Clear Sky Science · de
Ein optimiertes Ensemble-Framework zur Fehlererkennung in Maschinen in IoT-Umgebungen
Wie man Fabrikmaschinen am Ausfallen hindert
Moderne Fabriken verlassen sich zunehmend auf Netzwerke intelligenter Sensoren, um ihre Maschinen reibungslos am Laufen zu halten. Trotzdem treten trotz all dieser Daten unerwartete Ausfälle auf, die Zeit und Geld kosten. Diese Studie untersucht einen neuen Ansatz, um Sensor-Datenströme — etwa zu Temperatur, Vibration, Drehzahl und Spannung — zu durchsieben und frühe Warnsignale für Probleme in industriegerechten Maschinen zu erkennen, die über das Internet der Dinge (IoT) vernetzt sind. Das Ziel ist einfach, aber wirkungsvoll: Fehler früher, zuverlässiger und mit geringerem Rechenaufwand zu erkennen, damit Ausfallzeiten deutlich reduziert werden können.
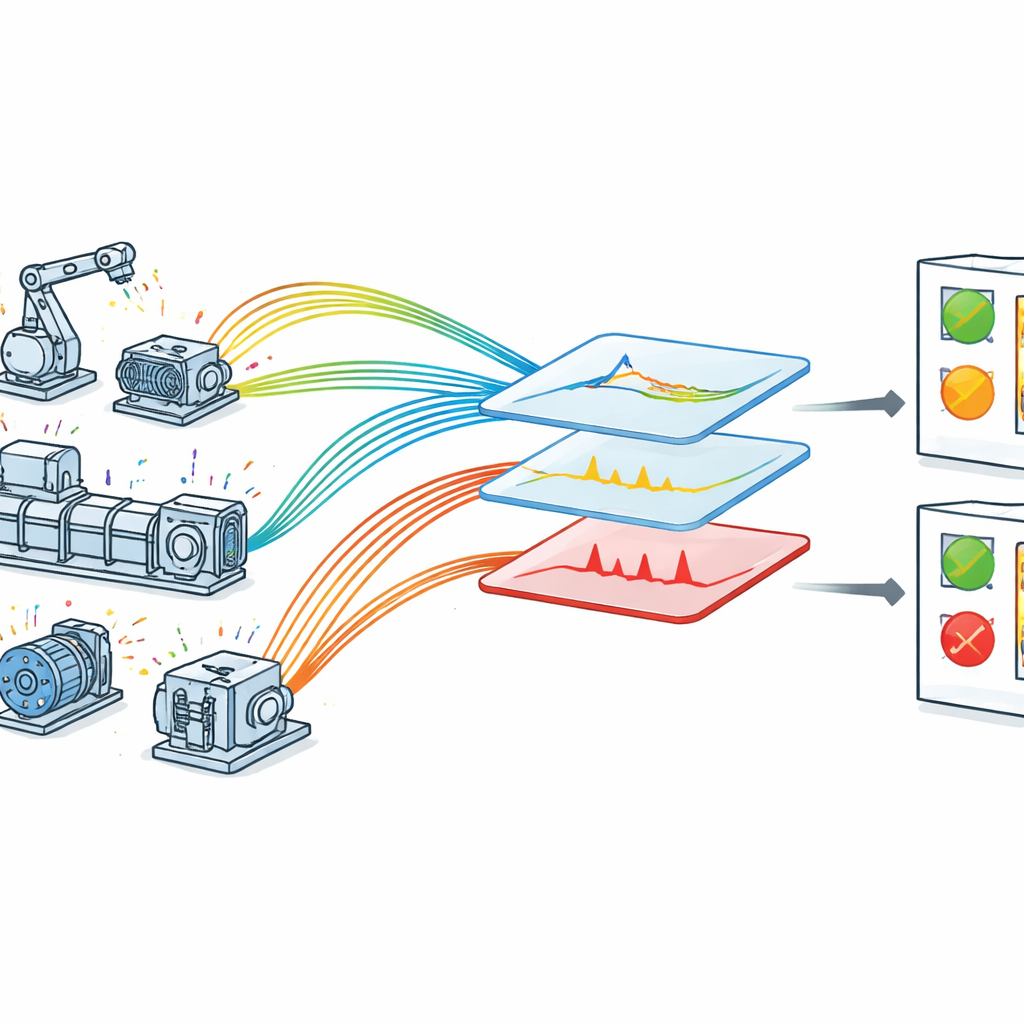
Warum das Überwachen von Maschinen schwierig ist
In einer IoT-ausgerüsteten Fabrik ist jede wichtige Maschine mit Sensoren versehen, die laufend Messwerte über ihr Verhalten zurückmelden. Theoretisch sollte sich so leicht verhindern lassen, dass Probleme zu Ausfällen werden. Praktisch sind die Daten jedoch unordentlich: Messwerte können verrauscht sein, Muster ändern sich mit den Betriebsbedingungen und relevante Signale können in routinemäßigen Schwankungen untergehen. Viele vorhandene Ansätze konzentrieren