Clear Sky Science · nl
Een geoptimaliseerd ensemblekader voor foutdetectie in machines in IoT-omgevingen
Voorkomen dat fabrieksmachines uitvallen
Moderne fabrieken vertrouwen steeds meer op netwerken van slimme sensoren om hun machines soepel te laten draaien. Toch gebeuren onverwachte storingen nog steeds, wat tijd en geld kost. Deze studie onderzoekt een nieuwe manier om stroomlijsten van sensorgegevens — zoals temperatuur, trilling, snelheid en spanning — te doorzoeken om vroegtijdige waarschuwingssignalen van problemen te ontdekken in industriële machines die via het Internet of Things (IoT) verbonden zijn. Het doel is eenvoudig maar krachtig: fouten eerder, betrouwbaarder en met minder rekenkracht detecteren, zodat uitvaltijd sterk kan worden verminderd.
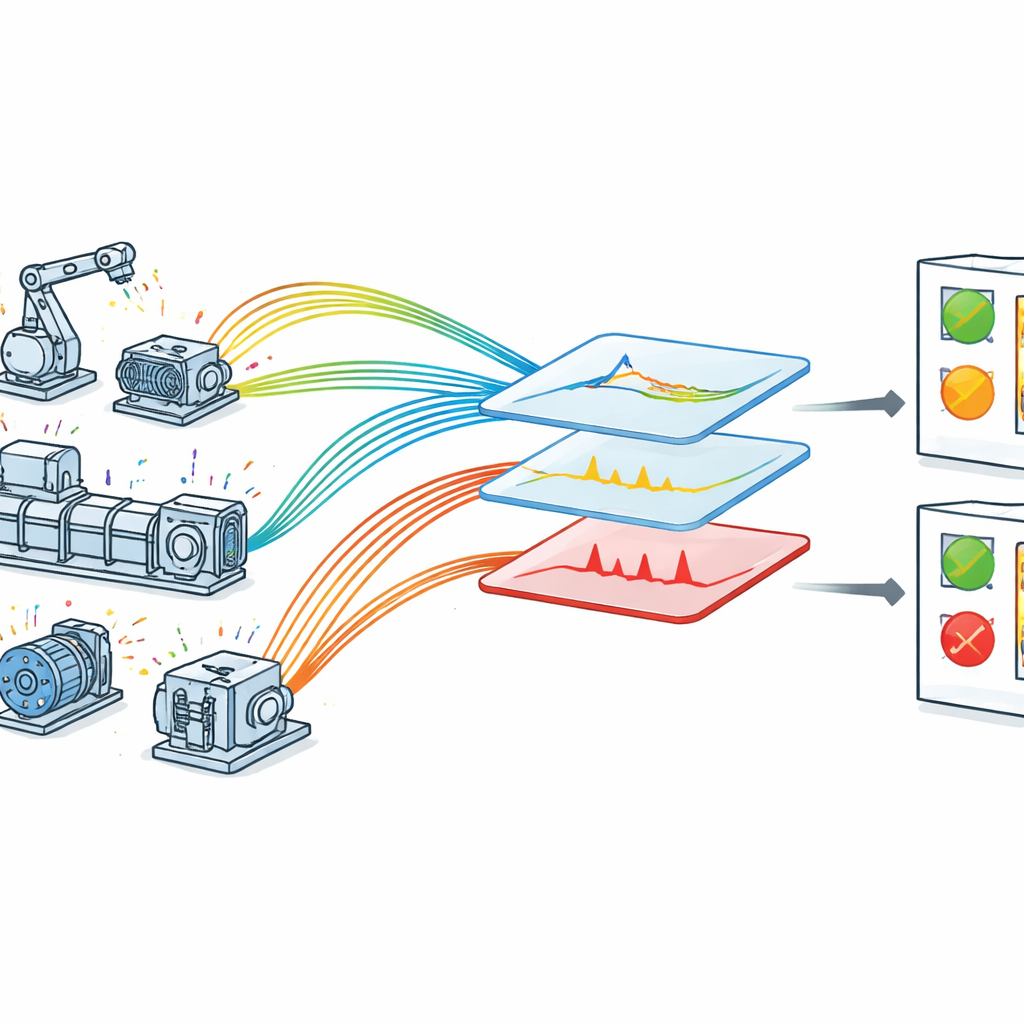
Waarom het lastig is om machines te bewaken
In een met IoT uitgeruste fabriek is elke cruciale machine voorzien van sensoren die continu waarden terugsturen over hoe de machine zich gedraagt. In theorie zou dit het eenvoudig moeten maken om problemen te ontdekken voordat ze in storingen uitmonden. In de praktijk zijn de gegevens rommelig: metingen kunnen ruis bevatten, patronen veranderen naargelang de bedrijfsomstandigheden en belangrijke signalen kunnen verstopt zitten tussen routinefluctuaties. Veel bestaande benaderingen richten zich op slechts één type fout, of ze vertrouwen op handmatige regels die diepgaande deskundigheid vereisen. Andere gebruiken zware deep-learningmodellen die in het laboratorium goed werken maar moeilijk in realtime draaien op industriële hardware met beperkte rekenkracht. Daardoor worstelen fabrieken vaak met het omzetten van ruwe sensorgegevens in tijdige, betrouwbare foutmeldingen.
