Clear Sky Science · es
Un marco de ensamble optimizado para la detección de fallos en maquinaria en entornos IoT
Evitar que las máquinas de la fábrica fallen
Las fábricas modernas dependen cada vez más de redes de sensores inteligentes para mantener sus máquinas en funcionamiento. Sin embargo, aun con todos esos datos, siguen ocurriendo averías imprevistas que cuestan tiempo y dinero. Este estudio explora una nueva forma de procesar flujos de lecturas de sensores —como temperatura, vibración, velocidad y voltaje— para detectar las señales tempranas de problemas en máquinas industriales conectadas mediante el Internet de las Cosas (IoT). El objetivo es simple pero potente: detectar fallos antes, con mayor fiabilidad y con menos esfuerzo computacional, de modo que se reduzcan drásticamente los tiempos de inactividad.
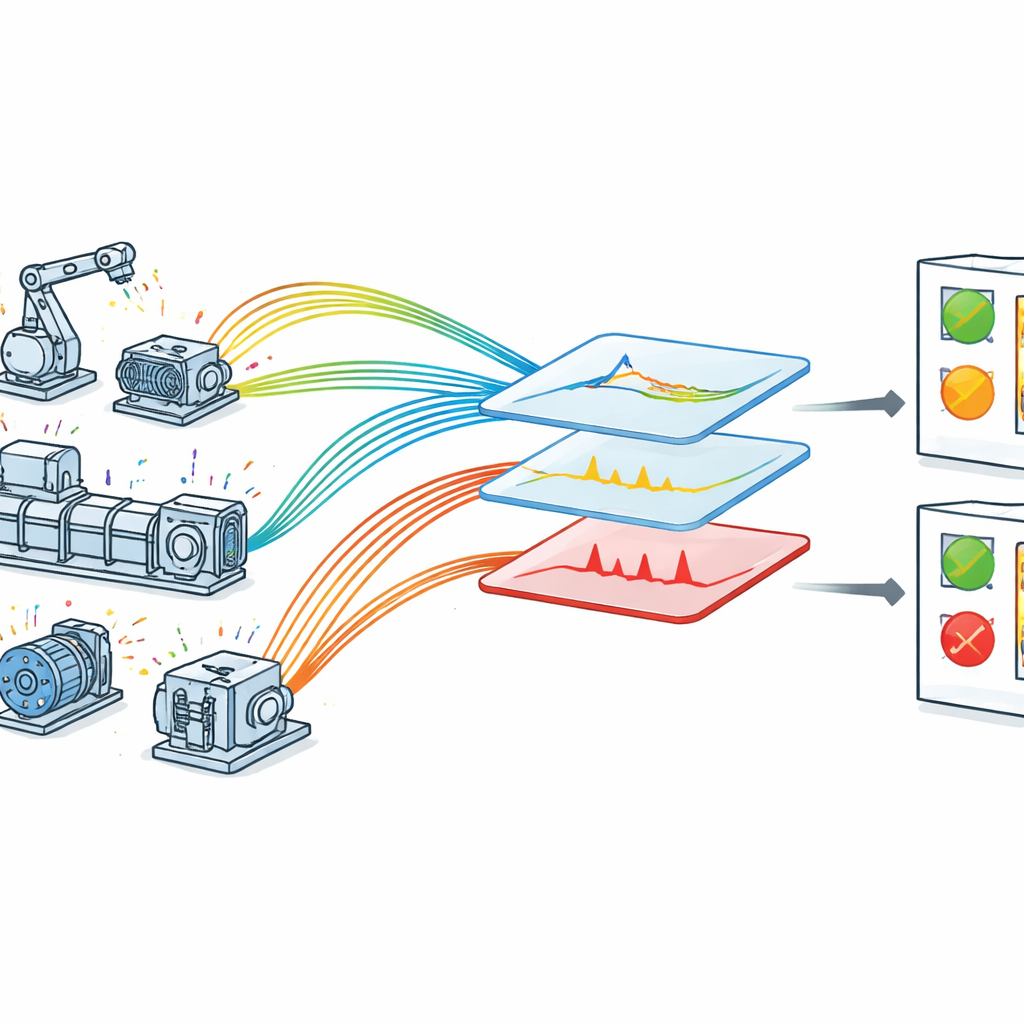
Por qué es difícil vigilar las máquinas
En una fábrica equipada con IoT, cada máquina clave se equipa con sensores que envían continuamente datos sobre su comportamiento. En teoría, esto debería facilitar la detección de problemas antes de que se conviertan en fallos. En la práctica, los datos son desordenados: las lecturas pueden tener ruido, los patrones cambian según las condiciones de operación y las señales importantes pueden enterrarse entre fluctuaciones rutinarias. Muchos enfoques existentes se centran en un único tipo de fallo o dependen de reglas diseñadas a mano que requieren un profundo conocimiento experto. Otros emplean modelos pesados de aprendizaje profundo que funcionan bien en el laboratorio pero son difíciles de ejecutar en tiempo real en hardware industrial con recursos limitados. Como resultado, las fábricas suelen tener problemas para transformar datos brutos de sensores en alertas de fallo oportunas y fiables.
