Clear Sky Science · ru
Гибридный алгоритм пространственного обнаружения размытия и восстановления для изображений документов, снятых на смартфон
Почему важны размытые фотографии бумажных документов
Любой, кто фотографировал заметки, бланк или старое письмо на телефон, знает, как неприятно пытаться читать размазанную или неравномерную печать. Размытие от дрожащих рук, плохой фокусировки или неудачного освещения не только раздражает людей — оно также сбивает с толку автоматическое программное обеспечение для чтения текста, используемое в скан‑приложениях, архивах и судебных инстанциях. В этой работе предлагается практичный способ спасти такие дефектные фотографии документов, превратив неряшливые, неравномерно размытые страницы в чистые, пригодные для компьютера чёрно‑белые изображения без опоры на тяжёлые модели искусственного интеллекта.
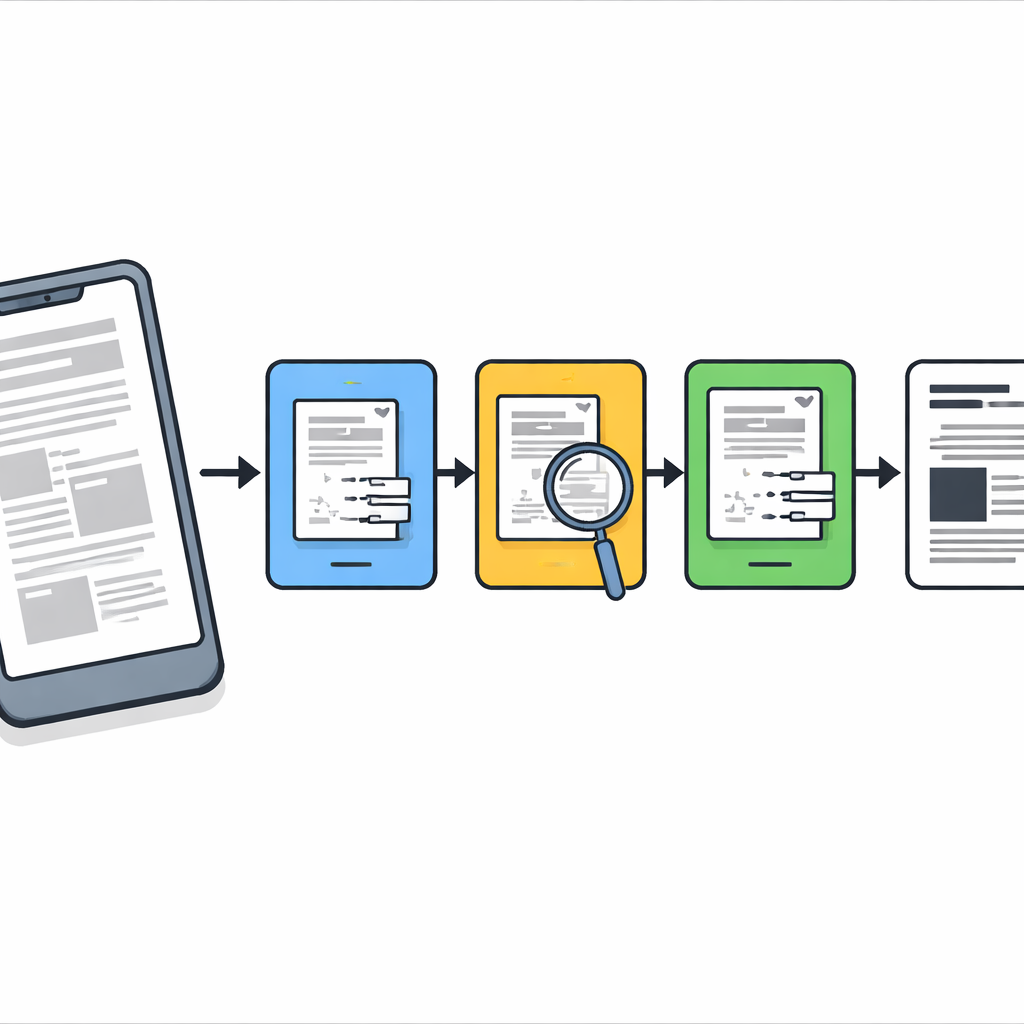
Проблема реальных фотографий документов
При съёмке документов на телефон размытие редко бывает однородным. Части страницы могут быть резкими, в то время как другие области находятся вне фокуса или замазаны движением или тенью. Большинство традиционных инструментов очистки обрабатывают всё изображение, как будто размытие одинаково по всей площади, что часто приводит либо к чрезмерному сглаживанию резкого текста, либо к неспособности исправить сильно повреждённые участки. Современные системы глубинного обучения справляются лучше, но им требуются большие размеченные наборы данных, мощные графические процессоры и тщательное обучение — ресурсы, которые не всегда доступны в офисах, архивах или на недорогих устройствах. Авторы вместо этого нацелены на лёгкий метод без обучения, который хорошо работает на обычных компьютерах и телефонах.