Hoe het nieuwe kader de data bekijkt
De auteurs stellen een geoptimaliseerd detectiekader voor, toegespitst op IoT-geschikte machines. Eerst verzamelen ze realtimegegevens in een gecontroleerde maar realistische opstelling waarin sensoren spanning, snelheid, trilling, temperatuur en druk op roterende apparatuur volgen. Elke meting krijgt een nauwkeurige tijdstempel, zodat het systeem kan nagaan hoe elke grootheid in de tijd verandert. De ruwe data doorlopen vervolgens een zorgvuldige schoonmaakfase: ontbrekende waarden worden afgehandeld, metingen worden gestandaardiseerd naar een gemeenschappelijke schaal en brede foutcategorieën zoals zeer laag, laag, normaal, hoog en zeer hoog worden toegewezen met behulp van technische kennis. Deze categorieën spiegelen hoe onderhoudspersoneel over bedrijfsgrenzen denkt en helpen het model numerieke waarden te koppelen aan betekenisvolle machinecondities.
De meest veelzeggende signalen eruit pikken
In plaats van elke ruwe sensorwaarde in een leeralgoritme te stoppen, selecteert en hervormt het kader de data in twee sleutelstappen. Ten eerste onderzoekt een stapsgewijze feature-selector elk type sensor zij aan zij met tijd—bijvoorbeeld spanning versus tijdstempel of trilling versus tijdstempel. Voor elk paar richt het zich op bereiken die bekendstaan als risicovol, zoals uitzonderlijk lage snelheid of uitzonderlijk hoge temperatuur. Dit vermindert ruis en legt de nadruk op delen van de data die het meest waarschijnlijk tekenen van problemen bevatten. Ten tweede wordt een verbeterde versie van een klassieke techniek, principal component analysis, gebruikt om gebruikelijke patronen te scheiden van afwijkend gedrag. Deze methode, robuuste principal component analysis genoemd, splitst de data in een vloeiende achtergrond die normale werking weergeeft en een spars verzameling pieken en sprongen die op fouten of anomalieën duiden. Een interne afstap regelt hoe sterk de methode deze twee componenten tegen elkaar afweegt, waardoor de scheiding duidelijker wordt.
Simpele lerende modellen combineren voor sterkere beslissingen
Wanneer de data zijn gedistilleerd tot deze informatieve kenmerken, schakelt het kader over op een ensemble van twee machine-learningmethoden. De ene, bekend als k-nearest neighbors, zoekt naar groepen eerdere gevallen die sterk lijken op een nieuwe situatie en stemt op basis van wat eerder gebeurde. De andere, AdaBoost, bouwt een reeks eenvoudige beslisregels op en besteedt extra aandacht aan voorbeelden die eerdere regels verkeerd classificeerden. Hun uitkomsten worden vervolgens gecombineerd via een gewogen stemsysteem, zodat elke methode haar sterke punten inbrengt: lokale gevoeligheid van het buurmodel en gerichte aandacht voor moeilijk detecteerbare gevallen van het boost-model. Om giswerk bij het instellen van de vele interne knoppen van deze leerders te vermijden, gebruiken de auteurs Bayesian optimalisatie, een strategie die automatisch zoekt naar combinaties van instellingen die de beste algemene prestatie opleveren met relatief weinig proefruns.