Cómo el nuevo marco vigila los datos
Los autores proponen un marco optimizado de detección de fallos adaptado a maquinaria con capacidad IoT. Primero recogen datos en tiempo real en un entorno controlado pero realista donde los sensores registran voltaje, velocidad, vibración, temperatura y presión en equipos rotativos. Cada lectura se etiqueta con una marca de tiempo precisa, lo que permite al sistema examinar cómo cambia cada magnitud a lo largo del tiempo. Los datos brutos pasan luego por una fase de limpieza cuidadosa: se manejan los valores faltantes, las lecturas se estandarizan a una escala común y se asignan categorías amplias de fallo —muy bajo, bajo, normal, alto y muy alto— usando conocimiento de ingeniería. Estas categorías reflejan cómo piensa el personal de mantenimiento sobre los límites de operación y ayudan al modelo a conectar valores numéricos con estados de máquina significativos.
Seleccionar las señales más reveladoras
En lugar de introducir cada valor crudo de sensor en un algoritmo de aprendizaje, el marco selecciona y transforma los datos en dos pasos clave. Primero, un selector de características por etapas examina cada tipo de sensor junto con el tiempo —por ejemplo, voltaje frente a marca temporal, o vibración frente a marca temporal. Para cada par, se centra en rangos conocidos por ser riesgosos, como velocidades inusualmente bajas o temperaturas inusualmente altas. Esto reduce el ruido y enfatiza las porciones de datos que probablemente contengan señales de problemas. Segundo, se utiliza una versión mejorada de una técnica clásica llamada análisis de componentes principales para separar los patrones habituales del comportamiento anómalo. Este método, denominado análisis de componentes principales robusto, divide los datos en un fondo suave que representa la operación normal y una colección escasa de picos y saltos que sugieren fallos o anomalías. Un ajuste interno regula la fuerza con la que el método equilibra estas dos partes, mejorando la claridad de la separación.
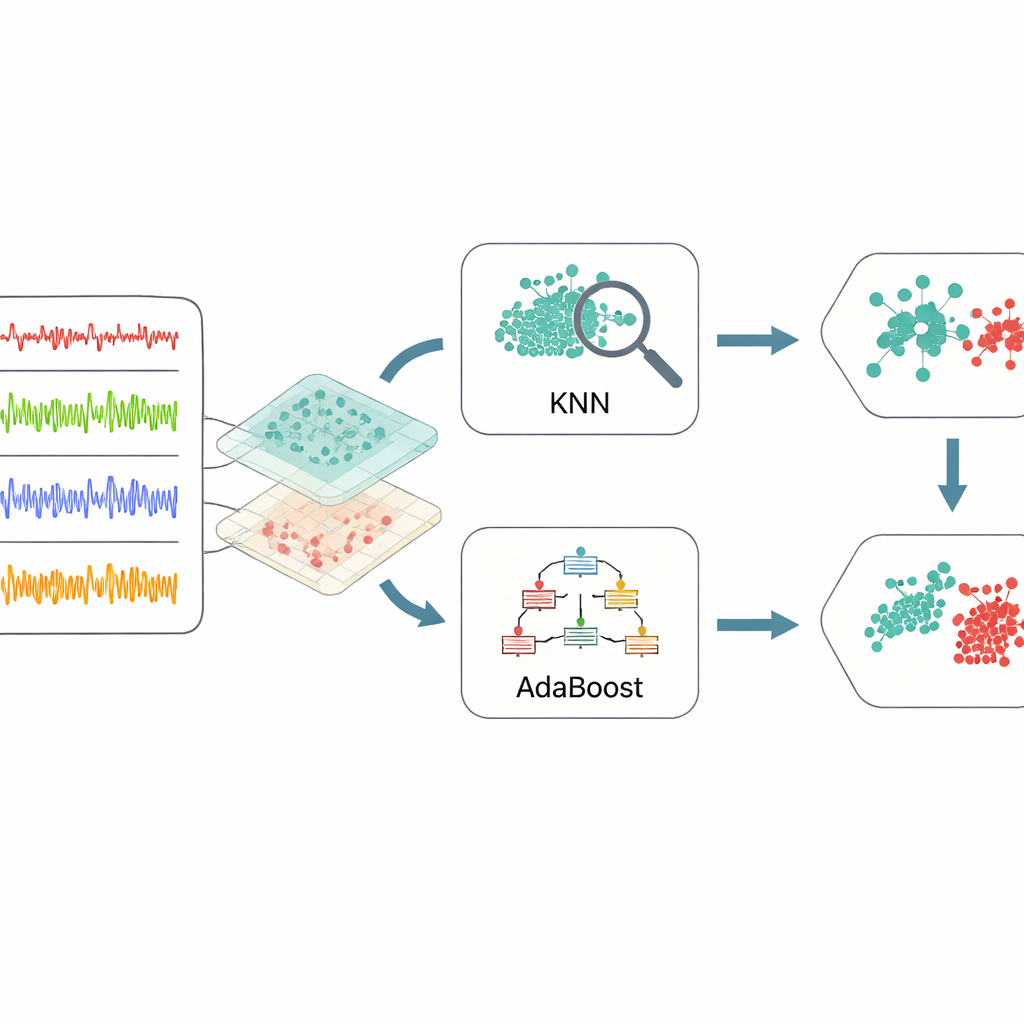
Combinar aprendices sencillos para decisiones más sólidas
Una vez que los datos se han destilado en estas características informativas, el marco recurre a un ensamble de dos métodos de aprendizaje automático. Uno, conocido como k-vecinos más cercanos, busca conjuntos de casos pasados que se parezcan mucho a una nueva situación y vota según lo que ocurrió antes. El otro, AdaBoost, construye una serie de reglas de decisión simples, prestando atención adicional a los ejemplos que las reglas anteriores clasificaron mal. Sus salidas se combinan mediante un proceso de votación ponderada, de modo que cada método aporta sus fortalezas: sensibilidad local por parte del modelo basado en vecinos y atención focalizada sobre casos difíciles de detectar por parte del modelo de boosting. Para evitar conjeturas al ajustar los numerosos parámetros internos de estos aprendices, los autores emplean optimización bayesiana, una estrategia que busca automáticamente combinaciones de ajustes que ofrecen el mejor rendimiento global con relativamente pocas pruebas.
