Clear Sky Science · pt
Uma estrutura de conjunto otimizada para detecção de falhas em máquinas em ambientes de IoT
Evitar que Máquinas de Fábrica Falhem
Fábricas modernas dependem cada vez mais de redes de sensores inteligentes para manter suas máquinas funcionando sem problemas. Ainda assim, mesmo com todo esse fluxo de dados, quebras inesperadas continuam a ocorrer, custando tempo e dinheiro. Este estudo explora uma nova maneira de selecionar sinais em fluxos de leituras de sensores — como temperatura, vibração, velocidade e tensão — para identificar sinais precoces de problema em máquinas industriais conectadas pela Internet das Coisas (IoT). O objetivo é simples, porém poderoso: detectar falhas mais cedo, com maior confiabilidade e com menos esforço computacional, de modo a reduzir drasticamente o tempo de inatividade.
Por que Monitorar Máquinas é Difícil
Em uma fábrica equipada com IoT, cada máquina-chave é dotada de sensores que enviam constantemente números sobre seu comportamento. Em teoria, isso deveria facilitar a identificação de problemas antes que eles se transformem em falhas. Na prática, os dados são bagunçados: leituras podem ser ruidosas, padrões mudam conforme variam as condições de operação e sinais importantes podem estar enterrados entre flutuações rotineiras. Muitas abordagens existentes focam apenas em um tipo de falha ou dependem de regras artesanais que exigem conhecimento profundo de especialistas. Outras usam modelos pesados de deep learning que funcionam bem em laboratório, mas são difíceis de rodar em tempo real em hardware industrial com capacidade computacional limitada. Como resultado, fábricas frequentemente têm dificuldade em transformar dados brutos de sensores em alertas de falha oportunos e confiáveis.
Como a Nova Estrutura Observa os Dados
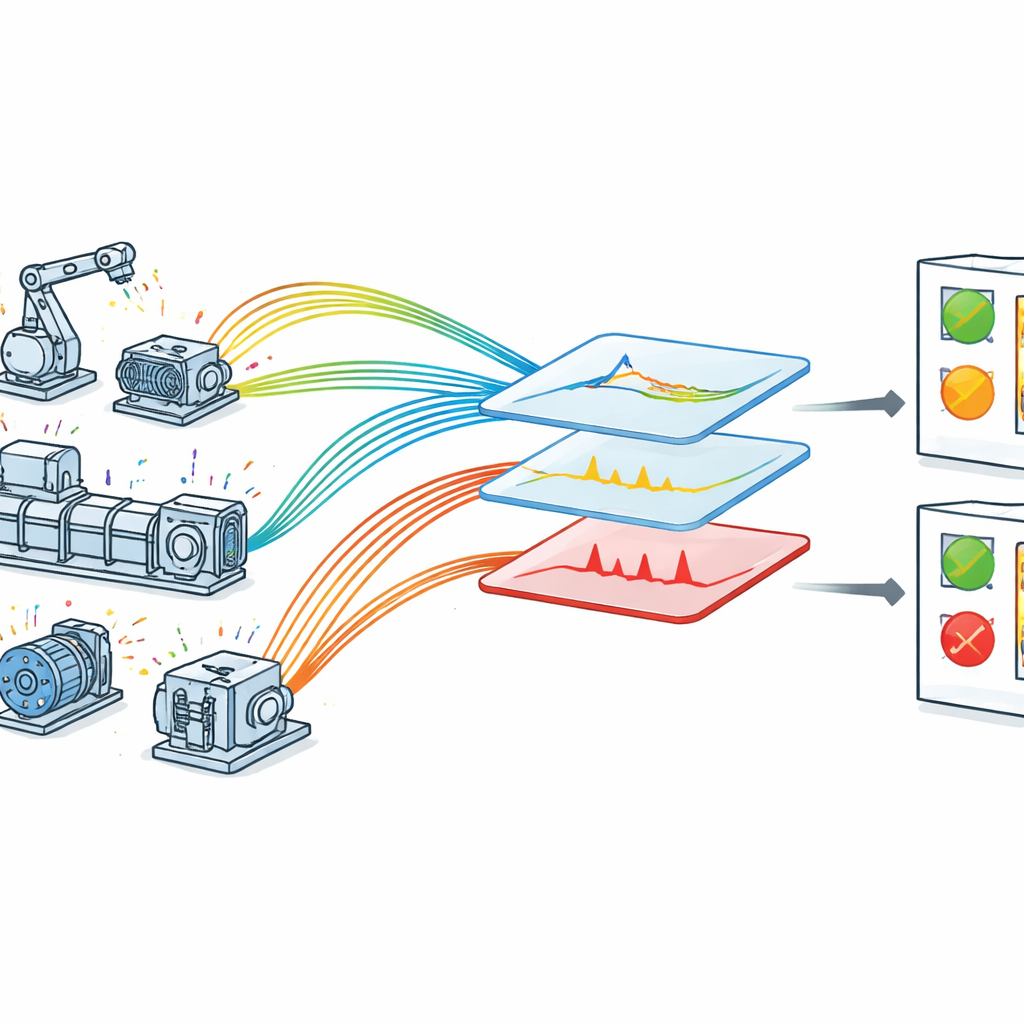
Os autores propõem uma estrutura otimizada de detecção de falhas, feita sob medida para maquinário habilitado por IoT. Eles primeiro coletam dados em tempo real em um ambiente controlado, porém realista, onde sensores monitoram tensão, velocidade, vibração, temperatura e pressão em equipamentos rotativos. Cada leitura é marcada com um carimbo de tempo preciso, permitindo ao sistema examinar como cada grandeza varia ao longo do tempo. Os dados brutos passam então por uma etapa cuidadosa de limpeza: valores ausentes são tratados, leituras são padronizadas para uma escala comum e categorias amplas de condição, como muito baixa, baixa, normal, alta e muito alta, são atribuídas usando conhecimento de engenharia. Essas categorias espelham a forma como a equipe de manutenção pensa sobre limites operacionais e ajudam o modelo a conectar valores numéricos a estados de máquina com significado.
