Clear Sky Science · en
An optimized ensemble framework for machinery fault detection in IoT environments
Keeping Factory Machines from Failing
Modern factories increasingly rely on networks of smart sensors to keep their machines running smoothly. Yet even with all this data, unexpected breakdowns still happen, costing time and money. This study explores a new way to sift through streams of sensor readings—such as temperature, vibration, speed, and voltage—to spot early warning signs of trouble in industrial machines connected through the Internet of Things (IoT). The goal is simple but powerful: detect faults sooner, more reliably, and with less computing effort so that downtime can be sharply reduced.
Why Watching Machines Is Hard
In an IoT-equipped factory, every key machine is fitted with sensors that constantly send back numbers on how it is behaving. In theory, this should make it easy to catch problems before they turn into failures. In practice, the data are messy: readings can be noisy, patterns change as operating conditions vary, and important signals may be buried among routine fluctuations. Many existing approaches focus on just one type of fault, or they depend on hand-crafted rules that require deep expert knowledge. Others use heavy deep-learning models that work well in the lab but are difficult to run in real time on industrial hardware with limited computing power. As a result, factories often struggle to turn raw sensor data into timely, trustworthy fault alerts.
How the New Framework Watches the Data
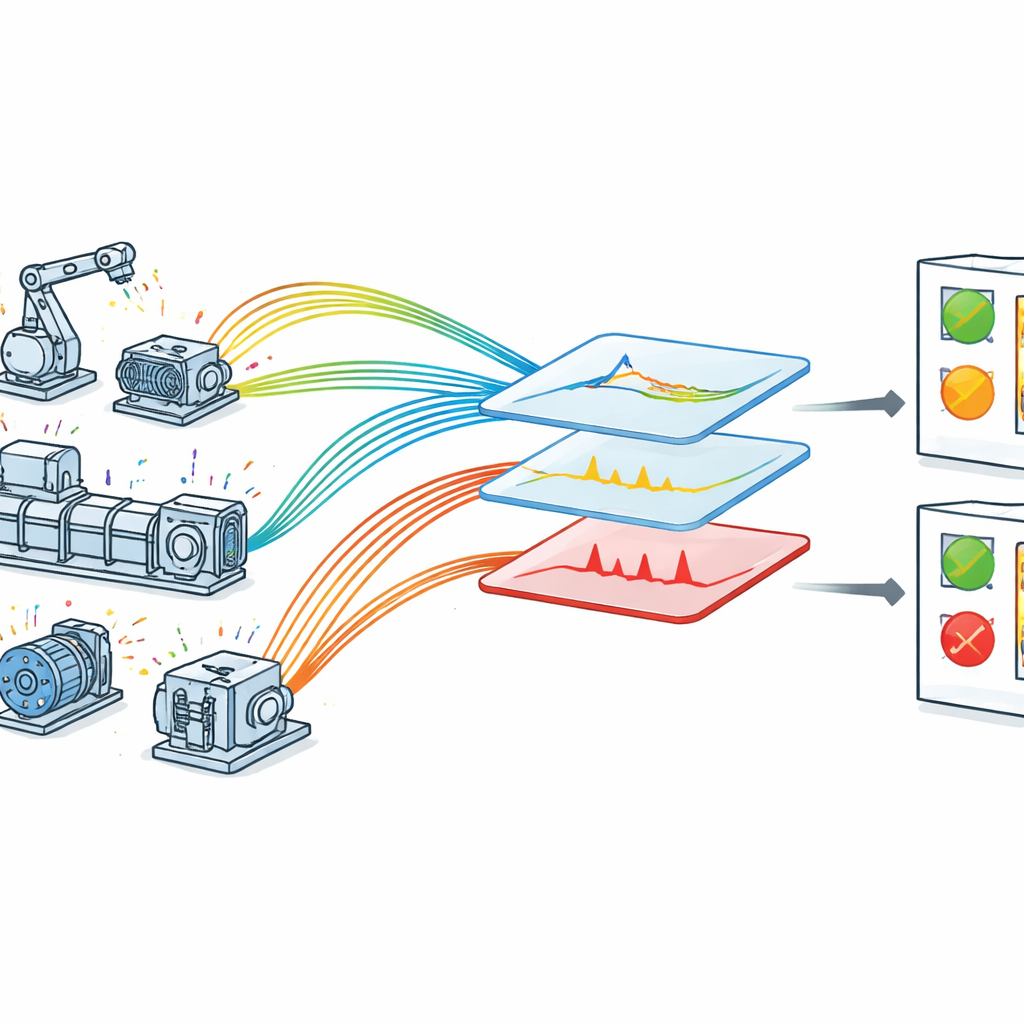
The authors propose an optimized fault detection framework tailored for IoT-enabled machinery. They first collect real-time data in a controlled but realistic setup where sensors track voltage, speed, vibration, temperature, and pressure on rotating equipment. Each reading is tagged with a precise timestamp, allowing the system to examine how each quantity changes over time. The raw data then go through a careful cleaning stage: missing values are handled, readings are standardized to a common scale, and broad fault categories such as very low, low, normal, high, and very high are assigned using engineering know-how. These categories mirror how maintenance staff think about operating limits and help the model connect numerical values to meaningful machine states.