Qué muestran los experimentos
El equipo de investigación probó su marco con miles de registros de sensores extraídos del entorno simulado de maquinaria IoT. Lo compararon con una amplia gama de técnicas estándar, desde árboles de decisión y bosques aleatorios hasta redes neuronales y otros modelos en ensamblaje. En medidas que importan en mantenimiento —precisión global, frecuencia con la que se detectan correctamente los fallos reales y la tasa de fallos no detectados—, el nuevo método obtuvo resultados superiores de forma consistente. Identificó correctamente condiciones de fallo vinculadas a voltaje, vibración, velocidad y temperatura con una precisión cercana al 99% y una tasa muy baja de fallos no detectados. Pruebas estadísticas a lo largo de ciclos repetidos de entrenamiento y prueba mostraron que estas mejoras probablemente no se deben al azar. Al mismo tiempo, el método sigue siendo computacionalmente ligero, lo que lo hace más adecuado para su despliegue en hardware de planta que muchas alternativas basadas en aprendizaje profundo.
Qué significa esto para las fábricas reales
En términos prácticos, el estudio demuestra que limpiar y transformar cuidadosamente los datos de sensores y luego combinar dos herramientas de aprendizaje modestas de forma inteligente puede igualar o superar enfoques más complejos para la detección de fallos en máquinas. Para los operadores de planta, esto podría traducirse en alertas más tempranas cuando los motores empiezan a sobrecalentarse, cuando la vibración indica desgaste de rodamientos o cuando las fluctuaciones de suministro eléctrico amenazan equipos sensibles. Menos fallos no detectados significan menos averías sorpresa, mientras que una baja tasa de falsas alarmas evita que los equipos de mantenimiento persigan problemas inexistentes. Aunque el trabajo se basa en datos simulados pero realistas, los autores sostienen que el marco está listo para probarse en sistemas industriales reales y podría constituir la columna vertebral de un mantenimiento predictivo más transparente y rentable en futuras fábricas habilitadas para IoT.
Cita: Devi Gayadri, S.V., Kanagaraj, G., Giri, J. et al. An optimized ensemble framework for machinery fault detection in IoT environments. Sci Rep 16, 10357 (2026). https://doi.org/10.1038/s41598-026-40335-7
Palabras clave: maquinaria IoT, detección de fallos, aprendizaje automático, sensores industriales, mantenimiento predictivo