Clear Sky Science · it
Un framework ensemble ottimizzato per il rilevamento dei guasti nelle macchine in ambienti IoT
Proteggere le macchine di fabbrica dai guasti
Le fabbriche moderne si affidano sempre più a reti di sensori intelligenti per mantenere le macchine in funzione. Eppure, nonostante l’abbondanza di dati, i guasti imprevisti continuano a verificarsi, con costi importanti in termini di tempo e denaro. Questo studio esplora un nuovo metodo per setacciare i flussi di letture dei sensori — come temperatura, vibrazione, velocità e tensione — per individuare segnali di allarme precoci nelle macchine industriali connesse tramite Internet of Things (IoT). L’obiettivo è semplice ma potente: rilevare i guasti prima, in modo più affidabile e con minore impegno di calcolo, così da ridurre sensibilmente i tempi di fermo.
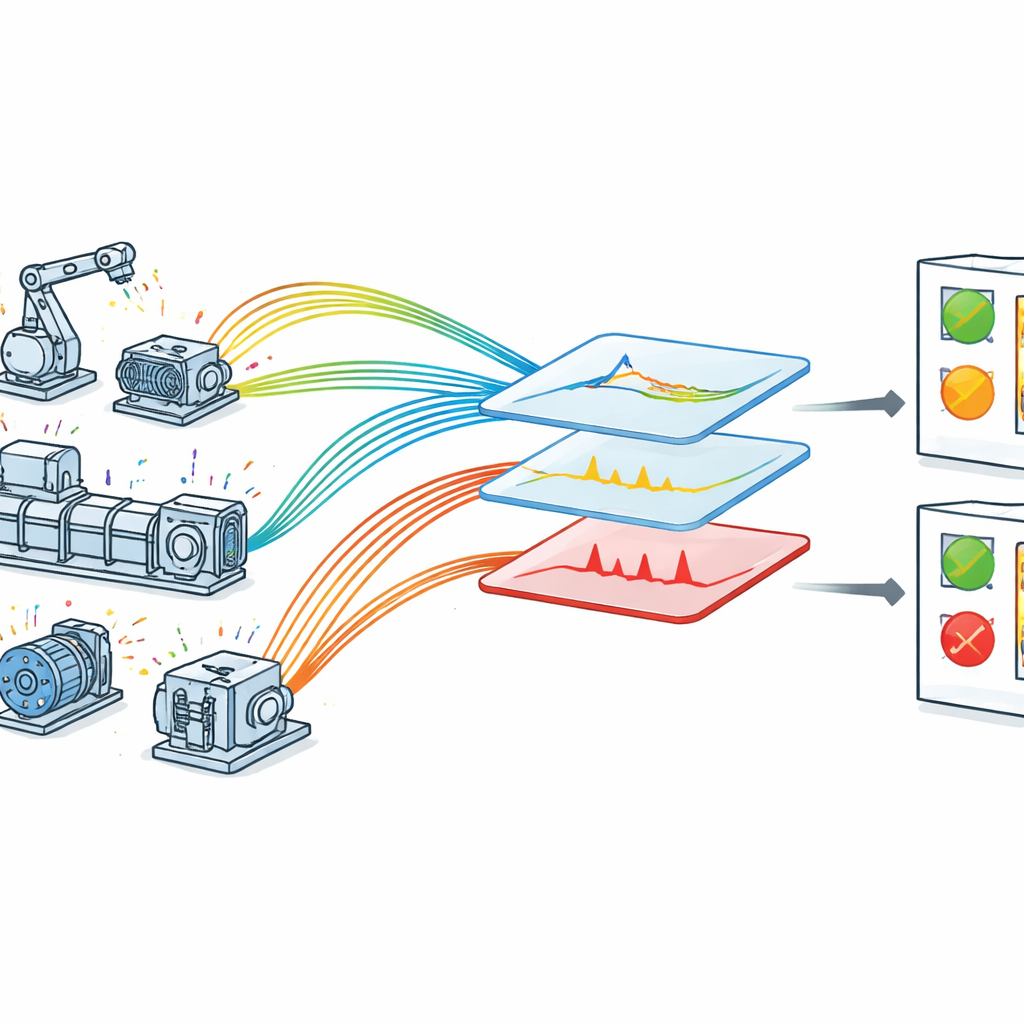
Perché osservare le macchine è difficile
In una fabbrica dotata di IoT, ogni macchina chiave è equipaggiata con sensori che inviano costantemente valori sul suo funzionamento. In teoria, questo dovrebbe rendere semplice intercettare i problemi prima che diventino guasti. In pratica, i dati sono disordinati: le letture possono essere rumorose, i pattern cambiano con le condizioni operative e segnali importanti possono essere sepolti in mezzo a fluttuazioni di routine. Molti approcci esistenti si concentrano su un solo tipo di guasto o dipendono da regole costruite a mano che richiedono competenze esperte. Altri utilizzano pesanti modelli di deep learning che funzionano bene in laboratorio ma sono difficili da eseguire in tempo reale su hardware industriale con potenza di calcolo limitata. Di conseguenza, le fabbriche spesso faticano a trasformare i dati grezzi dei sensori in avvisi di guasto tempestivi e affidabili.
