Clear Sky Science · pl
Optymalizowany układ zespołowy do wykrywania usterek maszyn w środowiskach IoT
Zapobieganie awariom maszyn w fabryce
Współczesne zakłady coraz częściej polegają na sieciach inteligentnych czujników, by utrzymać maszyny w sprawnym działaniu. Mimo dużej ilości danych, nieoczekiwane awarie nadal się zdarzają, generując straty czasu i pieniędzy. Badanie przedstawia nowy sposób przetwarzania strumieni odczytów z czujników — takich jak temperatura, wibracje, prędkość i napięcie — aby wychwycić wczesne sygnały ostrzegawcze o problemach w maszynach przemysłowych połączonych przez Internet rzeczy (IoT). Cel jest prosty, lecz istotny: wykrywać usterki szybciej, bardziej niezawodnie i przy mniejszym nakładzie obliczeniowym, tak by znacząco ograniczyć przestoje.
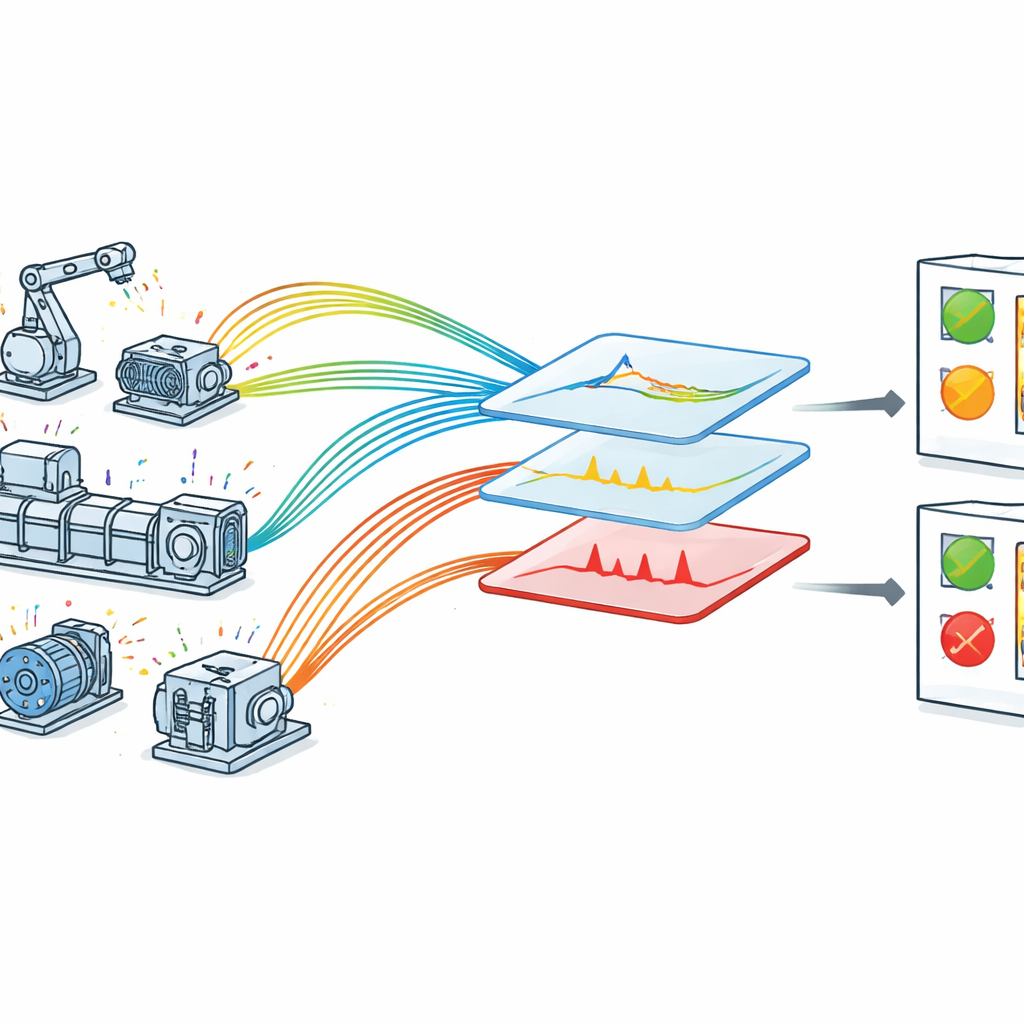
Dlaczego obserwacja maszyn jest trudna
W fabryce wyposażonej w IoT każda kluczowa maszyna ma czujniki, które nieustannie przesyłają dane o jej pracy. W teorii powinno to ułatwiać wykrywanie problemów zanim przerodzą się w awarie. W praktyce dane są chaotyczne: pomiary mogą być zaszumione, wzorce zmieniają się wraz z warunkami pracy, a istotne sygnały mogą być ukryte w rutynowych fluktuacjach. Wiele istniejących metod koncentruje się na jednym typie usterki lub opiera się na ręcznie skonstruowanych regułach wymagających głębokiej wiedzy eksperckiej. Inne używają ciężkich modeli głębokiego uczenia, które dobrze działają w laboratorium, ale trudno uruchamiać je w czasie rzeczywistym na sprzęcie przemysłowym o ograniczonej mocy obliczeniowej. W efekcie zakłady często mają problem z przemienieniem surowych danych z czujników w terminowe i wiarygodne alarmy o usterkach.
