Clear Sky Science · sv
En hybrid spatial suddighetsdetekterings- och restaureringsalgoritm för dokumentbilder tagna med mobiltelefon
Varför suddiga mobilbilder av dokument spelar roll
Den som någon gång fotograferat anteckningar, ett formulär eller ett gammalt brev med telefon vet hur frustrerande det är att senare försöka läsa ut utsmetad eller ojämn text. Suddighet orsakad av skakiga händer, dålig fokus eller dåligt ljus irriterar inte bara mänskliga läsare — den förvirrar också automatisk textläsningsprogramvara som används i skanningsappar, arkiv och rättsliga sammanhang. Den här artikeln presenterar ett praktiskt sätt att rädda sådana bristfälliga dokumentbilder, och förvandla röriga, ojämnt suddiga sidor till rena, datorläsbara svartvita bilder utan att förlita sig på tunga artificiell-intelligensmodeller.
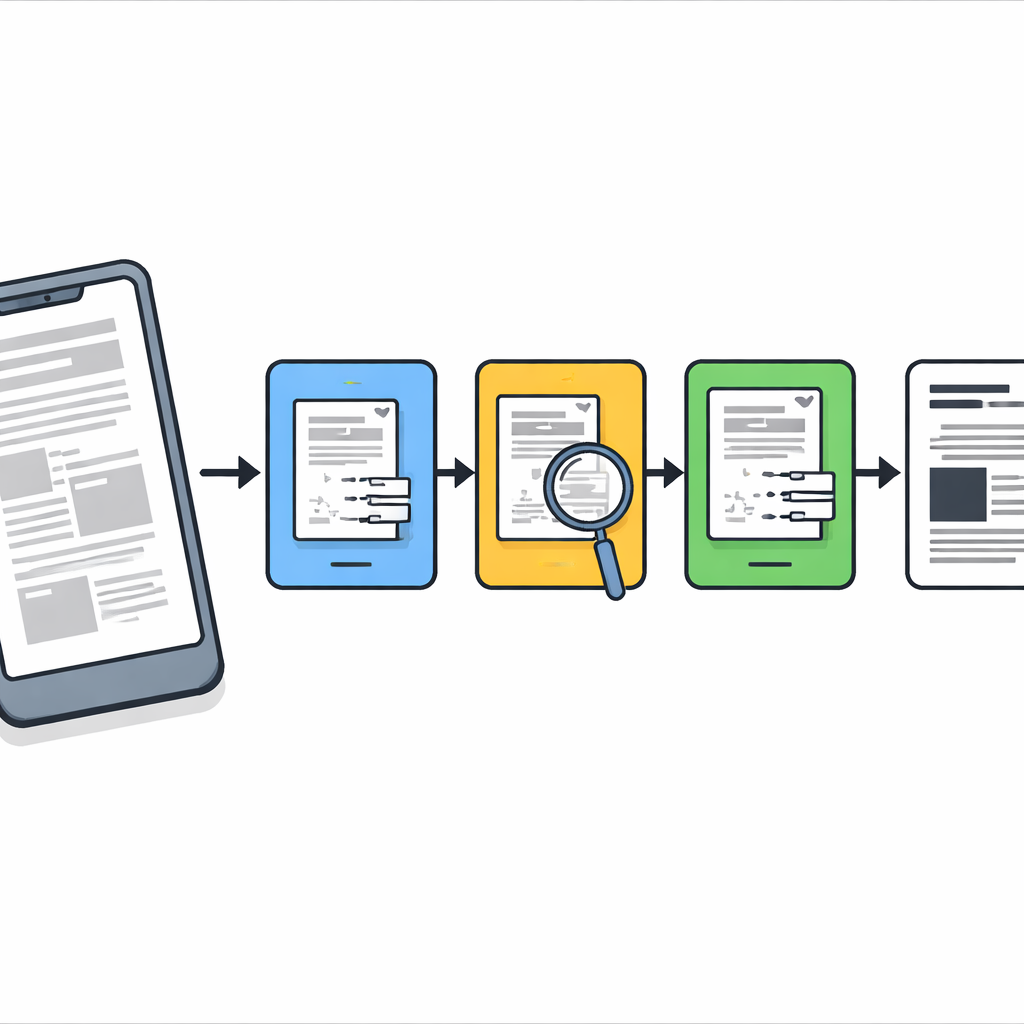
Problemet med dokumentbilder i verkliga situationer
När vi fotograferar dokument med telefon är suddigheten sällan jämn. Delar av en sida kan vara skarpa medan andra områden är ur fokus eller utsmetade av rörelse eller skuggor. De flesta traditionella rengöringsverktyg behandlar hela bilden som om suddigheten var densamma överallt, vilket ofta leder till antingen att skarp text överjämnas eller att allvarligt skadade områden inte åtgärdas. Moderna djupinlärningssystem kan göra bättre ifrån sig, men de kräver stora märkta datamängder, kraftfulla grafikchip och noggrann träning — resurser som inte alltid finns tillgängliga på kontor, i arkiv eller på billigare enheter. Författarna siktar i stället på en lättviktig, träningsfri metod som fungerar bra på vanliga datorer och telefoner.