Come il nuovo framework osserva i dati
Gli autori propongono un framework di rilevamento dei guasti ottimizzato e pensato per macchinari abilitati all’IoT. Per prima cosa raccolgono dati in tempo reale in un ambiente controllato ma realistico, dove i sensori monitorano tensione, velocità, vibrazione, temperatura e pressione su apparecchiature rotanti. Ogni lettura è associata a un timestamp preciso, permettendo al sistema di esaminare come ciascuna quantità varia nel tempo. I dati grezzi passano poi attraverso una fase accurata di pulizia: i valori mancanti vengono gestiti, le letture vengono standardizzate su una scala comune e si assegnano categorie ampie di stato — molto basso, basso, normale, alto e molto alto — utilizzando conoscenze ingegneristiche. Queste categorie rispecchiano il modo in cui il personale di manutenzione pensa ai limiti operativi e aiutano il modello a collegare i valori numerici a stati macchina significativi.
Selezionare i segnali più rivelatori
Piuttosto che immettere ogni valore grezzo in un algoritmo di apprendimento, il framework seleziona e rimodella i dati in due passaggi chiave. Primo, un selettore di caratteristiche per fasi esamina ogni tipo di sensore affiancato al tempo — per esempio, tensione rispetto al timestamp, o vibrazione rispetto al timestamp. Per ciascuna coppia, si concentra su intervalli noti come rischiosi, come velocità insolitamente bassa o temperatura insolitamente alta. Questo riduce il rumore e mette in evidenza le porzioni di dati più probabili a contenere segnali di guasto. Secondo, si utilizza una versione migliorata di una tecnica classica chiamata analisi delle componenti principali per separare i pattern usuali dai comportamenti anomali. Questo metodo, chiamato analisi robusta delle componenti principali, divide i dati in uno sfondo liscio che rappresenta il funzionamento normale e in una collezione sparsa di picchi e salti che suggeriscono guasti o anomalie. Un passaggio di taratura interno regola quanto vigorosamente il metodo bilancia queste due componenti, migliorando la chiarezza della separazione.
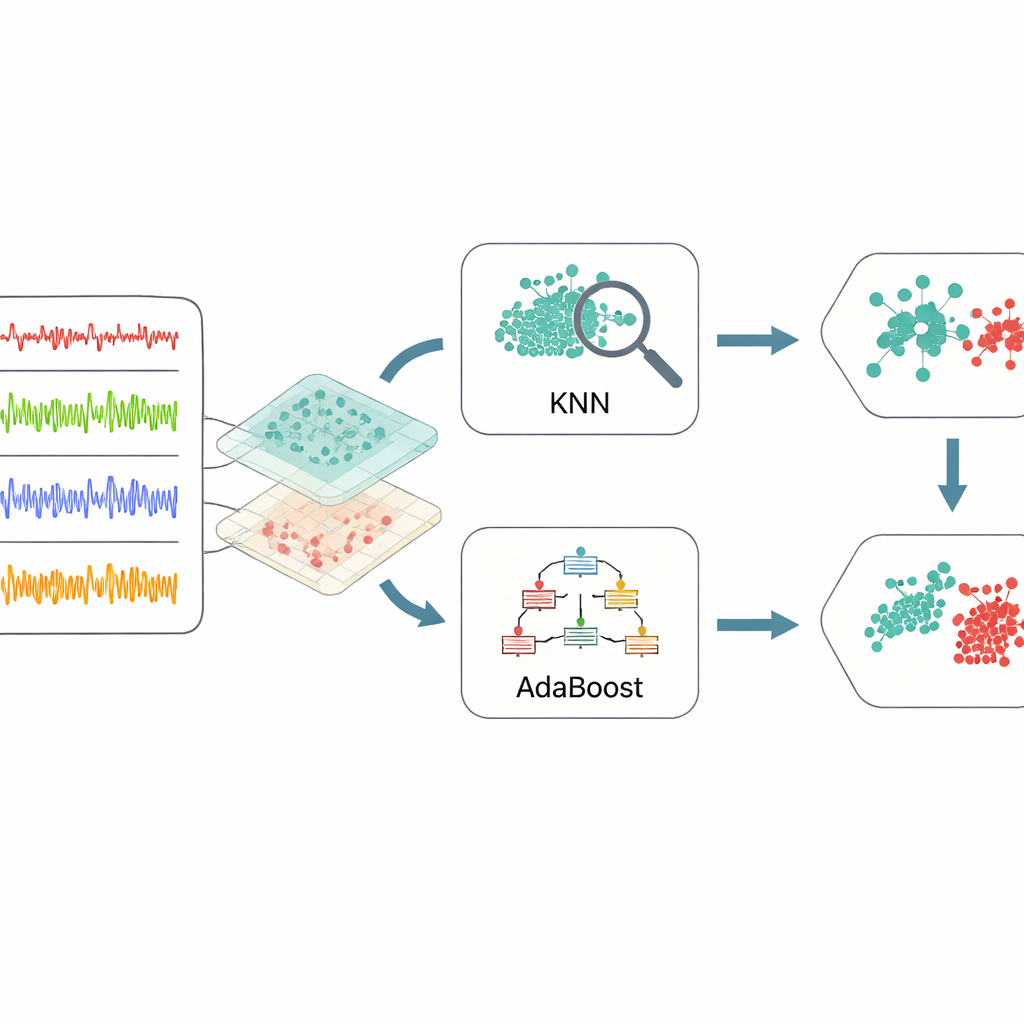
Combinare apprenditori semplici per decisioni più forti
Una volta che i dati sono stati distillati in queste caratteristiche informative, il framework si affida a un ensemble composto da due metodi di machine learning. Uno, noto come k-nearest neighbors, cerca gruppi di casi passati che somigliano molto a una nuova situazione e vota in base a cosa è accaduto prima. L’altro, AdaBoost, costruisce una serie di regole decisionali semplici, prestando maggiore attenzione agli esempi che le regole precedenti hanno classificato in modo errato. Le loro uscite vengono poi combinate tramite un voto pesato, in modo che ciascun metodo apporti i propri punti di forza: sensibilità locale dal modello basato sui vicini e attenzione mirata ai casi difficili dal modello di boosting. Per evitare congetture nella regolazione delle numerose impostazioni interne di questi classificatori, gli autori utilizzano l’ottimizzazione bayesiana, una strategia che cerca automaticamente combinazioni di parametri che forniscano le migliori prestazioni complessive con relativamente pochi tentativi.
