Clear Sky Science · ru
Оптимизированная ансамблевая схема для обнаружения неисправностей оборудования в средах IoT
Как не допустить отказов заводских машин
Современные фабрики всё чаще полагаются на сети «умных» датчиков, чтобы поддерживать оборудование в рабочем состоянии. Несмотря на обилие данных, неожиданные поломки всё ещё происходят, отнимая время и деньги. В этом исследовании рассматривается новый способ анализа потоков показаний датчиков — таких как температура, вибрация, скорость и напряжение — для раннего выявления признаков неисправностей в промышленном оборудовании, подключённом через Интернет вещей (IoT). Цель проста, но важна: обнаруживать неисправности раньше, надёжнее и с меньшими затратами вычислительных ресурсов, чтобы существенно сократить простои.
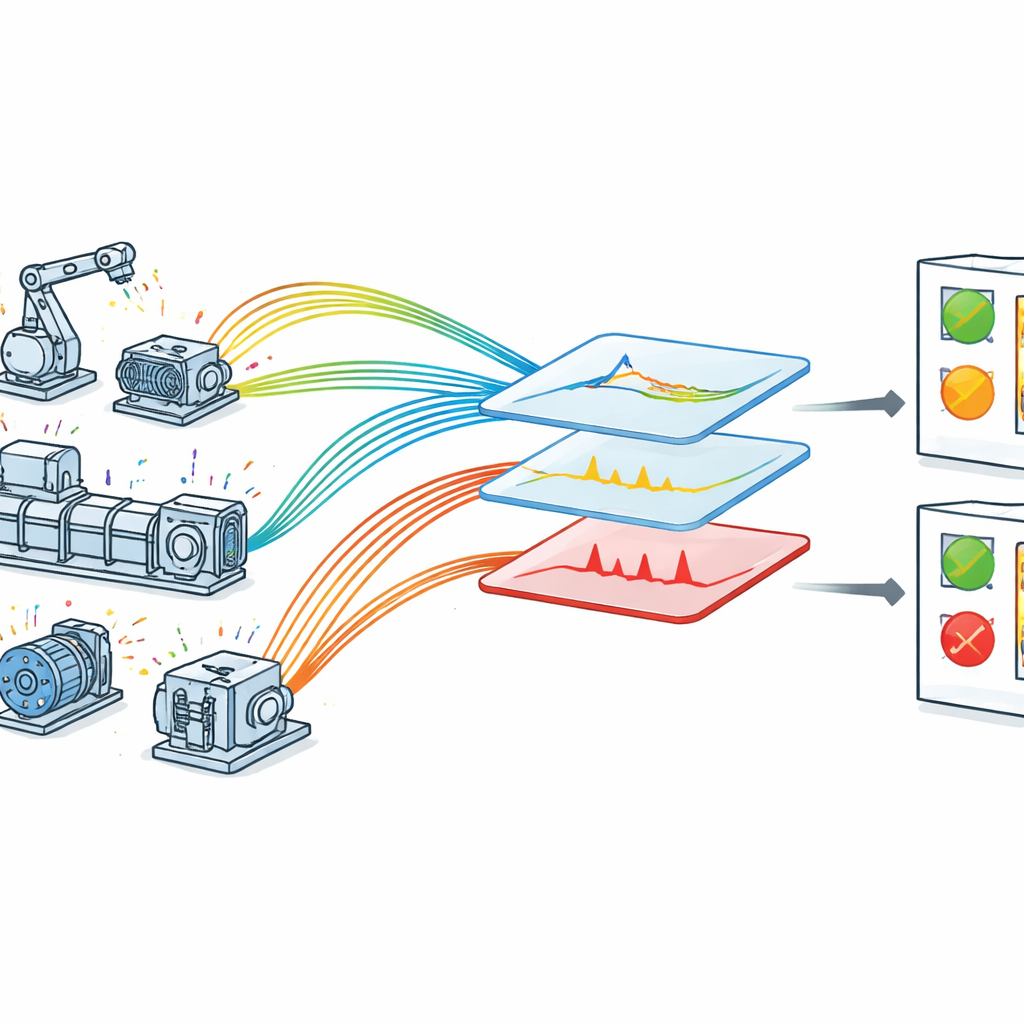
Почему наблюдение за машинами сложно
В цехе с оборудованием IoT у каждой ключевой машины установлены датчики, которые постоянно присылают числовые данные о её состоянии. Теоретически это должно упростить выявление проблем до того, как они перерастут в отказы. На практике данные шумные: показания могут быть неточными, модели поведения меняются с изменением условий эксплуатации, а важные сигналы могут прятаться среди рутинных колебаний. Многие существующие подходы ориентированы на один тип неисправности или завязаны на вручную разработанных правилах, требующих глубоких экспертных знаний. Другие используют тяжёлые модели глубокого обучения, которые хорошо работают в лаборатории, но их трудно запускать в реальном времени на промышленном оборудовании с ограниченными вычислительными ресурсами. В результате заводы часто не в состоянии превратить сырые данные датчиков в своевременные и надёжные сигналы тревоги.