Selecionando os Sinais Mais Reveladores
Em vez de alimentar todo valor bruto de sensor em um algoritmo de aprendizado, a estrutura seleciona e molda os dados em duas etapas principais. Primeiro, um seletor de características em estágios examina cada tipo de sensor lado a lado com o tempo — por exemplo, tensão versus carimbo de tempo ou vibração versus carimbo de tempo. Para cada par, ele foca em faixas conhecidas por serem arriscadas, como velocidade incomumente baixa ou temperatura incomumente alta. Isso reduz a desordem e enfatiza porções dos dados mais propensas a conter sinais de problema. Em seguida, uma versão aprimorada de uma técnica clássica chamada análise de componentes principais é usada para separar padrões usuais de comportamentos atípicos. Esse método, chamado análise de componentes principais robusta, divide os dados em um fundo suave que representa operação normal e uma coleção esparsa de picos e saltos que sugerem falhas ou anomalias. Uma etapa interna de ajuste regula com que intensidade o método equilibra essas duas partes, melhorando a clareza da separação.
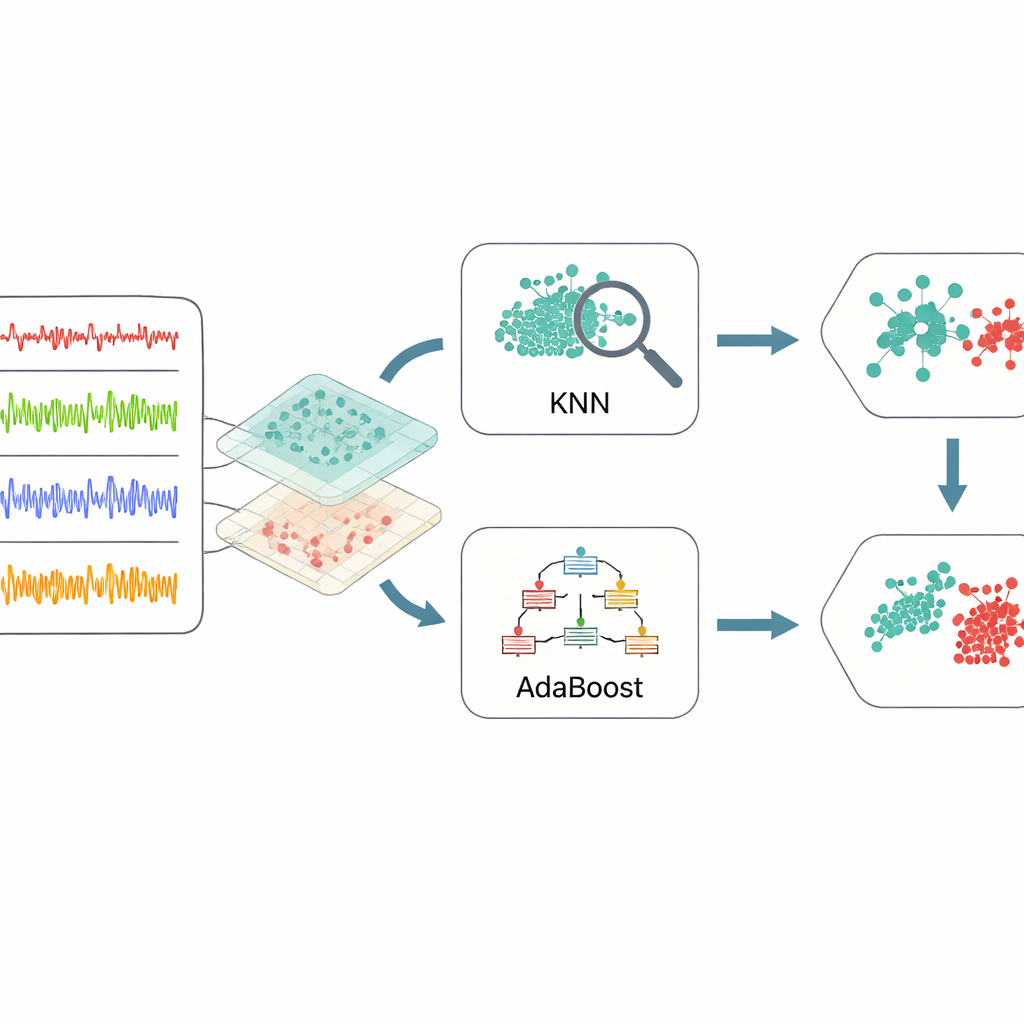
Combinando Aprendizes Simples para Decisões Mais Fortes
Depois que os dados são destilados nessas características informativas, a estrutura recorre a um conjunto (ensemble) de dois métodos de aprendizado de máquina. Um, conhecido como k-vizinhos mais próximos, procura grupos de casos passados que se assemelham fortemente a uma nova situação e vota com base no que aconteceu antes. O outro, AdaBoost, constrói uma série de regras de decisão simples, dando atenção extra a exemplos que regras anteriores classificaram incorretamente. As saídas são então combinadas por meio de um processo de votação ponderada, de modo que cada método contribua com suas forças: sensibilidade local do modelo baseado em vizinhos e atenção focada em casos de difícil detecção do modelo de boosting. Para evitar tentativa e erro na configuração dos muitos parâmetros internos desses aprendizes, os autores usam otimização bayesiana, uma estratégia que busca automaticamente combinações de ajustes que oferecem o melhor desempenho geral com relativamente poucas execuções de teste.
