Clear Sky Science · nl
Een hybride ruimtelijk vervagingsdetectie- en herstelalgoritme voor met smartphones vastgelegde documentafbeeldingen
Waarom onscherpe telefoonfoto's van documenten ertoe doen
Iedereen die ooit met een telefoon aantekeningen, een formulier of een oude brief heeft gefotografeerd kent de frustratie van het achteraf proberen te lezen van vervaagde, ongelijkmatige tekst. Vervaging door trillende handen, slechte focus of slechte belichting irriteert niet alleen menselijke lezers—het verwart ook automatische tekstleessoftware die wordt gebruikt in scan-apps, archieven en rechtbanken. Dit artikel presenteert een praktische manier om zulke gebrekkige documentfoto's te redden, door rommelige, ongelijkmatig vervaagde pagina's om te zetten in schone, computerleesbare zwart-wit beelden zonder te steunen op zware artificiële-intelligentie modellen.
Het probleem met documentfoto's uit de praktijk
Wanneer we documenten met telefoons fotograferen, is vervaging zelden uniform. Delen van een pagina kunnen scherp zijn terwijl andere gebieden onscherp, bewogen of door schaduw vervormd zijn. De meeste traditionele reinigingstools behandelen de hele afbeelding alsof de vervaging overal hetzelfde is, wat vaak leidt tot ofwel het te veel vervagen van scherpe tekst of het niet herstellen van zwaar beschadigde gebieden. Moderne deep-learning systemen kunnen beter presteren, maar zij hebben grote gelabelde datasets, krachtige grafische chips en zorgvuldige training nodig—middelen die niet altijd beschikbaar zijn op kantoren, in archieven of op goedkope apparaten. De auteurs kiezen daarom voor een lichte, trainingsvrije methode die goed werkt op gewone computers en telefoons.
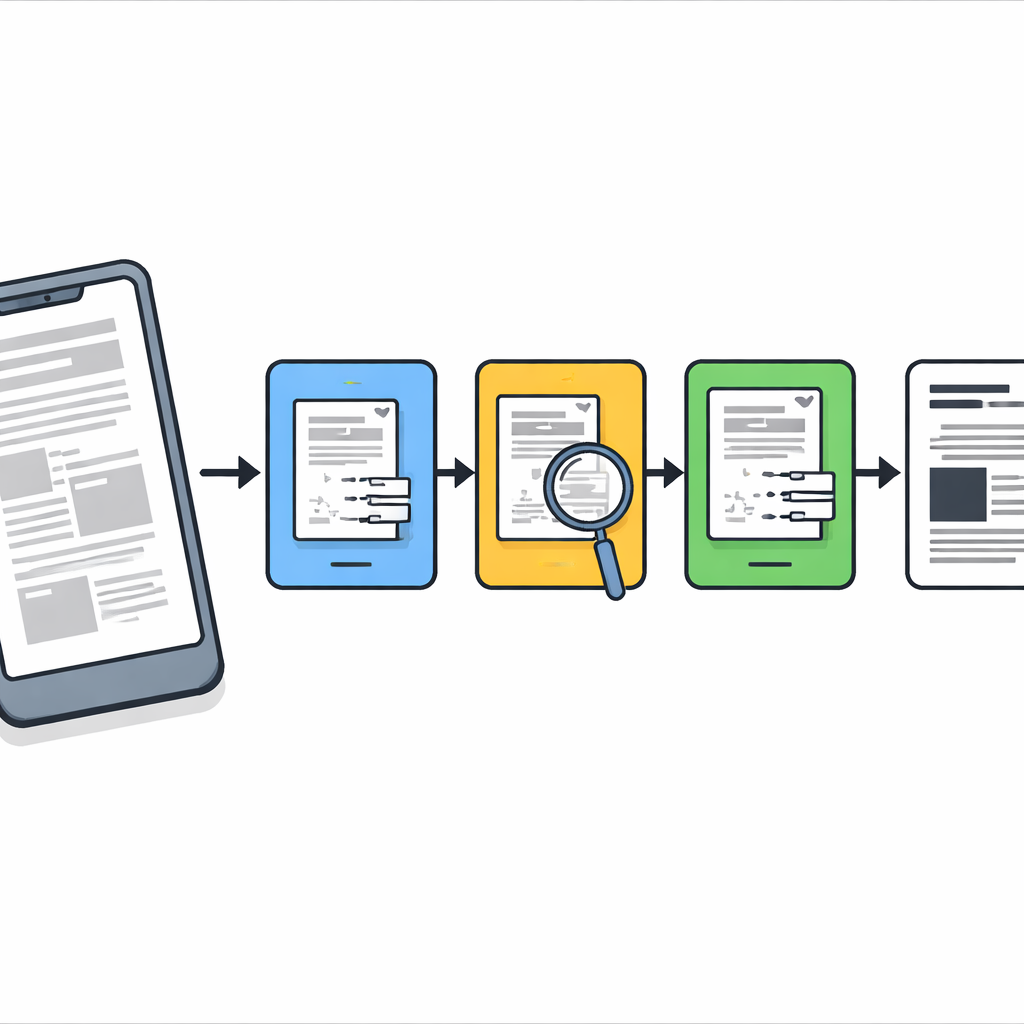
Een schoonmaakpipeline in drie stappen