Как новая схема отслеживает данные
Авторы предлагают оптимизированную схему обнаружения неисправностей, адаптированную для машин в средах IoT. Сначала они собирают данные в реальном времени в контролируемой, но реалистичной установке, где датчики отслеживают напряжение, скорость, вибрацию, температуру и давление на вращающемся оборудовании. Каждое измерение снабжено точной временной меткой, что позволяет системе анализировать изменение каждой величины во времени. Сырые данные затем проходят этап тщательной очистки: пропуски заполняются, показания стандартизируются до общего масштаба, а с использованием инженерной экспертизы присваиваются широкие категории состояния, такие как очень низкое, низкое, нормальное, высокое и очень высокое. Эти категории отражают то, как обслуживающий персонал мыслит о пределах эксплуатации, и помогают модели соотнести численные значения с осмысленными состояниями машины.
Выделение наиболее информативных сигналов
Вместо того чтобы подавать в алгоритм обучения все сырые показания датчиков, схема отбирает и преобразует данные в два ключевых шага. Сначала пошаговый селектор признаков анализирует каждый тип датчика совместно со временем — например, напряжение относительно временной метки или вибрация относительно временной метки. Для каждой пары он сосредотачивается на диапазонах, известных как рискованные, таких как необычно низкая скорость или чрезмерно высокая температура. Это уменьшает шум и подчёркивает участки данных, где наиболее вероятно появление признаков неисправностей. Затем применяется улучшенная версия классического метода главных компонент для разделения обычных паттернов и аномалий. Этот метод, называемый робастным методом главных компонент, разделяет данные на гладкий фон, представляющий нормальную работу, и разреженную последовательность скачков и всплесков, указывающих на неисправности или аномалии. Внутренний этап настройки регулирует степень баланса между этими двумя компонентами, повышая чёткость разделения.
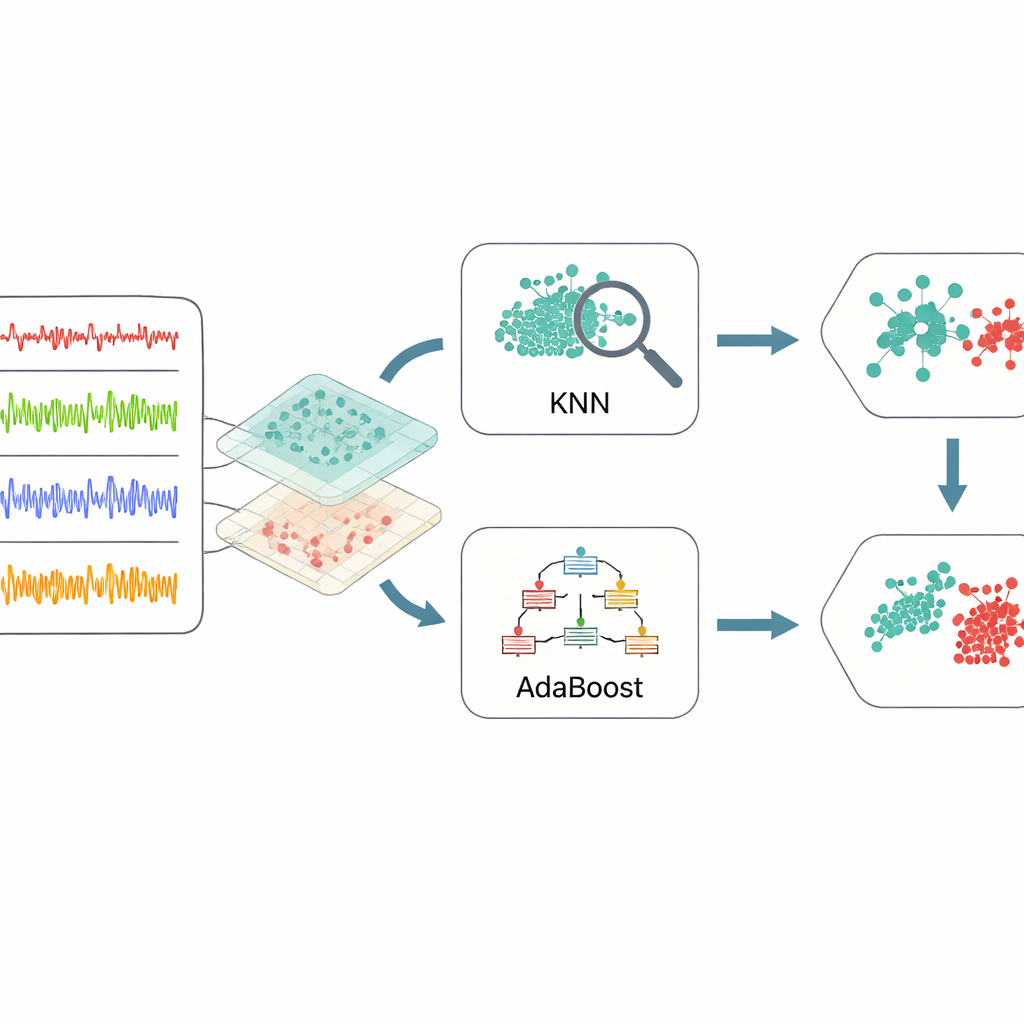
Комбинирование простых моделей для более надёжных решений
После того как данные были превращены в информативные признаки, схема использует ансамбль из двух методов машинного обучения. Первый, k ближайших соседей, ищет группы прошлых случаев, близких к новой ситуации, и голосует, исходя из того, что случалось раньше. Второй, AdaBoost, последовательно собирает простые решающие правила, уделяя больше внимания примерам, которые предыдущие правила ошибочно классифицировали. Их результаты затем объединяются с помощью взвешенного голосования, чтобы каждый метод вносил свои достоинства: локальную чувствительность от модели на основе соседей и фокусировку на труднодетектируемых случаях от бустинга. Чтобы избежать догадок при настройке многочисленных внутренних параметров этих моделей, авторы применяют байесовскую оптимизацию — стратегию, автоматически ищущую комбинации параметров, дающие наилучшее общее качество при относительно небольшом числе испытаний.
