Clear Sky Science · fr
Un cadre d’ensemble optimisé pour la détection de pannes d’équipements dans les environnements IoT
Empêcher les machines d’usine de tomber en panne
Les usines modernes s’appuient de plus en plus sur des réseaux de capteurs intelligents pour maintenir leurs machines en bon état de fonctionnement. Pourtant, malgré l’abondance de données, des pannes inattendues continuent de survenir, entraînant des pertes de temps et d’argent. Cette étude explore une nouvelle méthode pour filtrer les flux de mesures de capteurs — comme la température, les vibrations, la vitesse et la tension — afin de détecter les signaux d’alerte précoces de dysfonctionnement sur des machines industrielles connectées via l’Internet des objets (IoT). L’objectif est simple mais puissant : détecter les pannes plus tôt, de façon plus fiable et avec moins de ressources de calcul, afin de réduire nettement les temps d’arrêt.
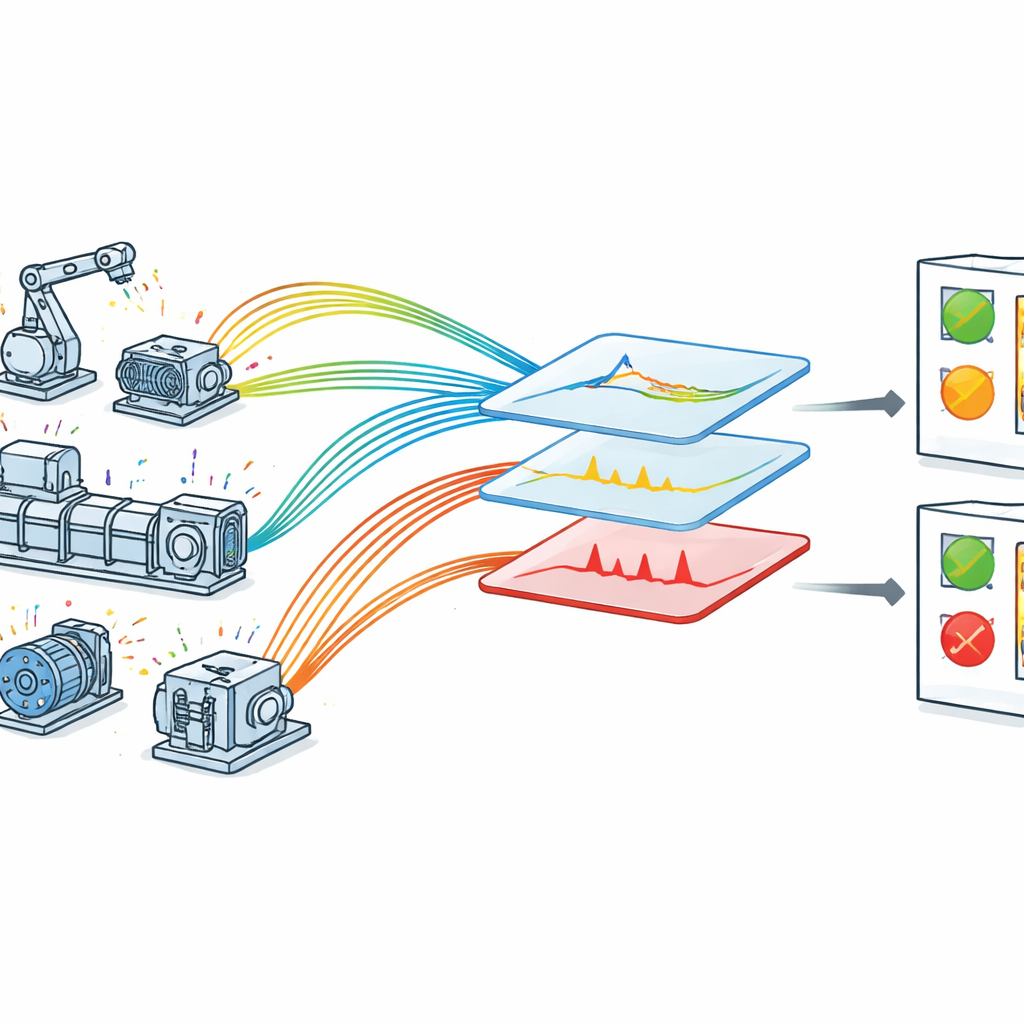
Pourquoi surveiller les machines est difficile
Dans une usine équipée en IoT, chaque machine clé est dotée de capteurs qui renvoient en permanence des valeurs décrivant son comportement. En théorie, cela devrait faciliter la détection de problèmes avant qu’ils ne deviennent des pannes. En pratique, les données sont bruitées : les mesures peuvent être soumises au bruit, les motifs évoluent selon les conditions d’exploitation, et des signaux importants peuvent être noyés dans des variations de routine. De nombreuses approches existantes se concentrent sur un seul type de panne ou reposent sur des règles manuelles nécessitant un savoir‑faire approfondi. D’autres utilisent des modèles profonds lourds qui donnent de bons résultats en laboratoire mais sont difficiles à exécuter en temps réel sur du matériel industriel aux capacités limitées. En conséquence, les usines peinent souvent à transformer des données brutes de capteurs en alertes de panne opportunes et fiables.
