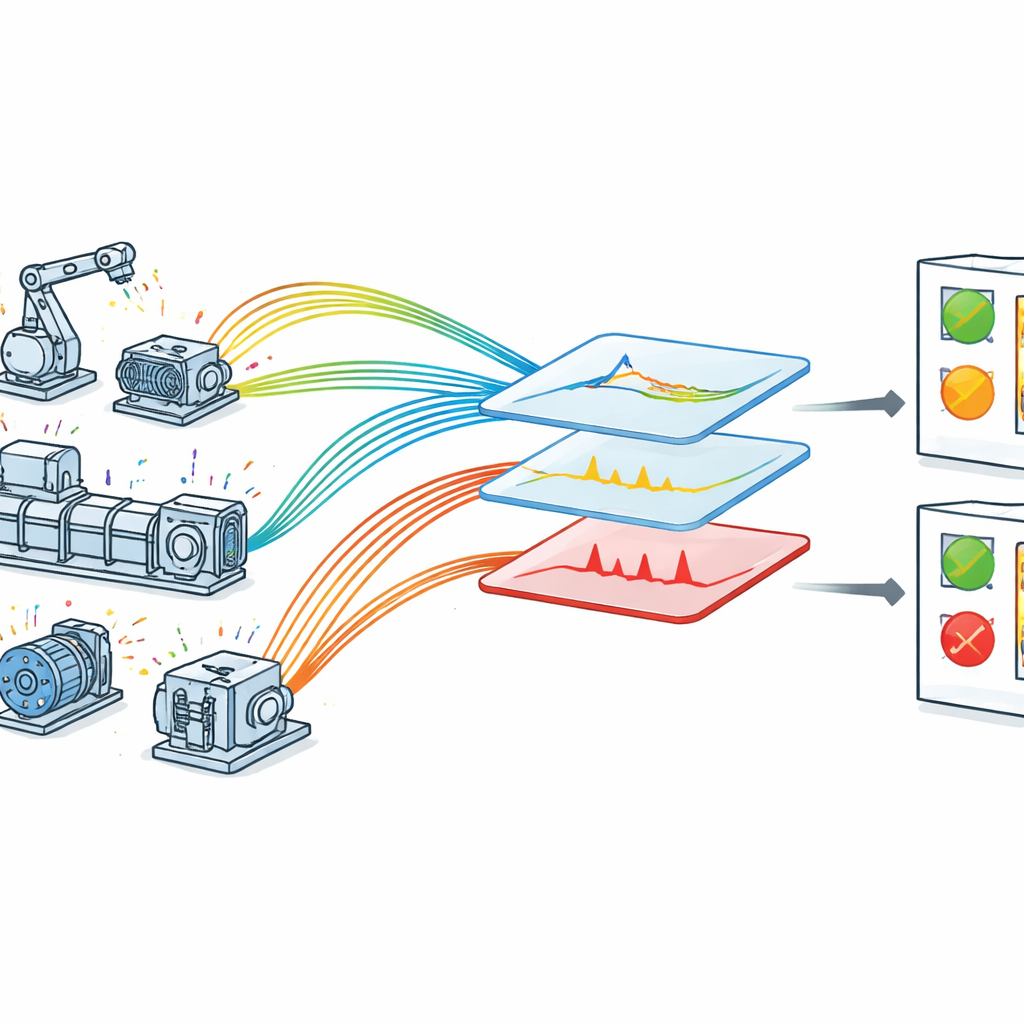
I en IoT-utrustad fabrik är varje viktig maskin försedd med sensorer som ständigt skickar tillbaka mätvärden om dess beteende. I teorin borde detta göra det enkelt att fånga upp problem innan de blir haverier. I praktiken är datan rörig: mätningar kan vara brusiga, mönster förändras när driftförhållandena varierar, och viktiga signaler kan vara dolda bland rutinfluktuationer. Många befintliga tillvägagångssätt fokuserar på bara en typ av fel eller bygger på handgjorda regler som kräver djup expertkunskap. Andra använder tunga djupinlärningsmodeller som fungerar väl i laboratoriet men är svåra att köra i realtid på industriell hårdvara med begränsad beräkningskraft. Som ett resultat har fabriker ofta svårt att omvandla rå sensordata till snabba och pålitliga felvarningar.
