Clear Sky Science · es
Un algoritmo híbrido de detección espacial de desenfoque y restauración para imágenes de documentos capturadas con smartphone
Por qué importan las fotos borrosas de documentos hechas con el móvil
Cualquiera que haya fotografiado apuntes, un formulario o una carta antigua con un teléfono conoce la frustración de intentar leer texto difuminado o irregular después. El desenfoque causado por manos temblorosas, mala focalización o iluminación deficiente no solo molesta a los lectores humanos, sino que también confunde al software automático de lectura de texto utilizado en aplicaciones de escaneo, archivos y tribunales. Este artículo presenta una forma práctica de rescatar esas fotos de documentos defectuosas, convirtiendo páginas desordenadas y con desenfoque desigual en imágenes limpias en blanco y negro, listas para ordenador, sin depender de modelos pesados de inteligencia artificial.
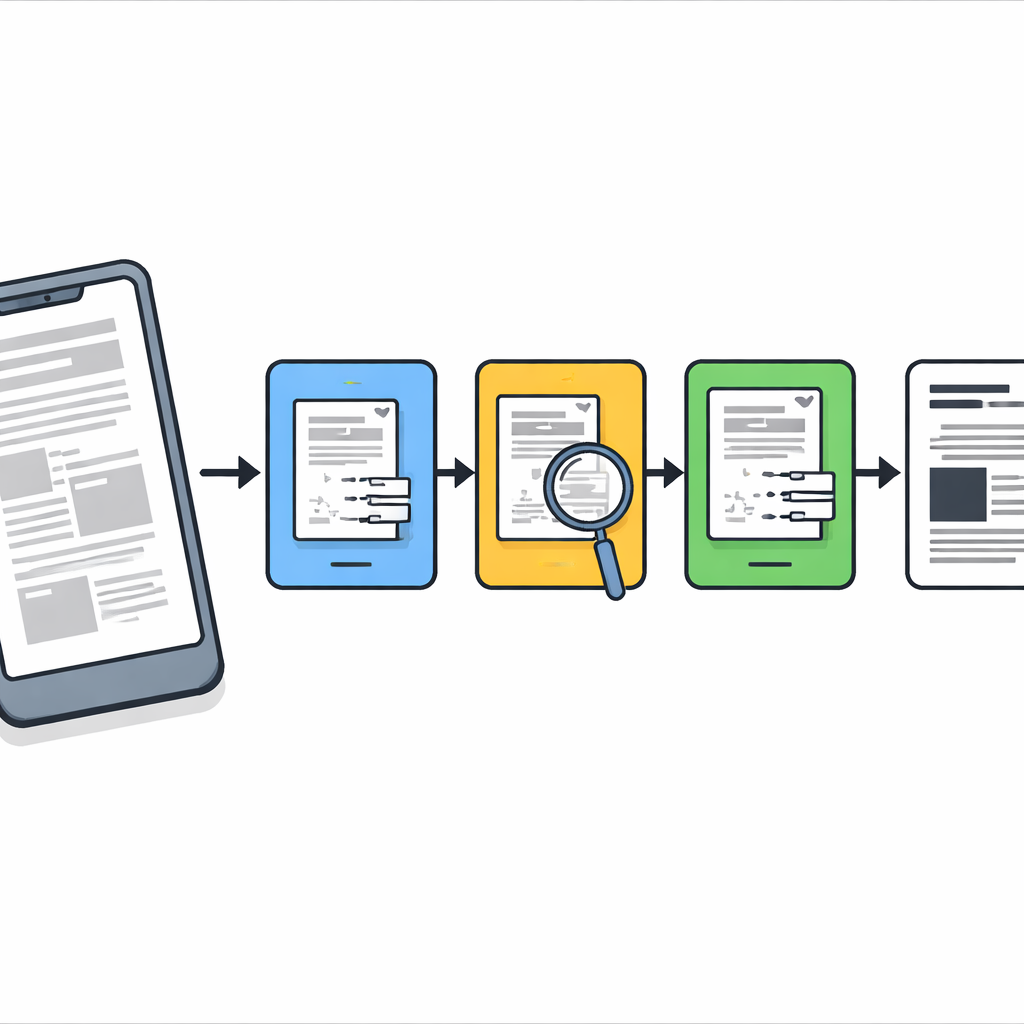
El problema de las fotos de documentos en el mundo real
Cuando fotografiamos documentos con teléfonos, el desenfoque rara vez es uniforme. Partes de una página pueden estar nítidas mientras otras zonas están fuera de foco o manchadas por movimiento o sombra. La mayoría de las herramientas tradicionales tratan la imagen completa como si el desenfoque fuera el mismo en todas partes, lo que a menudo conduce a suavizar en exceso el texto nítido o a no corregir las regiones muy dañadas. Los sistemas modernos de aprendizaje profundo pueden hacerlo mejor, pero requieren grandes conjuntos de datos etiquetados, potentes tarjetas gráficas y entrenamiento cuidadoso—recursos que no siempre están disponibles en oficinas, archivos o dispositivos de bajo coste. Los autores, en cambio, buscan un método ligero y sin entrenamiento que funcione bien en ordenadores y teléfonos comunes.
