Clear Sky Science · it
Un algoritmo ibrido di rilevamento della sfocatura spaziale e restauro per immagini di documenti catturate con smartphone
Perché contano le foto sfocate di documenti scattate con il telefono
Chiunque abbia fotografato appunti, un modulo o una vecchia lettera con il telefono conosce la frustrazione di dover leggere dopo parole sfocate e irregolari. La sfocatura dovuta a mani tremanti, messa a fuoco imperfetta o scarsa illuminazione non disturba solo i lettori umani: confonde anche i software automatici di lettura del testo usati in app di scansione, archivi e tribunali. Questo articolo presenta un metodo pratico per recuperare foto di documenti difettose, trasformando pagine disordinate e con sfocature non uniformi in immagini in bianco e nero pulite e leggibili dal computer, senza fare affidamento su pesanti modelli di intelligenza artificiale.
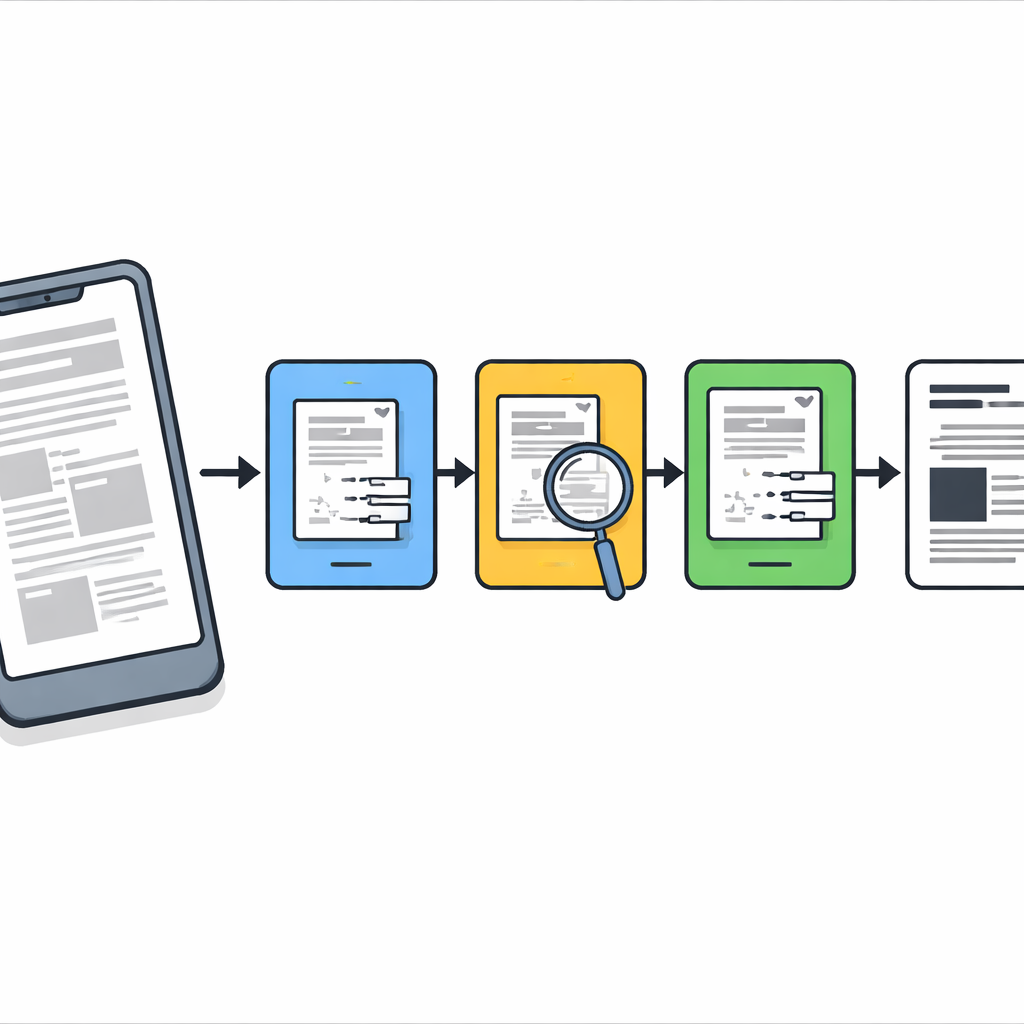
Il problema delle foto di documenti nel mondo reale
Quando fotografiamo documenti con il telefono, la sfocatura raramente è uniforme. Parti di una pagina possono risultare nitide mentre altre aree sono fuori fuoco o sfocate da movimento o ombra. La maggior parte degli strumenti tradizionali tratta l’immagine intera come se la sfocatura fosse la stessa ovunque, il che spesso porta a sovrasmussare il testo già nitido o a non riuscire a correggere le zone gravemente danneggiate. I sistemi moderni di deep learning possono fare meglio, ma richiedono grandi dataset etichettati, potenti GPU e un addestramento accurato—risorse che non sono sempre disponibili in uffici, archivi o dispositivi a basso costo. Gli autori mirano invece a un metodo leggero, senza addestramento, che funzioni bene su computer e telefoni comuni.