Трёхэтапный конвейер очистки
Исследователи разработали пошаговый конвейер, который действует как внимательный цифровой реставратор. Сначала каждая страница, снятая камерой, выравнивается так, чтобы лист выглядел как плоский скан, а не как сфотографированный под углом объект. Затем применяется классическая процедура повышения резкости — деконволюция Ричардсона–Люси с простой формой пятна размытия — чтобы аккуратно восстановить общую чёткость и выявить бледные штрихи. После этого этапа страница становится яснее, но в ней по‑прежнему остаются участки упорного размытия и шум, поэтому метод на этом не останавливается.
Как метод находит и исправляет размытые участки
Второй этап сосредоточен на обнаружении точных мест, где страница всё ещё размыта. Система исследует каждое небольшое окружение двумя взаимодополняющими способами: в обычной области изображения используется лапласиан для оценки локальной силы границ (резкие края обычно означают чёткий текст, слабые — размытие), а в частотной области анализируется, сколько тонких деталей утрачено. Комбинируя эти два признака, она строит маску размытия, разделяющую размытые и неразмытые области. Простые операции по очистке формы затем сглаживают эту маску в цельные текстовые блоки вместо разбросанных шумных пикселей.
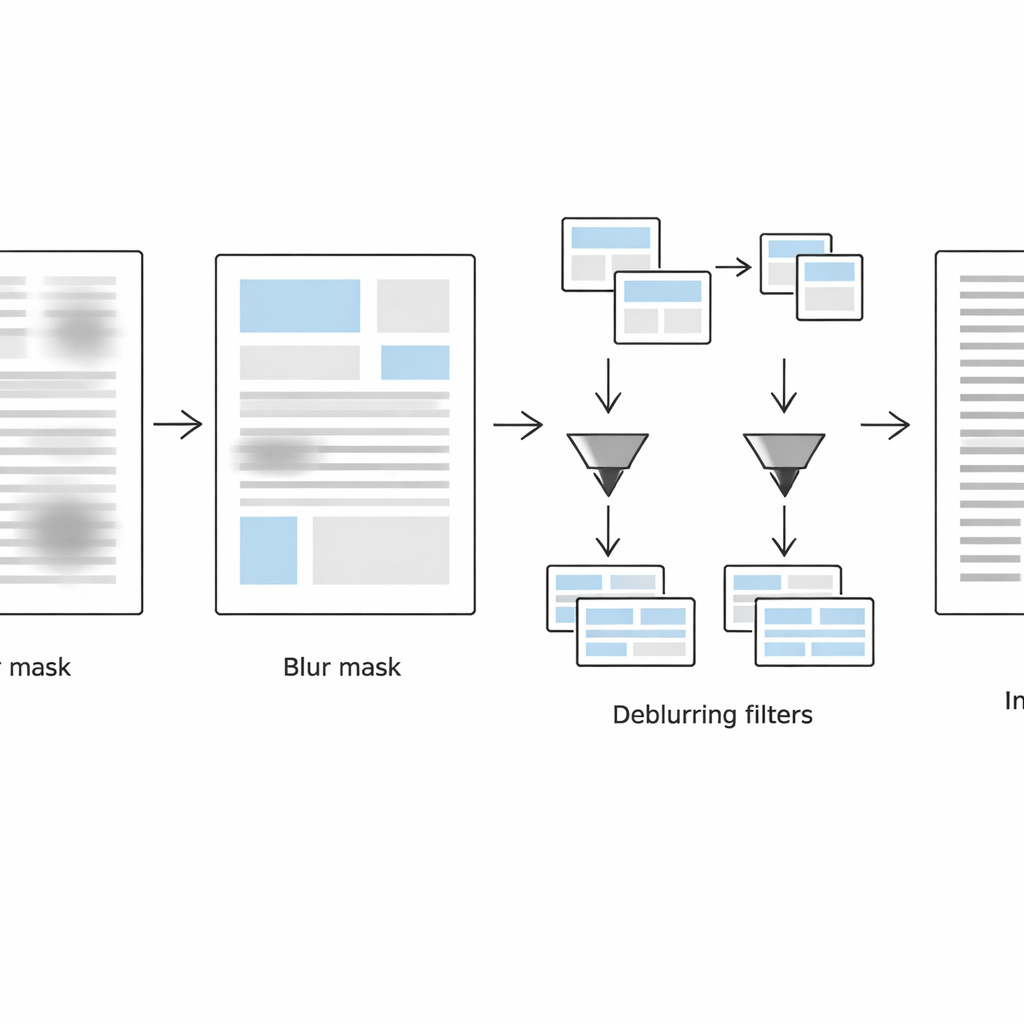
Различная обработка резкого и размывшегося текста
На третьем этапе страница виртуально разделяется на две версии: одна содержит в основном размытые текстовые блоки, а другая — преимущественно резкие, причём разделение задаётся маской размытия. Для каждого набора областей метод применяет адаптивное преобразование в чёрно‑белое, настроенное под локальные условия. Размытые участки обрабатываются с большими