Una canalización de limpieza en tres etapas
Los investigadores diseñan una tubería paso a paso que actúa como un conservador digital cuidadoso. Primero, cada página capturada con cámara se endereza para que la hoja parezca un escaneo plano en lugar de una fotografía deformada tomada en ángulo. Luego, se aplica un procedimiento clásico de realce llamado deconvolución de Richardson–Lucy con una forma de desenfoque simple para restaurar con suavidad la nitidez general y resaltar trazos débiles. Tras esta etapa la página está más clara pero aún contiene zonas de desenfoque y ruido persistentes, por lo que el método no se detiene ahí.
Cómo el método detecta y corrige los puntos borrosos
La segunda etapa se centra en detectar exactamente dónde la página sigue estando borrosa. El sistema examina cada pequeño vecindario de dos maneras complementarias: en el dominio de la imagen normal utiliza una medida laplaciana de la fuerza local de los bordes (bordes nítidos suelen indicar texto claro, bordes débiles sugieren desenfoque), y en el dominio de la frecuencia inspecciona cuánto detalle fino se ha perdido. Combinando estas dos pistas, construye una máscara de desenfoque que separa las regiones borrosas de las no borrosas. Operaciones simples de limpieza de forma suavizan luego esta máscara hasta convertirla en bloques de texto coherentes en lugar de píxeles ruidosos dispersos.
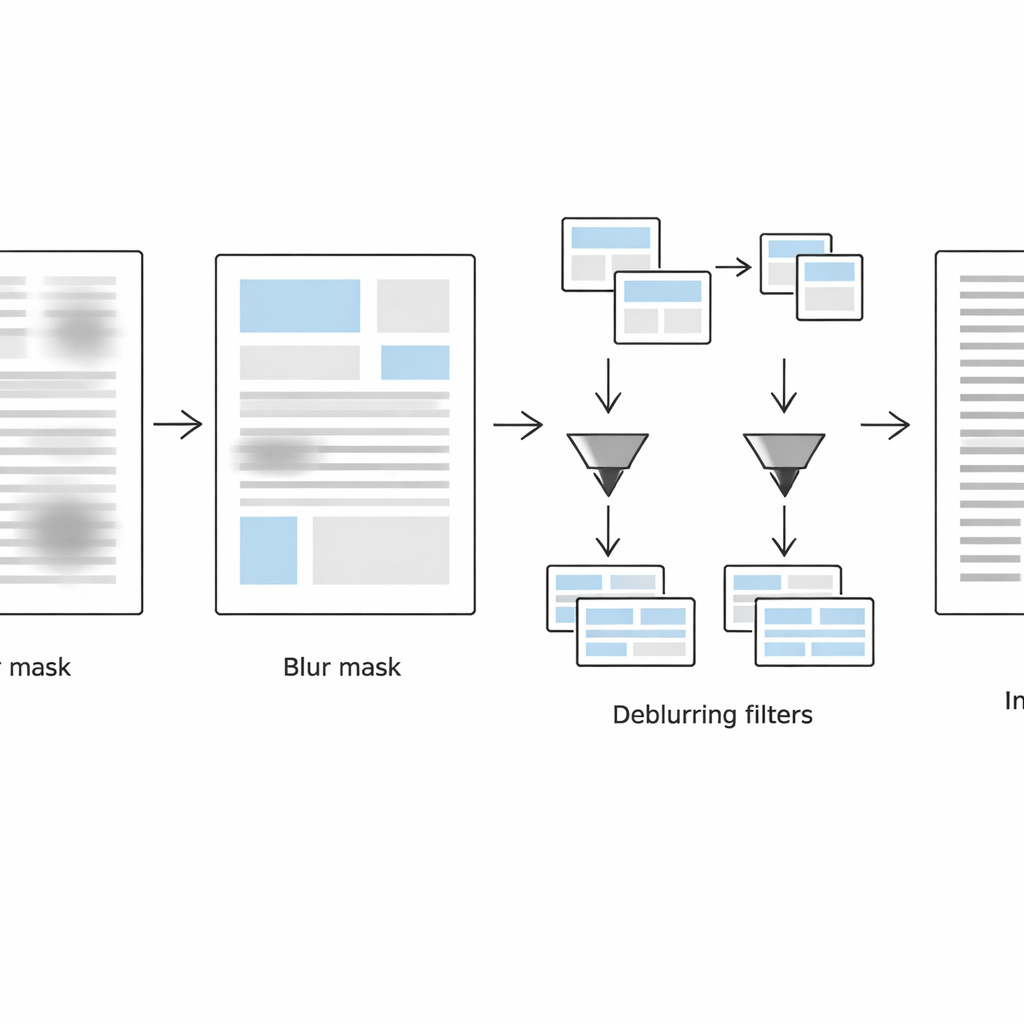
Tratar el texto nítido y el borroso de forma distinta
En la tercera etapa, la página se divide virtualmente en dos versiones: una que contiene principalmente bloques de texto borroso y otra con bloques mayormente nítidos, guiada por la máscara de desenfoque. Para cada conjunto de regiones, el método aplica una conversión adaptativa a blanco y negro afinada a las condiciones locales. Las