Una pipeline di pulizia in tre fasi
I ricercatori progettano una pipeline passo dopo passo che agisce come un conservatore digitale accurato. Prima, ogni pagina catturata con la fotocamera viene raddrizzata in modo che il foglio appaia come una scansione piatta anziché una fotografia deformata scattata di sbieco. Poi si applica una classica procedura di nitidezza chiamata deconvoluzione di Richardson–Lucy con una semplice forma di sfocatura per ripristinare delicatamente la nitidezza complessiva e mettere in evidenza tratti deboli. Dopo questa fase la pagina risulta più chiara ma contiene ancora aree di sfocatura ostinate e rumore, quindi il metodo non si ferma qui.
Come il metodo individua e corregge le zone sfocate
La seconda fase si concentra sul rilevare esattamente dove la pagina rimane sfocata. Il sistema esamina ogni piccolo intorno con due modalità complementari: nel dominio dell’immagine normale usa una misura laplaciana della forza dei bordi locali (bordi netti indicano testo probabilmente nitido, bordi deboli suggeriscono sfocatura), e nel dominio della frequenza controlla quanto dettaglio fine è stato perso. Combinando questi due indizi, costruisce una maschera di sfocatura che separa le regioni sfocate da quelle non sfocate. Semplici operazioni di pulizia delle forme poi levigano questa maschera in blocchi di testo coerenti anziché pixel rumorosi sparsi.
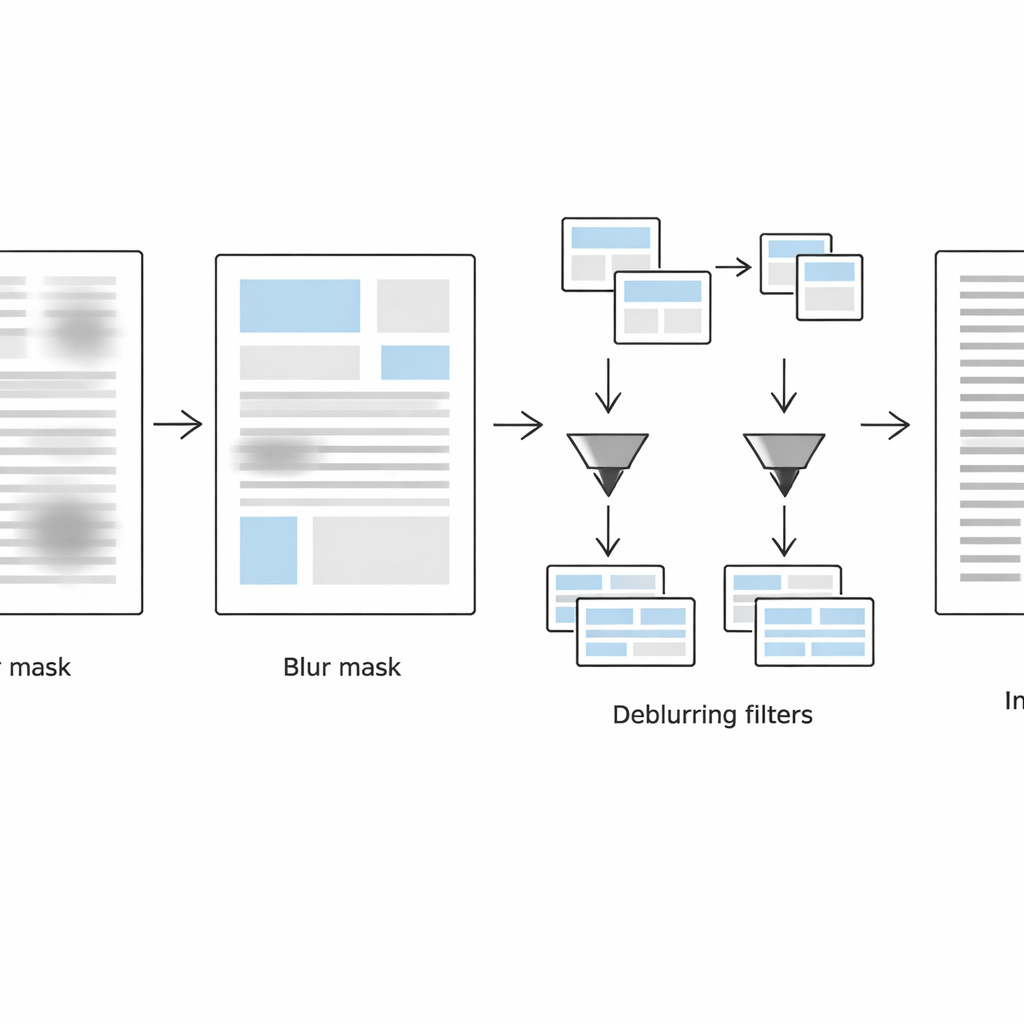
Trattare in modo diverso il testo nitido e quello sfocato
Nella terza fase, la pagina viene virtualmente divisa in due versioni: una che contiene principalmente blocchi di testo sfocato e l’altra che contiene soprattutto blocchi nitidi, guidata dalla maschera di sfocatura. Per ciascun insieme di regioni, il metodo applica una conversione adattiva in bianco e nero tarata sulle condizioni locali. Le regioni