Picking Out the Most Telling Signals
Rather than feeding every raw sensor value into a learning algorithm, the framework selects and reshapes the data in two key steps. First, a stage-wise feature selector examines each sensor type side by side with time—for example, voltage versus timestamp, or vibration versus timestamp. For each pair, it focuses attention on ranges that are known to be risky, such as unusually low speed or unusually high temperature. This reduces clutter and emphasizes portions of the data most likely to contain signs of trouble. Second, an enhanced version of a classic technique called principal component analysis is used to separate usual patterns from odd behavior. This method, called robust principal component analysis, splits the data into a smooth background representing normal operation and a sparse collection of spikes and jumps that suggest faults or anomalies. An internal tuning step adjusts how strongly the method balances these two pieces, improving the clarity of the separation.
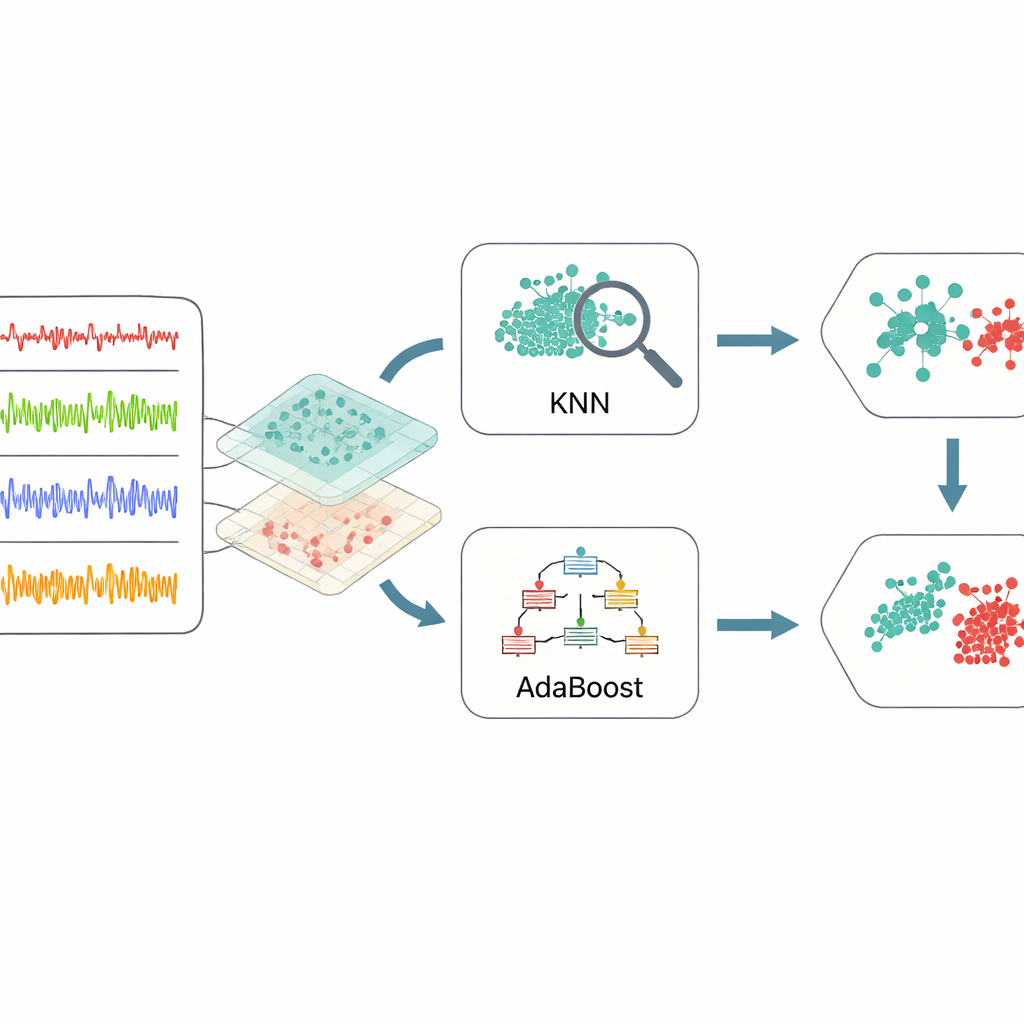
Combining Simple Learners for Stronger Decisions
Once the data have been distilled into these informative features, the framework turns to an ensemble of two machine learning methods. One, known as k-nearest neighbors, looks for groups of past cases that closely resemble a new situation and votes based on what happened before. The other, AdaBoost, builds up a series of simple decision rules, paying extra attention to examples that earlier rules misclassified. Their outputs are then combined through a weighted voting process, so that each method contributes its strengths: local sensitivity from the neighbor-based model and focused attention on hard-to-detect cases from the boosting model. To avoid guesswork in setting the many internal knobs of these learners, the authors use Bayesian optimization, a strategy that automatically searches for combinations of settings that yield the best overall performance with relatively few trial runs.