Hur den nya ramen bevakar datan
Författarna föreslår en optimerad ram för felupptäckt anpassad för IoT-aktiverade maskiner. De samlar först in realtidsdata i en kontrollerad men realistisk miljö där sensorer övervakar spänning, hastighet, vibration, temperatur och tryck på roterande utrustning. Varje mätning märks med en exakt tidsstämpel, vilket gör det möjligt för systemet att granska hur varje storhet förändras över tid. Rådata går sedan igenom en noggrann rengöringsfas: saknade värden hanteras, mätningar standardiseras till en gemensam skala, och breda felkategorier såsom mycket låg, låg, normal, hög och mycket hög tilldelas med hjälp av ingenjörskunskap. Dessa kategorier speglar hur underhållspersonal ser på driftgränser och hjälper modellen att koppla numeriska värden till meningsfulla maskintillstånd.
Att plocka ut de mest talande signalerna
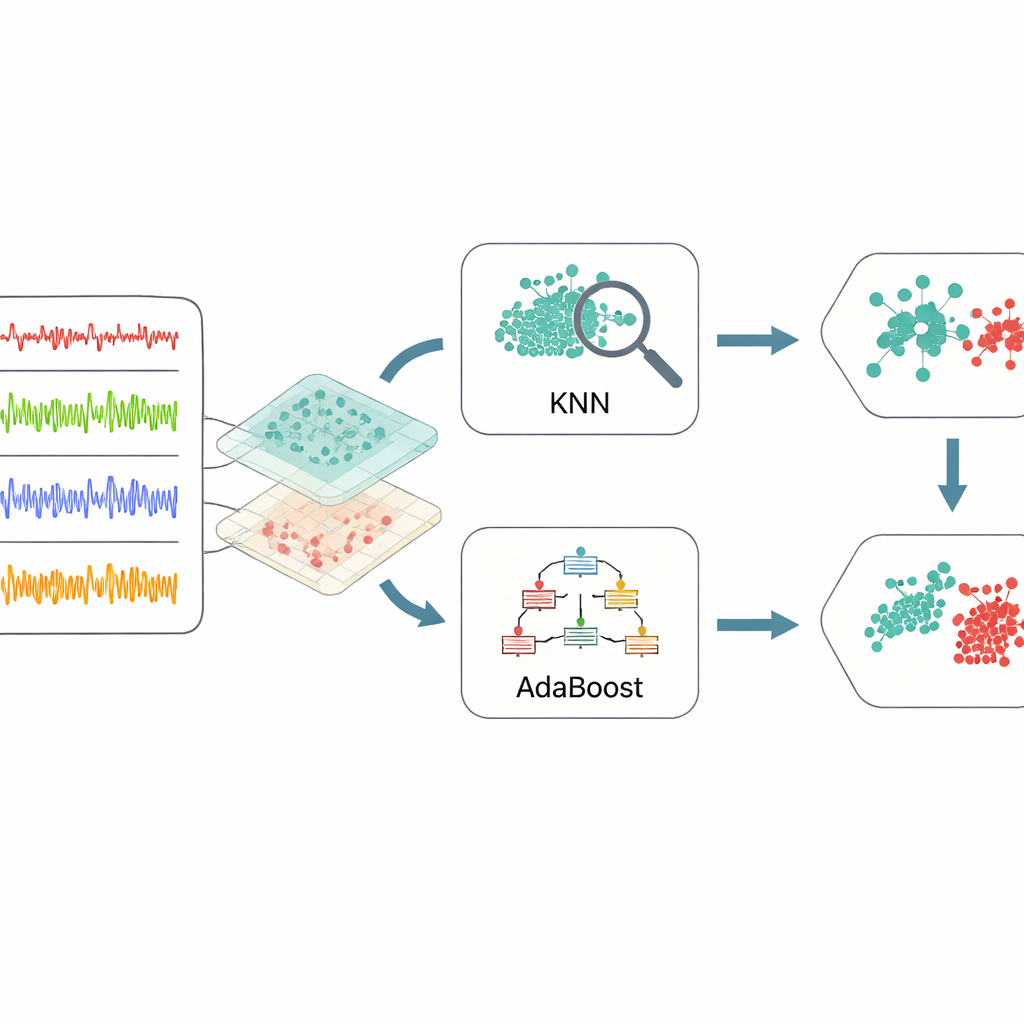
I stället för att mata in varje rått sensorvärde i en inlärningsalgoritm väljer ramen ut och omformar datan i två viktiga steg. Först undersöker en stegvis funktionsväljare varje sensortyp sida vid sida med tiden—till exempel spänning mot tidsstämpel eller vibration mot tidsstämpel. För varje par fokuserar den uppmärksamheten på intervall som är kända för att vara riskfyllda, såsom ovanligt låg hastighet eller ovanligt hög temperatur. Detta minskar brus och betonar de delar av datan som mest sannolikt innehåller tecken på problem. För det andra används en förbättrad version av en klassisk teknik kallad huvudsaklig komponentanalys för att skilja vanliga mönster från avvikande beteenden. Denna metod, kallad robust huvudsaklig komponentanalys, delar upp datan i en jämn bakgrund som representerar normal drift och en gles samling spikar och hopp som tyder på fel eller anomalier. Ett internt justeringssteg bestämmer hur starkt metoden balanserar dessa två delar, vilket förbättrar tydligheten i separationen.
