Clear Sky Science · fr
Un algorithme hybride de détection et restauration de flou spatial pour images de documents capturées au smartphone
Pourquoi les photos floues de documents prises au téléphone comptent
Quiconque a pris en photo des notes, un formulaire ou une vieille lettre avec un téléphone connaît la frustration de devoir déchiffrer ensuite un texte brouillé ou irrégulier. Le flou dû à des mains tremblantes, une mise au point médiocre ou un éclairage défavorable n'embête pas seulement le lecteur humain : il perturbe aussi les logiciels automatiques de lecture de texte utilisés dans les applications de numérisation, les archives ou les procédures judiciaires. Cet article présente une méthode pratique pour sauver ce type de photos de documents dégradées, transformant des pages mal dégradées et inégalement floues en images binaires propres et lisibles par machine, sans s'appuyer sur des modèles d'intelligence artificielle lourds.
Le problème des photos de documents dans le monde réel
Lorsque nous photographions des documents avec un téléphone, le flou est rarement uniforme. Des zones d'une page peuvent être nettes tandis que d'autres sont hors-focus ou étalées par le mouvement ou l'ombre. La plupart des outils de nettoyage traditionnels traitent l'image entière comme si le flou était identique partout, ce qui conduit souvent soit à lisser excessivement du texte déjà net, soit à ne pas corriger des régions fortement altérées. Les systèmes modernes de deep learning peuvent mieux faire, mais ils nécessitent de grands jeux de données annotés, des puces graphiques puissantes et un entraînement soigné — des ressources qui ne sont pas toujours disponibles dans les bureaux, les archives ou sur des appareils à bas coût. Les auteurs visent donc une méthode légère, sans entraînement, qui fonctionne bien sur des ordinateurs et des téléphones ordinaires.
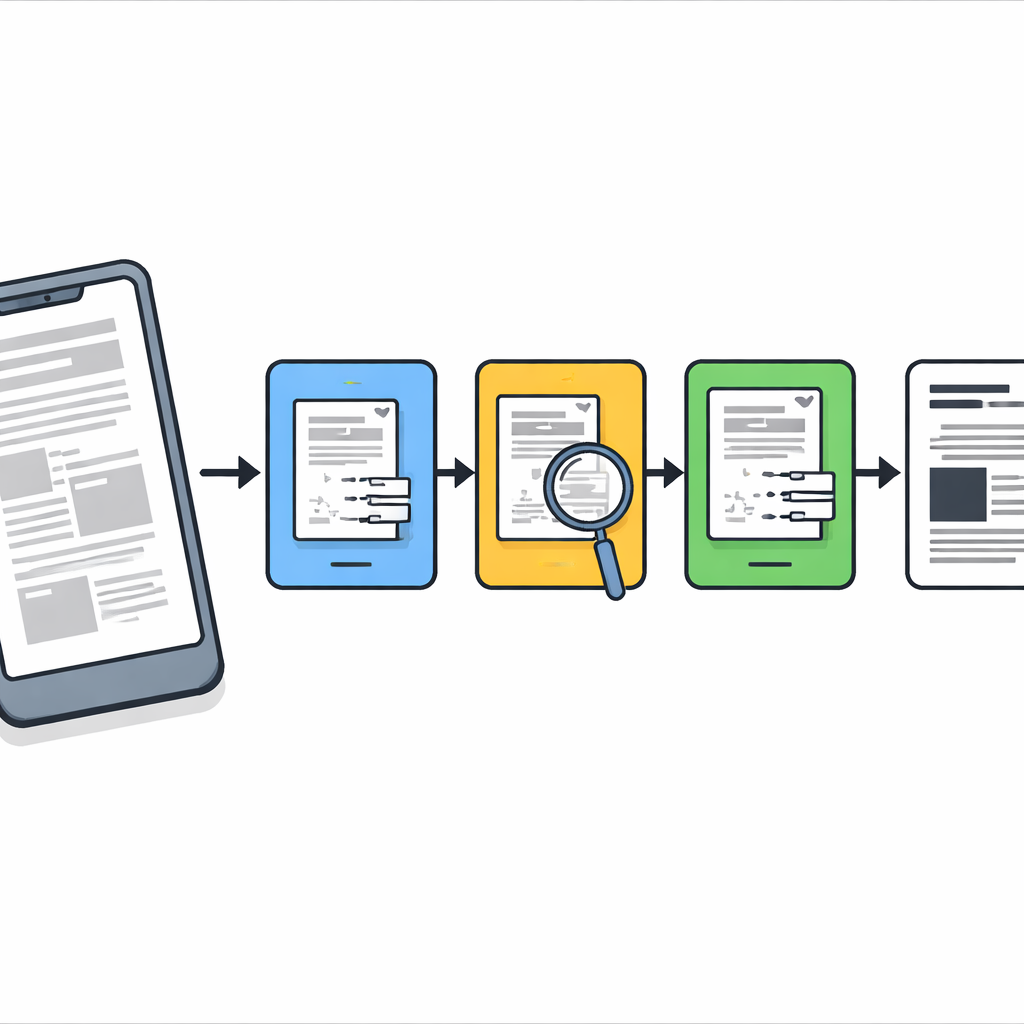