En trestegs saneringspipeline
Forskarna utformar en stegvis pipeline som fungerar som en noggrann digital konservator. Först rättas varje kameraavbildad sida upp så att arket ser ut som en platt skanning istället för ett snedvridet fotografi taget i vinkel. Därefter tillämpas en klassisk skärpningsteknik kallad Richardson–Lucy-dekonvolution med en enkel suddighetskärna för att varsamt återställa allmän skärpa och framhäva svaga streck. Efter detta steg är sidan klarare men innehåller fortfarande fläckar av envis suddighet och brus, så metoden stannar inte där.
Hur metoden hittar och åtgärdar suddiga fläckar
Andra steget fokuserar på att upptäcka exakt var på sidan suddigheten kvarstår. Systemet undersöker varje litet grannskap på två kompletterande sätt: i vanlig bilddomän använder det en Laplacian-mätning av lokala kantstyrkor (skarpa kanter tyder på klar text, svaga kanter antyder suddighet), och i frekvensdomänen inspekterar det hur mycket fint detaljmaterial som gått förlorat. Genom att kombinera dessa två ledtrådar bygger det en suddighetsmask som skiljer suddiga från icke-suddiga regioner. Enkla formrensningsoperationer slätar sedan ut denna mask till sammanhängande textblock istället för spridda brusiga pixlar.
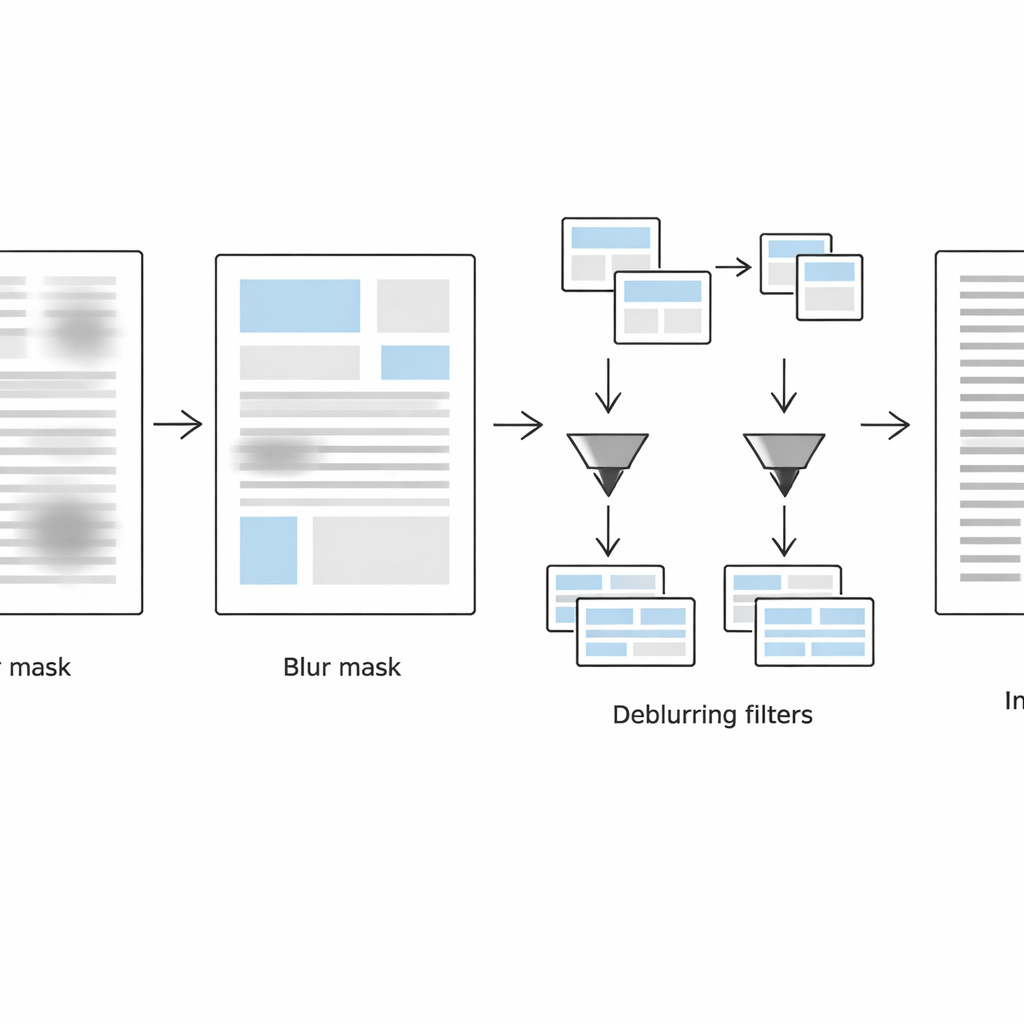
Att behandla skarp och suddig text olika
I tredje steget delas sidan virtuellt upp i två versioner: en som huvudsakligen innehåller suddiga textblock och en annan som mest innehåller skarpa block, styrt av suddighetsmasken. För varje uppsättning regioner tillämpar metoden en adaptiv svartvit-konvertering anpassad till lokala förhållanden. Suddiga