What the Experiments Show
The research team tested their framework on thousands of sensor records drawn from the simulated IoT machinery setup. They compared it with a wide range of standard techniques, from decision trees and random forests to neural networks and other ensemble models. Across measures that matter most in maintenance—overall accuracy, how often real faults are correctly detected, and how rarely the system misses a true problem—the new method consistently came out on top. It correctly identified fault conditions linked to voltage, vibration, speed, and temperature with accuracy near 99% and a very low rate of missed faults. Statistical tests across repeated train-and-test cycles showed that these gains are unlikely to be due to chance. At the same time, the method remained computationally light, making it more suitable for deployment on factory-floor hardware than many deep-learning-based alternatives.
What This Means for Real Factories
In everyday terms, the study shows that carefully cleaning and reshaping sensor data, then combining two modest learning tools in a smart way, can rival or beat more complex approaches to machine fault detection. For plant operators, this could translate into earlier warnings when motors begin to overheat, when vibration hints at bearing wear, or when power supply glitches threaten sensitive equipment. Fewer missed faults mean fewer surprise breakdowns, while a low false-alarm rate keeps maintenance teams from chasing ghosts. Although the work is based on simulated but realistic data, the authors argue that the framework is ready to be tested on live industrial systems and could form the backbone of more transparent, cost-effective predictive maintenance in future IoT-enabled factories.
Citation: Devi Gayadri, S.V., Kanagaraj, G., Giri, J. et al. An optimized ensemble framework for machinery fault detection in IoT environments. Sci Rep 16, 10357 (2026). https://doi.org/10.1038/s41598-026-40335-7
Keywords: IoT machinery, fault detection, machine learning, industrial sensors, predictive maintenance