De onderzoekers ontwerpen een stapsgewijze pijplijn die fungeert als een zorgvuldige digitale conservator. Eerst wordt elke met de camera vastgelegde pagina rechtgetrokken zodat het blad eruitziet als een plat scan in plaats van een onder een hoek gemaakte foto. Vervolgens wordt een klassieke verscherpingsprocedure, Richardson–Lucy deconvolutie genoemd, toegepast met een eenvoudige vervagingskernel om de algehele scherpte voorzichtig te herstellen en zwakke lijnen naar voren te brengen. Na deze stap is de pagina helderder maar bevat nog steeds plekken met hardnekkige vervaging en ruis, dus de methode stopt daar niet.
Hoe de methode vage plekken vindt en herstelt
De tweede fase richt zich op het detecteren van precies waar de pagina nog vervaagd is. Het systeem bekijkt elk klein buurtgebied op twee complementaire manieren: in het normale afbeeldingsdomein gebruikt het een Laplaciaanse maat van lokale randsterkte (scherpe randen duiden waarschijnlijk op duidelijke tekst, zwakke randen wijzen op vervaging), en in het frequentiedomein inspecteert het hoeveel fijne details verloren zijn gegaan. Door deze twee aanwijzingen te combineren bouwt het een vervagingsmasker dat vervaagde van niet-vervaagde regio's scheidt. Eenvoudige vorm-schoonmaakbewerkingen maken dit masker vervolgens glad tot coherente tekstblokken in plaats van verspreide, luidruchtige pixels.
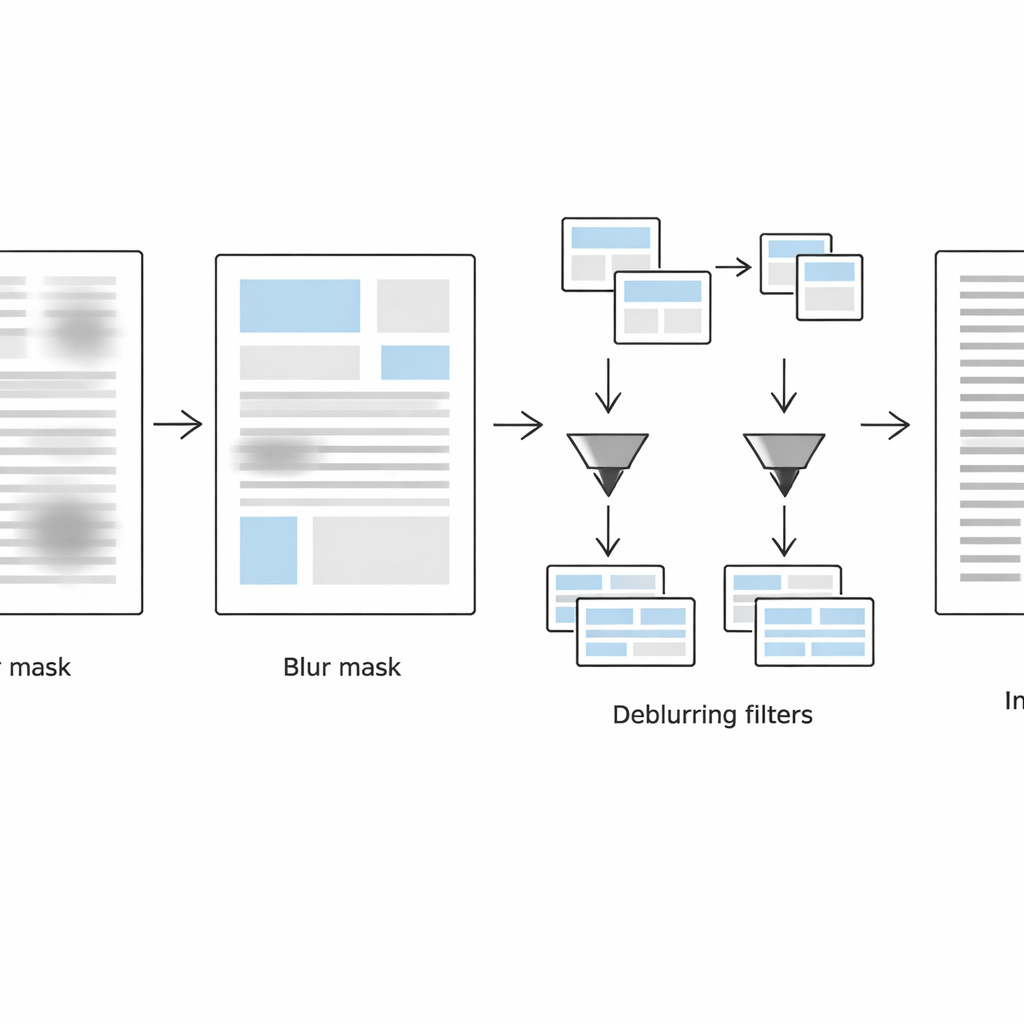
Scherpe en vervaagde tekst verschillend behandelen
In de derde fase wordt de pagina virtueel opgesplitst in twee versies: één die voornamelijk vervaagde tekstblokken bevat en de andere die vooral scherpe bevat, geleid door het vervagingsmasker. Voor elke set regio's past de methode een adaptieve zwart-witconversie toe die is afgestemd op lokale