sich nur auf einen Fehlertyp oder basieren auf handgefertigten Regeln, die tiefes Expertenwissen erfordern. Andere nutzen schwere Deep-Learning-Modelle, die im Labor gut funktionieren, aber schwer in Echtzeit auf Industriehardware mit begrenzter Rechenleistung einsetzbar sind. Infolgedessen haben Fabriken oft Schwierigkeiten, rohe Sensordaten in zeitnahe, vertrauenswürdige Fehlerwarnungen zu verwandeln.
Wie das neue Framework die Daten beobachtet
Die Autoren schlagen ein optimiertes Fehlererkennungs-Framework vor, das auf IoT-fähige Maschinen zugeschnitten ist. Zunächst sammeln sie Echtzeitdaten in einem kontrollierten, aber realistischen Aufbau, in dem Sensoren Spannung, Drehzahl, Vibration, Temperatur und Druck an rotierenden Komponenten überwachen. Jede Messung wird mit einem präzisen Zeitstempel versehen, sodass das System untersuchen kann, wie sich jede Größe über die Zeit verändert. Die Rohdaten durchlaufen dann eine sorgfältige Bereinigungsphase: Fehlende Werte werden behandelt, Messwerte auf eine gemeinsame Skala standardisiert und breite Fehlerkategorien wie sehr niedrig, niedrig, normal, hoch und sehr hoch mithilfe ingenieurtechnischen Wissens zugewiesen. Diese Kategorien spiegeln wider, wie Wartungspersonal über Betriebsgrenzen denkt, und helfen dem Modell, numerische Werte mit aussagekräftigen Maschinenzuständen zu verknüpfen.