Comment le nouveau cadre observe les données
Les auteurs proposent un cadre optimisé de détection des pannes adapté aux équipements connectés en IoT. Ils collectent d’abord des données en temps réel dans un dispositif contrôlé mais réaliste où des capteurs suivent la tension, la vitesse, les vibrations, la température et la pression sur des équipements rotatifs. Chaque mesure est horodatée avec précision, ce qui permet au système d’examiner l’évolution de chaque grandeur dans le temps. Les données brutes passent ensuite par une étape de nettoyage soignée : les valeurs manquantes sont traitées, les mesures sont standardisées sur une échelle commune, et de larges catégories de défauts telles que très faible, faible, normal, élevé et très élevé sont attribuées en s’appuyant sur le savoir‑faire des ingénieurs. Ces catégories reflètent la manière dont le personnel de maintenance considère les limites d’exploitation et aident le modèle à relier des valeurs numériques à des états machine significatifs.
Sélection des signaux les plus parlants
Plutôt que d’alimenter l’algorithme d’apprentissage avec chaque valeur brute de capteur, le cadre sélectionne et reformate les données en deux étapes clés. D’abord, un sélecteur de caractéristiques par étapes examine chaque type de capteur en relation avec le temps — par exemple la tension par rapport à l’horodatage, ou les vibrations par rapport au temps. Pour chaque paire, il concentre l’attention sur des plages connues pour être à risque, comme une vitesse anormalement basse ou une température anormalement élevée. Cela réduit le bruit et met en avant les portions des données les plus susceptibles de contenir des signes de problème. Ensuite, une version améliorée d’une technique classique, l’analyse en composantes principales, est utilisée pour séparer les motifs habituels des comportements anormaux. Cette méthode, appelée analyse en composantes principales robuste, divise les données en un fond lisse représentant le fonctionnement normal et une composante parcimonieuse faite de pics et de sauts suggérant des pannes ou des anomalies. Une étape d’ajustement interne module l’équilibre entre ces deux composantes, améliorant la clarté de la séparation.
Combiner des apprenants simples pour des décisions plus solides
Une fois les données distillées en caractéristiques informatives, le cadre recourt à un ensemble de deux méthodes d’apprentissage automatique. L’une, connue sous le nom de k plus proches voisins, recherche des groupes de cas passés qui ressemblent étroitement à une nouvelle situation et vote en fonction de ce qui est arrivé auparavant. L’autre, AdaBoost, construit une série de règles de décision simples en accordant plus d’attention aux exemples mal classés par les règles précédentes. Leurs sorties sont ensuite combinées par un vote pondéré, de sorte que chaque méthode apporte ses points forts : la sensibilité locale du modèle fondé sur les voisins et l’attention ciblée aux cas difficiles du modèle de boosting. Pour éviter les tâtonnements dans le réglage des nombreux paramètres internes de ces apprenants, les auteurs utilisent l’optimisation bayésienne, une stratégie qui cherche automatiquement des combinaisons de paramètres offrant les meilleures performances globales avec relativement peu d’essais.