Un pipeline de nettoyage en trois étapes
Les chercheurs conçoivent une chaîne de traitement étape par étape qui agit comme un restaurateur numérique prudent. D'abord, chaque page capturée est redressée pour que la feuille ressemble à une numérisation plate plutôt qu'à une photographie déformée prise en biais. Ensuite, une procédure classique d'accentuation appelée déconvolution de Richardson–Lucy est appliquée avec une forme de flou simple pour restaurer délicatement la netteté globale et faire ressortir les traits faibles. Après cette étape, la page est plus claire mais contient encore des taches de flou tenaces et du bruit, donc la méthode ne s'arrête pas là.
Comment la méthode repère et corrige les zones floues
La deuxième étape se concentre sur la détection précise des zones encore floues de la page. Le système analyse chaque petit voisinage de deux manières complémentaires : dans le domaine spatial il utilise une mesure laplacienne de la force locale des contours (des bords nets impliquent un texte probablement clair, des bords faibles suggèrent du flou), et dans le domaine fréquentiel il inspecte la perte de détails fins. En combinant ces deux indices, il construit un masque de flou qui sépare les régions floues des régions nettes. Des opérations simples de nettoyage de forme lissent ensuite ce masque pour obtenir des blocs textuels cohérents plutôt que des pixels bruités épars.
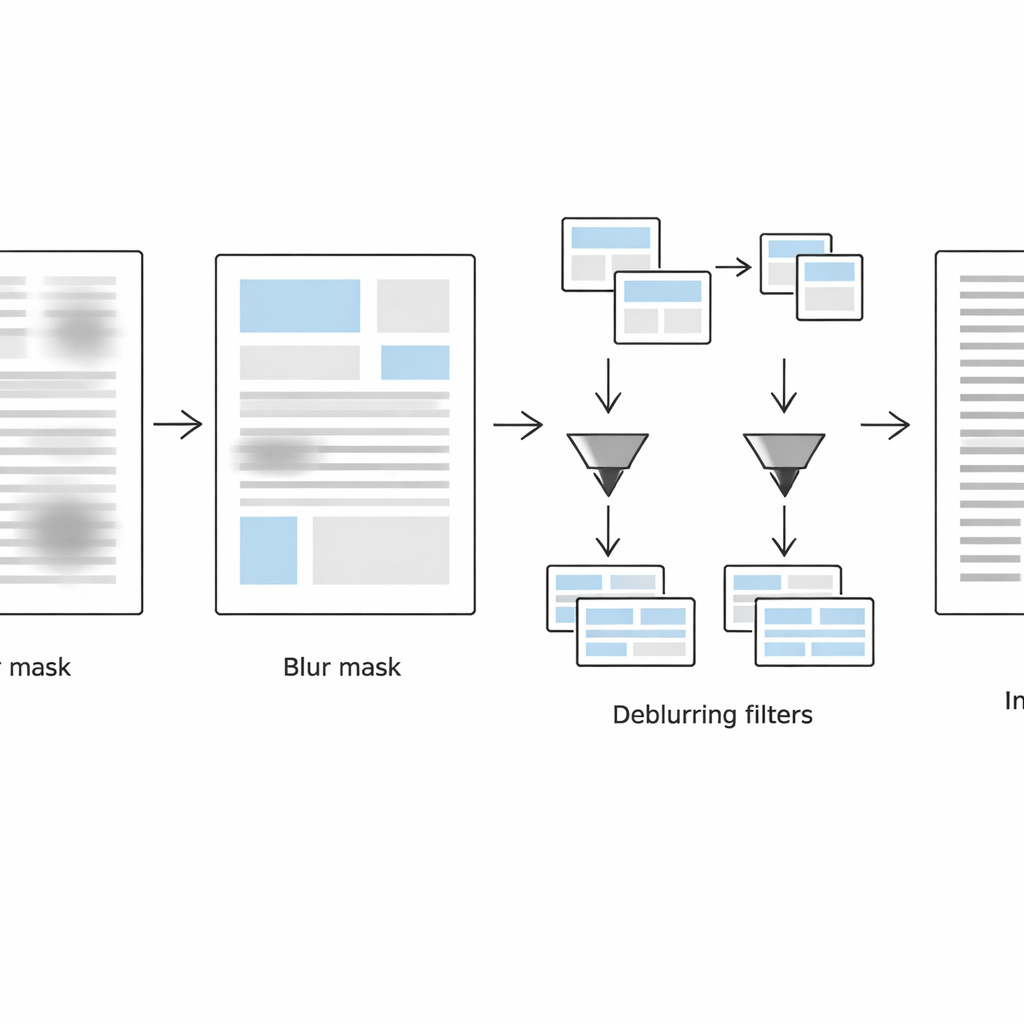
Traiter différemment le texte net et le texte flou
Dans la troisième étape, la page est virtuellement scindée en deux versions : l'une contenant principalement des blocs de texte flous et l'autre contenant surtout des zones nettes, guidée par le masque de flou. Pour chaque ensemble de régions, la méthode applique une conversion adaptative en noir et blanc ajustée aux conditions locales. Les régions floues reçoivent des fenêtres d'analyse