Что показали эксперименты
Исследовательская команда протестировала свою схему на тысячах записей датчиков, полученных из смоделированной установки IoT для промышленного оборудования. Они сравнили её с широким набором стандартных методов — от деревьев решений и случайных лесов до нейронных сетей и других ансамблевых моделей. По ключевым метрикам для обслуживания — общей точности, частоте правильного обнаружения реальных неисправностей и редкости пропусков истинных проблем — новый метод последовательно показывал лучшие результаты. Он корректно выявлял условия неисправностей, связанные с напряжением, вибрацией, скоростью и температурой, с точностью около 99% и очень низким уровнем пропусков. Статистические тесты на повторяющихся циклах обучения и тестирования показали, что эти улучшения вряд ли случаются случайно. При этом метод оставался экономным в вычислениях, что делает его более пригодным для развёртывания на промышленном оборудовании по сравнению со многими альтернативами на основе глубокого обучения.
Что это значит для реальных заводов
Проще говоря, исследование показывает: тщательная очистка и преобразование данных датчиков, а затем умное сочетание двух умеренно сложных методов обучения может соперничать или превосходить более сложные подходы к обнаружению неисправностей. Для операторов предприятий это может означать более ранние предупреждения о перегреве двигателей, вибрации, указывающей на износ подшипников, или сбоях питания, угрожающих чувствительному оборудованию. Меньше пропущенных неисправностей — меньше неожиданных поломок, а низкий уровень ложных срабатываний сохраняет ресурсы сервисных команд. Хотя работа основана на смоделированных, но реалистичных данных, авторы утверждают, что схема готова к испытаниям на реальных промышленных системах и может стать основой более прозрачного и экономичного предиктивного обслуживания на будущих заводах с поддержкой IoT.
Цитирование: Devi Gayadri, S.V., Kanagaraj, G., Giri, J. et al. An optimized ensemble framework for machinery fault detection in IoT environments. Sci Rep 16, 10357 (2026). https://doi.org/10.1038/s41598-026-40335-7
Ключевые слова: IoT оборудование, обнаружение неисправностей, машинное обучение, промышленные датчики, предиктивное обслуживание