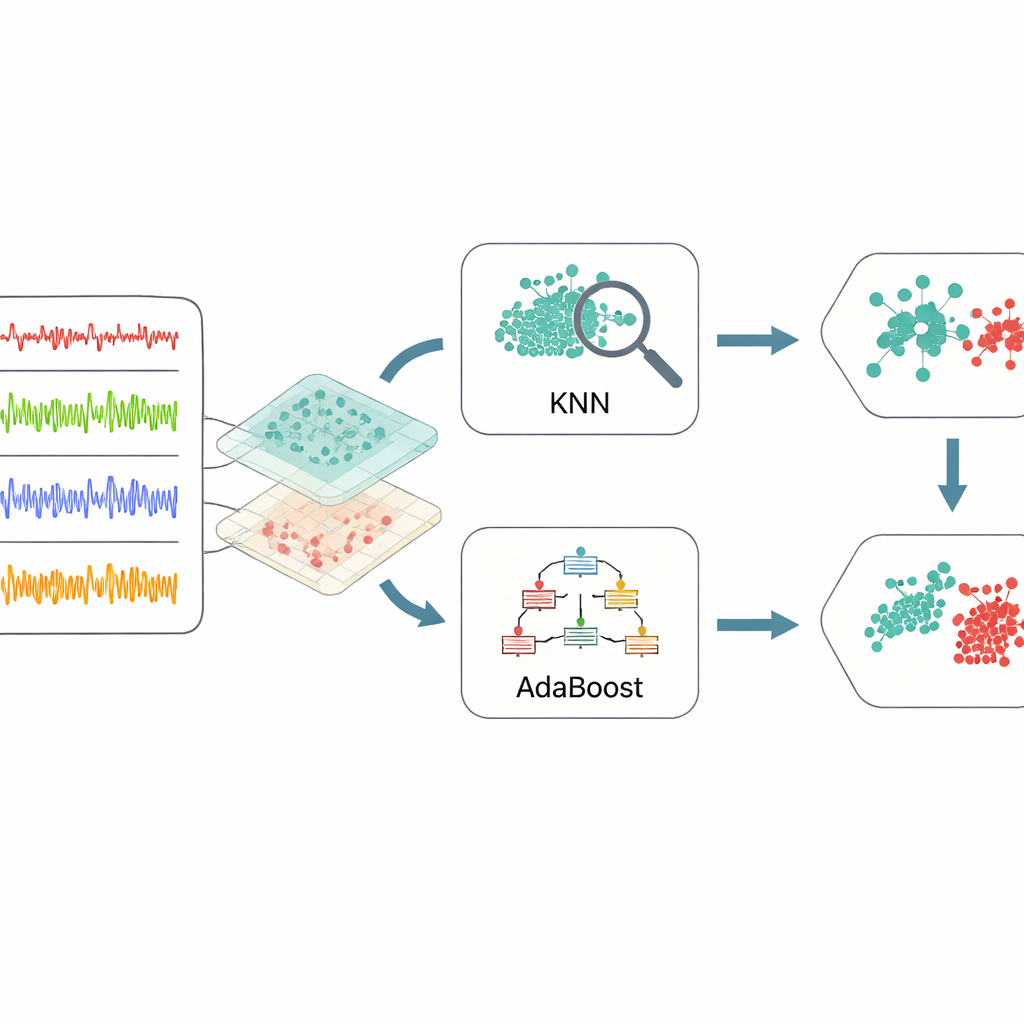
Wat de experimenten aantonen
Het onderzoeksteam testte hun kader op duizenden sensorgegevens afkomstig van de gesimuleerde IoT-machinesetup. Ze vergeleken het met een breed scala standaardtechnieken, van beslisbomen en random forests tot neurale netwerken en andere ensamblemodellen. Over maten die het meest van belang zijn voor onderhoud—totale nauwkeurigheid, hoe vaak echte fouten correct worden gedetecteerd en hoe zelden het systeem een werkelijk probleem mist—kwam de nieuwe methode consequent als beste uit de bus. Het identificeerde foutcondities gekoppeld aan spanning, trilling, snelheid en temperatuur met een nauwkeurigheid dichtbij 99% en een zeer laag percentage gemiste fouten. Statistische testen over herhaalde train-en-testcycli toonden aan dat deze winst waarschijnlijk niet door toeval verklaard kan worden. Tegelijk bleef de methode rekenefficiënt, waardoor hij beter inzetbaar is op fabrieksvloerhardware dan veel deep-learningalternatieven.
Wat dit betekent voor echte fabrieken
In praktische termen laat de studie zien dat het zorgvuldig schoonmaken en hervormen van sensorgegevens, gevolgd door het slim combineren van twee bescheiden leermethoden, kan concurreren met of beter kan presteren dan complexere benaderingen voor foutdetectie in machines. Voor procesbeheerders kan dit zich vertalen in eerdere waarschuwingen wanneer motoren beginnen te oververhitten, wanneer trillingen wijzen op lager slijtage of wanneer stroomstoringen gevoelige apparatuur bedreigen. Minder gemiste fouten betekent minder onverwachte storingen, terwijl een lage valsalarmfrequentie voorkomt dat onderhoudsteams achter spookmeldingen aanlopen. Hoewel het werk is gebaseerd op gesimuleerde maar realistische data, stellen de auteurs dat het kader klaar is om in live industriële systemen te worden getest en de ruggengraat kan vormen van meer transparant en kosteneffectief voorspellend onderhoud in toekomstige IoT-geschikte fabrieken.
Bronvermelding: Devi Gayadri, S.V., Kanagaraj, G., Giri, J. et al. An optimized ensemble framework for machinery fault detection in IoT environments. Sci Rep 16, 10357 (2026). https://doi.org/10.1038/s41598-026-40335-7
Trefwoorden: IoT-machines, foutdetectie, machine learning, industriële sensoren, predictive maintenance