окнами анализа и сильными корректировками контраста, чтобы восстановить бледные штрихи, тогда как уже резкие области обрабатываются более бережно, чтобы избежать появления зернистых артефактов или разрушения штрихов. Алгоритм сохраняет только данные о расположении этих областей — в лёгких файлах метаданных — чтобы затем объединить обработанные фрагменты в единый чистый бинаризованный документ, готовый для оптического распознавания символов.
Эффективность метода и зачем это нужно
Авторы протестировали свой подход на 417 реальных изображениях документов со смартфона и на нескольких уровнях добавленного размытия, проблем освещения и шума. Они сравнили свой конвейер с несколькими популярными методами бинаризации и современными системами восстановления изображений, используя широкий набор метрик качества и прямые измерения точности распознавания текста. Как при умеренном, так и при сильном размытии их метод последовательно сохраняет больше штрихов, теряет меньше символов и демонстрирует более стабильную работу по сравнению с альтернативами — и всё это без обучения нейронной сети. Для повседневных пользователей это означает, что фотографии заметок, юридических документов или исторических страниц можно превратить в более резкие, удобочитаемые и индексируемые документы даже на скромном железе и в условиях с ограниченными ресурсами.
Цитирование: Karthik, U., Nair, B.J.B., Rani, N.S. et al. A hybrid spatial blur detection and restoration algorithm for smartphone captured document images. Sci Rep 16, 12648 (2026). https://doi.org/10.1038/s41598-026-38494-8
Ключевые слова: восстановление изображений документов, размытые сканы со смартфона, оптическое распознавание символов, улучшение изображений, цифровой архив