Cosa mostrano gli esperimenti
Il team di ricerca ha testato il framework su migliaia di registrazioni dei sensori tratte dal setup simulato di macchinari IoT. Lo hanno confrontato con un’ampia gamma di tecniche standard, dagli alberi decisionali e foreste casuali alle reti neurali e ad altri modelli ensemble. Sulle metriche più rilevanti per la manutenzione — accuratezza complessiva, frequenza con cui i guasti reali vengono correttamente rilevati e basso tasso di guasti non individuati — il nuovo metodo ha costantemente ottenuto i risultati migliori. Ha identificato correttamente condizioni di guasto legate a tensione, vibrazione, velocità e temperatura con un’accuratezza prossima al 99% e un tasso molto basso di guasti non rilevati. Test statistici su ripetuti cicli di addestramento e verifica hanno mostrato che questi miglioramenti sono improbabili dovuti al caso. Contemporaneamente, il metodo è rimasto leggero dal punto di vista computazionale, rendendolo più adatto per il deployment su hardware di fabbrica rispetto a molte alternative basate sul deep learning.
Cosa significa per le fabbriche reali
In termini pratici, lo studio dimostra che pulire e rimodellare con cura i dati dei sensori e poi combinare in modo intelligente due strumenti di apprendimento modesti può eguagliare o superare approcci più complessi al rilevamento dei guasti delle macchine. Per gli operatori di impianto, questo si può tradurre in allarmi più precoci quando i motori iniziano a surriscaldarsi, quando la vibrazione indica usura dei cuscinetti o quando anomalie nell’alimentazione elettrica minacciano apparecchiature sensibili. Meno guasti non rilevati significano meno fermate impreviste, mentre un basso tasso di falsi allarmi evita che i team di manutenzione inseguano falsi indizi. Sebbene il lavoro si basi su dati simulati ma realistici, gli autori sostengono che il framework è pronto per essere testato su sistemi industriali reali e potrebbe costituire la spina dorsale di una manutenzione predittiva più trasparente ed economica nelle fabbriche IoT del futuro.
Citazione: Devi Gayadri, S.V., Kanagaraj, G., Giri, J. et al. An optimized ensemble framework for machinery fault detection in IoT environments. Sci Rep 16, 10357 (2026). https://doi.org/10.1038/s41598-026-40335-7
Parole chiave: macchinari IoT, rilevamento guasti, apprendimento automatico, sensori industriali, manutenzione predittiva