Die aussagekräftigsten Signale herausfiltern
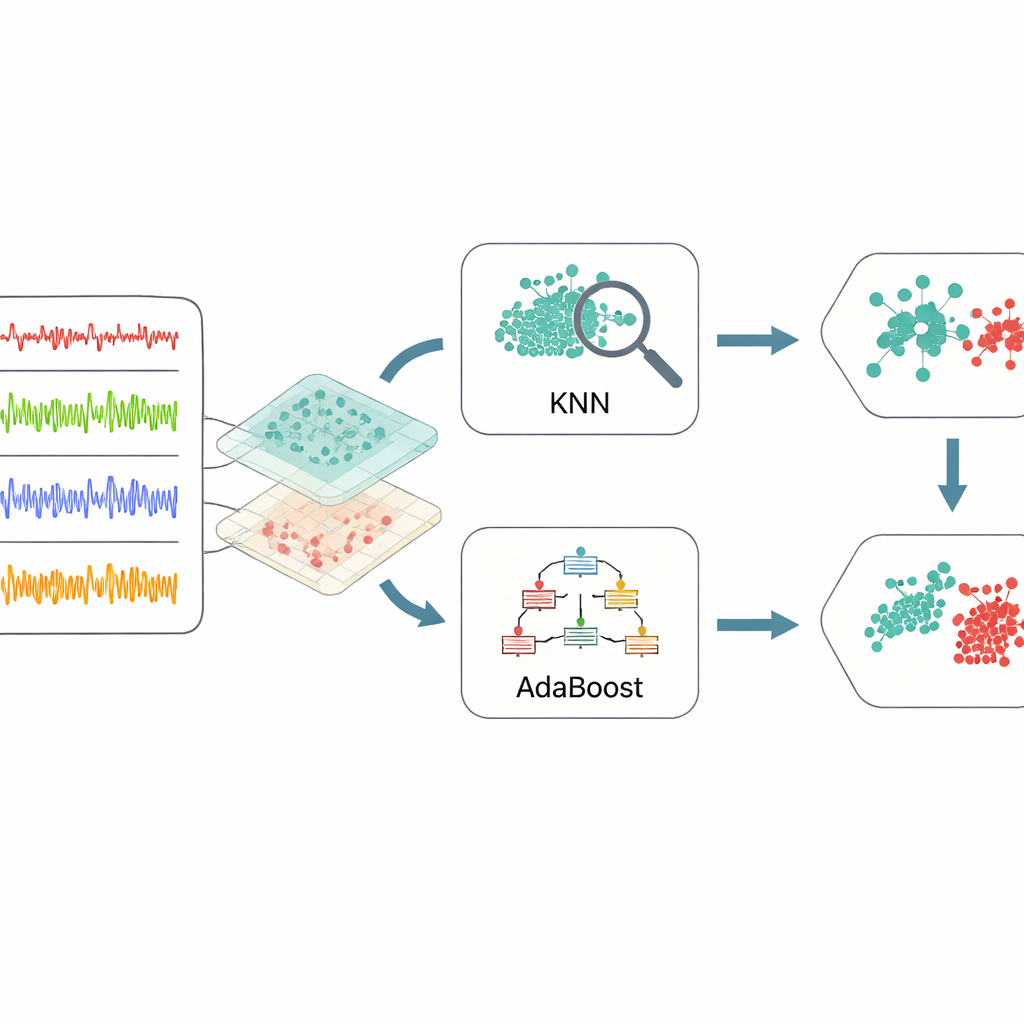
Anstatt jedem rohen Sensorwert ein Lernverfahren zuzuführen, wählt das Framework die Daten in zwei wichtigen Schritten aus und formt sie um. Zuerst untersucht ein stufenweiser Merkmalsselektor jeden Sensortyp nebeneinander mit der Zeit — zum Beispiel Spannung gegenüber Zeitstempel oder Vibration gegenüber Zeitstempel. Für jedes Paar richtet er den Fokus auf Bereichsabschnitte, die als risikoreich bekannt sind, etwa ungewöhnlich niedrige Drehzahlen oder ungewöhnlich hohe Temperaturen. Das reduziert Unordnung und betont jene Datenabschnitte, die am ehesten Anzeichen von Problemen enthalten. Zweitens wird eine erweiterte Version einer klassischen Technik, der Hauptkomponentenanalyse, eingesetzt, um normale Muster von auffälligem Verhalten zu trennen. Diese Methode, robuste Hauptkomponentenanalyse genannt, teilt die Daten in einen glatten Hintergrund, der den Normalbetrieb repräsentiert, und eine spärliche Sammlung von Spitzen und Sprüngen, die auf Fehler oder Anomalien hindeuten. Ein interner Abstimmungs-Schritt justiert, wie stark die Methode diese beiden Anteile ausbalanciert, wodurch die Trennung klarer wird.