plus larges et des ajustements de contraste plus forts pour récupérer les traits estompés, tandis que les régions déjà nettes sont traitées plus doucement afin d'éviter l'apparition d'artefacts granuleux ou la rupture des traits. L'algorithme ne conserve que les données de position pour ces régions — stockées dans des fichiers de métadonnées légers — afin de recombiner ensuite les pièces traitées en un seul document binarisé, propre et prêt pour la reconnaissance optique de caractères.
Performance et importance de la méthode
Les auteurs testent leur approche sur 417 images réelles de documents prises au smartphone et sur plusieurs niveaux de flou, problèmes d'éclairage et de bruit ajoutés. Ils comparent leur chaîne de traitement à plusieurs méthodes populaires de binarisation et à des systèmes modernes de restauration d'image, en utilisant un large éventail d'indicateurs de qualité et des mesures directes de la précision de reconnaissance de texte. Tant pour des niveaux de flou modérés que sévères, leur méthode préserve systématiquement davantage de traits, fait perdre moins de caractères et maintient une performance plus stable que les alternatives, le tout sans entraîner de réseau neuronal. Pour l'utilisateur quotidien, cela signifie que des photos de notes, de documents juridiques ou de pages historiques prises au téléphone peuvent être transformées en documents plus nets, plus lisibles et plus consultables, même sur du matériel modeste et dans des environnements aux ressources limitées.
Citation: Karthik, U., Nair, B.J.B., Rani, N.S. et al. A hybrid spatial blur detection and restoration algorithm for smartphone captured document images. Sci Rep 16, 12648 (2026). https://doi.org/10.1038/s41598-026-38494-8
Mots-clés: restauration d'images de documents, numérisations floues au smartphone, reconnaissance optique de caractères, amélioration d'image, archivage numérique