omstandigheden. Vervaagde gebieden krijgen grotere analyseraamwerken en sterkere contrastaanpassingen om vervaagde lijnen terug te winnen, terwijl reeds scherpe gebieden voorzichtiger worden verwerkt om korrelige artefacten of het verbreken van lijnen te voorkomen. Het algoritme bewaart alleen locatiegegevens voor deze regio's—opgeslagen in lichtgewicht metadata-bestanden—zodat het de bewerkte delen kan samenvoegen tot één schone, gebinariseerde pagina die klaar is voor optische tekenherkenning.
Hoe goed het werkt en waarom het ertoe doet
De auteurs testen hun aanpak op 417 echte smartphone-documentafbeeldingen en meerdere niveaus van toegevoegde vervaging, belichtingsproblemen en ruis. Ze vergelijken hun pijplijn met meerdere populaire binariseer-methoden en met moderne beeldherstel-systemen, met behulp van een breed scala aan kwaliteitscores en directe metingen van tekstherkenningsnauwkeurigheid. Zowel bij matige als ernstige vervaging behoudt hun methode consequent meer lijnvoering, verliest minder tekens en handhaaft stabielere prestaties dan de alternatieven, en dat alles zonder een neuraal netwerk te trainen. Voor alledaagse gebruikers betekent dit dat telefoonfoto's van aantekeningen, juridische documenten of historische pagina's kunnen worden omgezet in scherpere, beter leesbare en beter doorzoekbare documenten, zelfs op bescheiden hardware en in omgevingen met beperkte middelen.
Bronvermelding: Karthik, U., Nair, B.J.B., Rani, N.S. et al. A hybrid spatial blur detection and restoration algorithm for smartphone captured document images. Sci Rep 16, 12648 (2026). https://doi.org/10.1038/s41598-026-38494-8
Trefwoorden: herstel van documentafbeeldingen, vervagde smartphone-scans, optische tekenherkenning, beeldverbetering, digitale archivering