Einfachen Lernern für stärkere Entscheidungen kombinieren
Sobald die Daten in diese informativen Merkmale destilliert sind, setzt das Framework auf ein Ensemble aus zwei Methoden des maschinellen Lernens. Eine, bekannt als k-nächste Nachbarn, sucht nach Gruppen vergangener Fälle, die einer neuen Situation stark ähneln, und stimmt anhand vergangener Ergebnisse ab. Die andere, AdaBoost, baut eine Reihe einfacher Entscheidungsregeln auf und legt besonderes Gewicht auf Beispiele, die frühere Regeln falsch klassifiziert haben. Ihre Ausgaben werden dann durch einen gewichteten Abstimmungsprozess kombiniert, sodass jede Methode ihre Stärken einbringt: lokale Sensitivität durch das nachbarschaftsbasierte Modell und fokussierte Aufmerksamkeit auf schwer zu erfassende Fälle durch das Boosting-Modell. Um Ratespiel bei der Einstellung der zahlreichen internen Parameter dieser Lerner zu vermeiden, verwenden die Autoren Bayessche Optimierung, eine Strategie, die automatisch nach Kombinationen von Einstellungen sucht, die mit relativ wenigen Versuchen die beste Gesamtleistung liefern.
Was die Experimente zeigen
Das Forschungsteam testete sein Framework an Tausenden von Sensordatensätzen, die aus dem simulierten IoT-Maschinenaufbau stammen. Es wurde mit einer breiten Palette standardmäßiger Techniken verglichen, von Entscheidungsbäumen und Random Forests bis hin zu neuronalen Netzen und anderen Ensemble-Modellen. Über die für die Wartung wichtigsten Maße — Gesamtgenauigkeit, wie oft reale Fehler korrekt erkannt werden, und wie selten das System ein echtes Problem übersieht — schnitt die neue Methode durchweg am besten ab. Sie identifizierte Fehlerzustände in Verbindung mit Spannung, Vibration, Drehzahl und Temperatur mit einer Genauigkeit nahe 99 % und einer sehr niedrigen Rate übersehener Fehler. Statistische Tests über wiederholte Trainings- und Testzyklen zeigten, dass diese Verbesserungen wahrscheinlich nicht zufällig sind. Gleichzeitig blieb die Methode rechnerisch leichtgewichtig und damit besser geeignet für den Einsatz auf betrieblichen Hardwareplattformen als viele Deep-Learning-Alternativen.
Was das für reale Fabriken bedeutet
Alltagspraktisch zeigt die Studie, dass sorgfältiges Bereinigen und Umformen von Sensordaten und das kluge Kombinieren zweier bescheidener Lernwerkzeuge komplexere Ansätze zur Fehlererkennung an Maschinen erreichen oder übertreffen kann. Für Anlagenbetreiber könnte das frühere Warnungen bedeuten, wenn Motoren zu überhitzen beginnen, wenn Vibrationen auf Lagerverschleiß hindeuten oder wenn Störungen in der Stromversorgung empfindliche Geräte gefährden. Weniger übersehene Fehler bedeuten weniger überraschende Ausfälle, während eine niedrige Falsch-Alarm-Rate Wartungsteams davon abhält, Geister zu jagen. Obwohl die Arbeit auf simulierten, aber realistischen Daten beruht, argumentieren die Autoren, dass das Framework bereit ist, in Live-Industriesystemen getestet zu werden, und die Grundlage für transparentere, kosteneffizientere vorausschauende Wartung in zukünftigen IoT-fähigen Fabriken bilden könnte.
Zitation: Devi Gayadri, S.V., Kanagaraj, G., Giri, J. et al. An optimized ensemble framework for machinery fault detection in IoT environments. Sci Rep 16, 10357 (2026). https://doi.org/10.1038/s41598-026-40335-7
Schlüsselwörter: IoT-Maschinen, Fehlererkennung, maschinelles Lernen, industrielle Sensoren, vorausschauende Wartung