regiones borrosas reciben ventanas de análisis mayores y ajustes de contraste más fuertes para recuperar trazos desvanecidos, mientras que las regiones ya nítidas se procesan con mayor suavidad para evitar crear artefactos granulares o romper trazos. El algoritmo guarda solo datos de ubicación para estas regiones—almacenados en archivos de metadatos ligeros—de modo que puede recombinar las piezas procesadas en un único documento binarizado, limpio y listo para el reconocimiento óptico de caracteres.
Qué tan bien funciona y por qué importa
Los autores prueban su enfoque en 417 imágenes reales de documentos tomadas con smartphone y en múltiples niveles de desenfoque, problemas de iluminación y ruido añadidos. Comparan su canalización con varios métodos populares de binarización y con sistemas modernos de restauración de imágenes, usando una amplia gama de puntuaciones de calidad y medidas directas de la precisión en el reconocimiento de texto. Tanto en niveles de desenfoque moderado como severo, su método preserva consistentemente más trazos, pierde menos caracteres y mantiene un rendimiento más estable que las alternativas, todo ello sin entrenar una red neuronal. Para los usuarios cotidianos, esto significa que las fotos con el móvil de apuntes, documentos legales o páginas históricas pueden convertirse en documentos más nítidos, legibles y buscables, incluso en hardware modesto y entornos con recursos limitados.
Cita: Karthik, U., Nair, B.J.B., Rani, N.S. et al. A hybrid spatial blur detection and restoration algorithm for smartphone captured document images. Sci Rep 16, 12648 (2026). https://doi.org/10.1038/s41598-026-38494-8
Palabras clave: restauración de imágenes de documentos, escaneos borrosos con teléfono, reconocimiento óptico de caracteres, mejora de imágenes, archivado digital