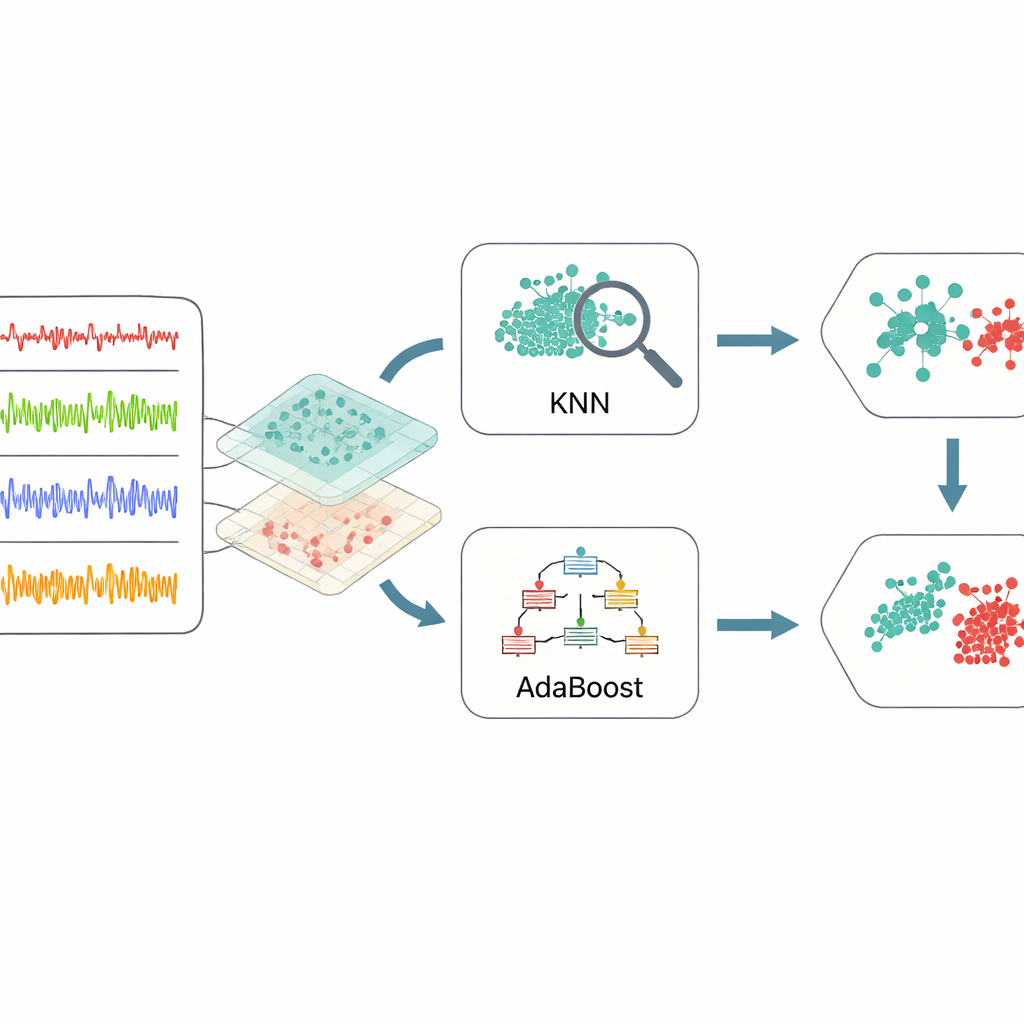
Ce que montrent les expériences
L’équipe de recherche a testé son cadre sur des milliers d’enregistrements de capteurs issus du dispositif IoT simulé. Ils l’ont comparé à un large éventail de techniques standard, des arbres de décision et forêts aléatoires aux réseaux neuronaux et autres modèles ensemblistes. Sur des mesures qui importent le plus pour la maintenance — la précision globale, la fréquence de détection des vraies pannes et la rareté des cas manqués — la nouvelle méthode s’est systématiquement imposée. Elle a identifié correctement les conditions de panne liées à la tension, aux vibrations, à la vitesse et à la température avec une précision proche de 99 % et un taux de pannes manquées très faible. Des tests statistiques sur des cycles répétés d’entraînement et de test ont montré que ces gains sont peu susceptibles d’être dus au hasard. Parallèlement, la méthode demeure peu coûteuse en calcul, la rendant plus adaptée au déploiement sur du matériel d’atelier que nombre d’alternatives reposant sur l’apprentissage profond.
Ce que cela signifie pour les usines réelles
Concrètement, l’étude montre que nettoyer et reformater soigneusement les données de capteurs, puis combiner intelligemment deux outils d’apprentissage modestes, peut égaler ou dépasser des approches plus complexes de détection de pannes. Pour les responsables d’usine, cela peut se traduire par des alertes plus précoces lorsque des moteurs commencent à surchauffer, lorsque des vibrations indiquent une usure de roulement, ou lorsque des dysfonctionnements d’alimentation menacent des équipements sensibles. Moins de pannes manquées signifie moins de pannes surprises, tandis qu’un faible taux de fausses alertes empêche les équipes de maintenance de courir après des problèmes inexistants. Bien que le travail soit basé sur des données simulées mais réalistes, les auteurs soutiennent que le cadre est prêt à être testé sur des systèmes industriels en fonctionnement et pourrait constituer l’épine dorsale d’une maintenance prédictive plus transparente et rentable dans les usines IoT de demain.
Citation: Devi Gayadri, S.V., Kanagaraj, G., Giri, J. et al. An optimized ensemble framework for machinery fault detection in IoT environments. Sci Rep 16, 10357 (2026). https://doi.org/10.1038/s41598-026-40335-7
Mots-clés: équipements IoT, détection de pannes, apprentissage automatique, capteurs industriels, maintenance prédictive