O que os Experimentos Mostram
A equipe de pesquisa testou sua estrutura em milhares de registros de sensores extraídos do ambiente simulado de maquinário IoT. Eles a compararam com uma ampla gama de técnicas padrão, desde árvores de decisão e florestas aleatórias até redes neurais e outros modelos em conjunto. Nas medidas que mais importam em manutenção — precisão geral, com que frequência falhas reais são corretamente detectadas e com que raridade o sistema deixa de identificar um problema verdadeiro — o novo método consistentemente ficou no topo. Ele identificou corretamente condições de falha ligadas a tensão, vibração, velocidade e temperatura com precisão próxima a 99% e uma taxa muito baixa de falhas não detectadas. Testes estatísticos em ciclos repetidos de treino e teste mostraram que esses ganhos provavelmente não se devem ao acaso. Ao mesmo tempo, o método permaneceu computacionalmente leve, tornando-o mais adequado para implantação em hardware de chão de fábrica do que muitas alternativas baseadas em deep learning.
O que Isso Significa para Fábricas Reais
Em termos práticos, o estudo mostra que limpar e remodelar cuidadosamente dados de sensores, e então combinar dois instrumentos de aprendizado modestos de forma inteligente, pode rivalizar ou superar abordagens mais complexas de detecção de falhas em máquinas. Para operadores de planta, isso pode se traduzir em avisos mais precoces quando motores começam a superaquecer, quando vibração indica desgaste de rolamentos ou quando falhas na alimentação de energia ameaçam equipamentos sensíveis. Menos falhas perdidas significam menos quebras surpresa, enquanto uma baixa taxa de falsos alarmes evita que as equipes de manutenção persigam sinais inexistentes. Embora o trabalho seja baseado em dados simulados, porém realistas, os autores argumentam que a estrutura está pronta para ser testada em sistemas industriais reais e pode formar a espinha dorsal de uma manutenção preditiva mais transparente e custo-efetiva em futuras fábricas habilitadas por IoT.
Citação: Devi Gayadri, S.V., Kanagaraj, G., Giri, J. et al. An optimized ensemble framework for machinery fault detection in IoT environments. Sci Rep 16, 10357 (2026). https://doi.org/10.1038/s41598-026-40335-7
Palavras-chave: IoT em máquinas, detecção de falhas, aprendizado de máquina, sensores industriais, manutenção preditiva