områden får större analyssonfönster och starkare kontrastjusteringar för att återfå bleka streck, medan redan skarpa områden behandlas mer varsamt för att undvika korniga artefakter eller att bryta sönder streck. Algoritmen sparar endast positionsdata för dessa regioner — lagrade i lätta metadatafiler — så att den kan återfoga de bearbetade delarna till ett enda, rent, binärt dokument som är redo för optisk teckenigenkänning.
Hur bra det fungerar och varför det är viktigt
Författarna testar sitt tillvägagångssätt på 417 riktiga dokumentbilder tagna med mobiltelefon och flera nivåer av tillsatt suddighet, belysningsproblem och brus. De jämför sin pipeline med flera populära binariseringstekniker och med moderna bildåterställningssystem, med en bred uppsättning kvalitetsmått och direkta mätningar av textigenkänningsnoggrannhet. Både vid måttlig och svår suddighet bevarar deras metod konsekvent fler streck, förlorar färre tecken och upprätthåller en stabilare prestanda än alternativen — allt utan att träna ett neuralt nätverk. För vardagsanvändare innebär detta att mobilbilder av anteckningar, juridiska dokument eller historiska sidor kan göras skarpare, mer läsbara och mer sökbara, även på blygsig hårdvara och i miljöer med begränsade resurser.
Citering: Karthik, U., Nair, B.J.B., Rani, N.S. et al. A hybrid spatial blur detection and restoration algorithm for smartphone captured document images. Sci Rep 16, 12648 (2026). https://doi.org/10.1038/s41598-026-38494-8
Nyckelord: återställning av dokumentbilder, oskarpa mobilskanningar, optisk teckenigenkänning, bildförbättring, digital arkivering