Jak nowy system obserwuje dane
Autorzy proponują zoptymalizowane ramy wykrywania usterek dostosowane do maszyn zintegrowanych z IoT. Najpierw zbierają dane w czasie rzeczywistym w kontrolowanym, lecz realistycznym środowisku, gdzie czujniki mierzą napięcie, prędkość, wibracje, temperaturę i ciśnienie na sprzęcie obrotowym. Każdy pomiar jest oznaczony precyzyjnym znacznikiem czasu, co pozwala systemowi analizować, jak każda wielkość zmienia się w czasie. Surowe dane przechodzą następnie staranne czyszczenie: obsługuje się brakujące wartości, standaryzuje odczyty do wspólnej skali, a szerokie kategorie awarii — bardzo niskie, niskie, normalne, wysokie i bardzo wysokie — są przypisywane z wykorzystaniem wiedzy inżynierskiej. Kategorie te odzwierciedlają sposób myślenia personelu utrzymania ruchu o granicach eksploatacyjnych i pomagają modelowi powiązać wartości liczbowe ze znaczącymi stanami maszyny.
Wybieranie najbardziej diagnostycznych sygnałów
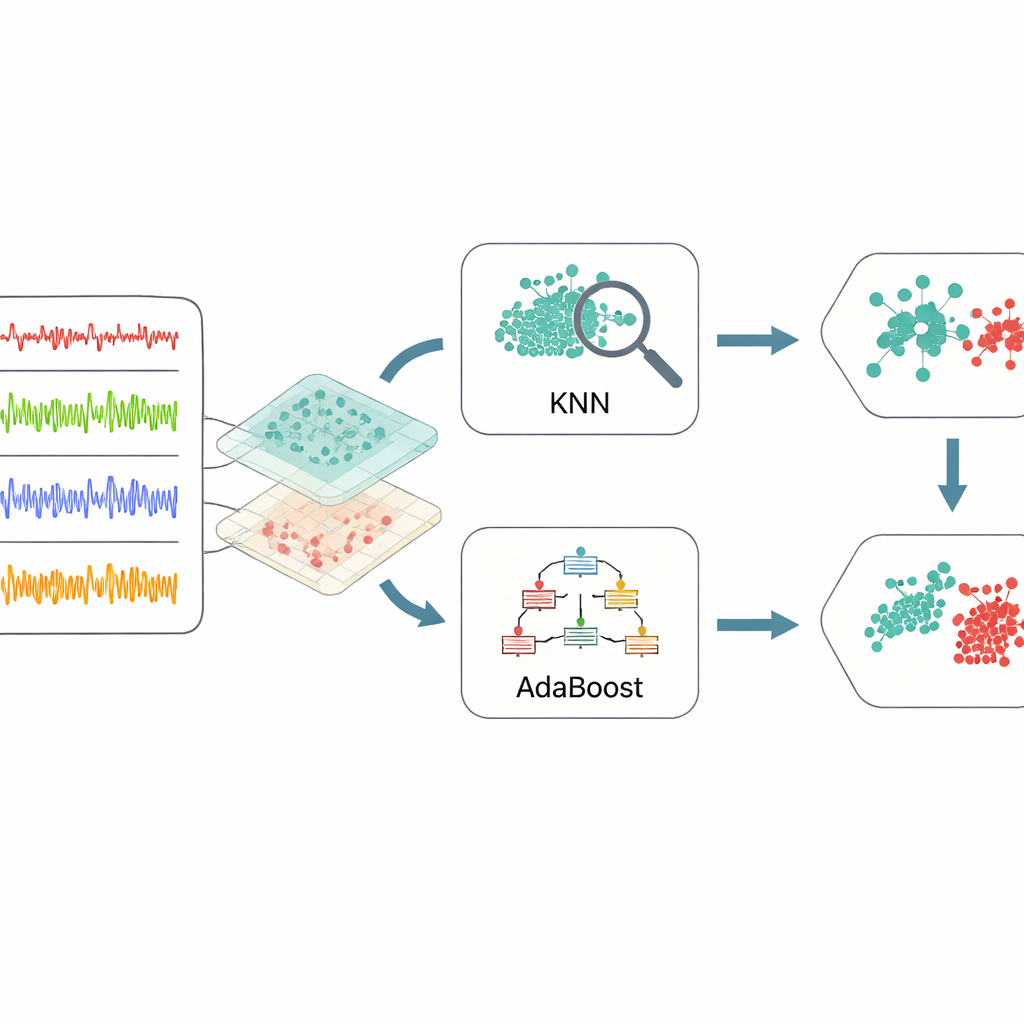
Zamiast podawać każdy surowy odczyt do algorytmu uczącego się, ramy wybierają i przekształcają dane w dwóch istotnych krokach. Najpierw selektor cech działający etapami analizuje każdy typ czujnika razem z czasem — na przykład napięcie względem znacznika czasu lub wibracje względem czasu. Dla każdej pary koncentruje się na zakresach znanych jako ryzykowne, takich jak nietypowo niska prędkość czy nietypowo wysoka temperatura. To redukuje szum i podkreśla fragmenty danych, które najbardziej prawdopodobnie zawierają sygnały problemów. Po drugie, użyta zostaje ulepszona wersja klasycznej techniki analizy składowych głównych, która oddziela zwykłe wzorce od nietypowych zachowań. Metoda ta, zwana odporną analizą składowych głównych (robust PCA), dzieli dane na gładkie tło reprezentujące normalną pracę oraz rzadkie skoki i piki sugerujące usterki lub anomalie. Wewnętrzny etap strojenia dostosowuje, jak mocno metoda równoważy te dwie składowe, poprawiając klarowność rozdzielenia.