sfocate ricevono finestre di analisi più ampie e aggiustamenti di contrasto più forti per recuperare tratti sbiaditi, mentre le regioni già nitide vengono processate con maggiore delicatezza per evitare di creare grana o interrompere i tratti. L’algoritmo conserva solo i dati di posizione per queste regioni—memorizzati in file di metadati leggeri—così da poter ricombinare i pezzi processati in un unico documento binarizzato, pulito e pronto per il riconoscimento ottico dei caratteri.
Quanto funziona bene e perché è importante
Gli autori testano il loro approccio su 417 immagini reali di documenti scattate con smartphone e su molteplici livelli di sfocatura, problemi di illuminazione e rumore aggiunti. Confrontano la loro pipeline con diversi metodi di binarizzazione popolari e con sistemi moderni di restauro delle immagini, utilizzando un’ampia gamma di punteggi di qualità e misure dirette di accuratezza del riconoscimento del testo. Sia a livelli di sfocatura moderata sia severa, il loro metodo preserva consistentemente più tratti, perde meno caratteri e mantiene una performance più stabile rispetto alle alternative, il tutto senza addestrare una rete neurale. Per gli utenti quotidiani, questo significa che le foto al telefono di appunti, documenti legali o pagine storiche possono essere trasformate in documenti più nitidi, più leggibili e più ricercabili, anche su hardware modesto e in contesti con risorse limitate.
Citazione: Karthik, U., Nair, B.J.B., Rani, N.S. et al. A hybrid spatial blur detection and restoration algorithm for smartphone captured document images. Sci Rep 16, 12648 (2026). https://doi.org/10.1038/s41598-026-38494-8
Parole chiave: restauro di immagini di documenti, scansioni da smartphone sfocate, riconoscimento ottico dei caratteri, miglioramento delle immagini, archiviazione digitale