Kombinera enkla inlärare för starkare beslut
När datan har destillerats till dessa informativa funktioner vänder sig ramen till en ensemble av två maskininlärningsmetoder. Den ena, k-närmsta grannar, söker efter grupper av tidigare fall som liknar en ny situation och avgör genom omröstning baserat på vad som hände tidigare. Den andra, AdaBoost, bygger upp en serie enkla beslutsregler och lägger extra vikt vid exempel som tidigare regler felklassificerat. Deras utdata kombineras sedan genom en viktad röstningsprocess, så att varje metod bidrar med sina styrkor: lokal känslighet från grannbaserade modellen och fokuserad uppmärksamhet på svårupptäckta fall från boosting-modellen. För att undvika gissningar vid inställningen av de många interna parametrarna använder författarna Bayesiansk optimering, en strategi som automatiskt söker efter kombinationer av inställningar som ger bästa möjliga prestanda med relativt få försök.
Vad experimenten visar
Forskargruppen testade sin ram på tusentals sensorposter hämtade från den simulerade IoT-maskinuppsättningen. De jämförde den med ett brett spektrum standardtekniker, från beslutsträd och slumpmässiga skogar till neurala nätverk och andra ensemblemodeller. Över mått som är viktigast för underhåll—total noggrannhet, hur ofta verkliga fel upptäcks korrekt och hur sällan systemet missar ett sant problem—kom den nya metoden konsekvent ut i topp. Den identifierade korrekt felvillkor kopplade till spänning, vibration, hastighet och temperatur med en noggrannhet nära 99 % och en mycket låg frekvens av missade fel. Statistiska tester över upprepade tränings- och testcykler visade att dessa förbättringar sannolikt inte beror på slumpen. Samtidigt förblev metoden beräkningsmässigt lätt, vilket gör den mer lämpad för drift på fabriksgolvet än många djupinlärningsbaserade alternativ.
Vad detta innebär för verkliga fabriker
I praktiska termer visar studien att noggrann rengöring och omformning av sensordata, följt av att kombinera två måttliga inlärningsverktyg på ett smart sätt, kan mäta sig med eller överträffa mer komplexa tillvägagångssätt för felupptäckt i maskiner. För anläggningsoperatörer kan detta innebära tidigare varningar när motorer börjar överhettas, när vibrationer antyder lagerförslitning eller när strömförsörjningsstörningar hotar känslig utrustning. Färre missade fel betyder färre oväntade haverier, medan en låg falsklarmfrekvens hindrar underhållsteamet från att jaga falska larm. Även om arbetet bygger på simulerade men realistiska data hävdar författarna att ramen är redo att testas på levande industriella system och kan bli ryggraden i mer transparent och kostnadseffektivt prediktivt underhåll i framtidens IoT-utrustade fabriker.
Citering: Devi Gayadri, S.V., Kanagaraj, G., Giri, J. et al. An optimized ensemble framework for machinery fault detection in IoT environments. Sci Rep 16, 10357 (2026). https://doi.org/10.1038/s41598-026-40335-7
Nyckelord: IoT-maskiner, felupptäckt, maskininlärning, industrisensorer, prediktivt underhåll