Łączenie prostych klasyfikatorów dla mocniejszych decyzji
Gdy dane zostaną sprowadzone do tych informacyjnych cech, ramy sięgają po zespół dwóch metod uczenia maszynowego. Jedna, znana jako k-najbliższych sąsiadów, szuka grup przeszłych przypadków podobnych do nowej sytuacji i głosuje na podstawie tego, co działo się wcześniej. Druga, AdaBoost, buduje serię prostych reguł decyzyjnych, zwracając szczególną uwagę na przykłady, które wcześniejsze reguły błędnie sklasyfikowały. Ich wyniki są następnie łączone przez ważone głosowanie, tak aby każda metoda wnosiła swoje zalety: lokalną czułość od modelu sąsiedzkiego oraz skoncentrowaną uwagę na trudnych do wykrycia przypadkach od modelu wzmacniającego. Aby uniknąć zgadywania przy ustawianiu licznych parametrów tych modeli, autorzy stosują optymalizację bayesowską — strategię, która automatycznie przeszukuje kombinacje ustawień, znajdując te dające najlepsze wyniki przy stosunkowo niewielu próbach.
Co pokazują eksperymenty
Zespół badawczy przetestował swoje ramy na tysiącach zapisów z czujników pochodzących z symulowanego środowiska maszyn IoT. Porównali je z szerokim wachlarzem standardowych technik, od drzew decyzyjnych i lasów losowych po sieci neuronowe i inne modele zespołowe. W miarach najważniejszych dla utrzymania ruchu — dokładność ogólna, częstość prawidłowego wykrywania rzeczywistych usterek oraz rzadka utrata prawdziwych problemów — nowa metoda konsekwentnie osiągała najlepsze wyniki. Poprawnie identyfikowała stany awaryjne związane z napięciem, wibracjami, prędkością i temperaturą z dokładnością bliską 99% oraz bardzo niskim odsetkiem przeoczonych usterek. Testy statystyczne przeprowadzone w powtarzanych cyklach trenowania i testowania wykazały, że te zyski są mało prawdopodobne do przypisania przypadkowi. Jednocześnie metoda pozostała lekka obliczeniowo, co czyni ją bardziej odpowiednią do wdrożenia na sprzęcie fabrycznym niż wiele rozwiązań opartych na głębokim uczeniu.
Co to oznacza dla realnych zakładów
Mówiąc prościej, badanie pokazuje, że staranne oczyszczenie i przekształcenie danych z czujników, a następnie połączenie dwóch umiarkowanych narzędzi uczących się w przemyślany sposób, może dorównać lub przewyższyć bardziej złożone podejścia do wykrywania usterek maszyn. Dla operatorów zakładów może to oznaczać wcześniejsze ostrzeżenia, gdy silniki zaczynają się przegrzewać, gdy wibracje wskazują na zużycie łożysk, lub gdy zakłócenia w zasilaniu zagrażają wrażliwym urządzeniom. Mniej przeoczonych usterek to mniej niespodziewanych awarii, a niski wskaźnik fałszywych alarmów zapobiega niepotrzebnym interwencjom zespołów utrzymania ruchu. Chociaż praca opiera się na danych symulowanych, lecz realistycznych, autorzy twierdzą, że ramy są gotowe do testów na rzeczywistych systemach przemysłowych i mogą stać się podstawą bardziej przejrzystej i opłacalnej konserwacji predykcyjnej w przyszłych fabrykach zintegrowanych z IoT.
Cytowanie: Devi Gayadri, S.V., Kanagaraj, G., Giri, J. et al. An optimized ensemble framework for machinery fault detection in IoT environments. Sci Rep 16, 10357 (2026). https://doi.org/10.1038/s41598-026-40335-7
Słowa kluczowe: maszyny IoT, wykrywanie usterek, uczenie maszynowe, czujniki przemysłowe, konserwacja predykcyjna