Clear Sky Science · pt
Um algoritmo híbrido de detecção espacial de desfoque e restauração para imagens de documentos capturadas por smartphone
Por que fotos borradas de papéis feitas com celulares importam
Quem já fotografou anotações, um formulário ou uma carta antiga com o celular conhece a frustração de tentar ler um texto borrado e irregular depois. O desfoque causado por mãos trêmulas, foco incorreto ou iluminação ruim não só irrita leitores humanos — também confunde softwares automáticos de leitura de texto usados em aplicativos de digitalização, arquivos e tribunais. Este artigo apresenta uma forma prática de resgatar essas fotos de documentos com defeito, transformando páginas bagunçadas e com desfoque desigual em imagens limpas em preto e branco, legíveis por computador, sem depender de modelos pesados de inteligência artificial.
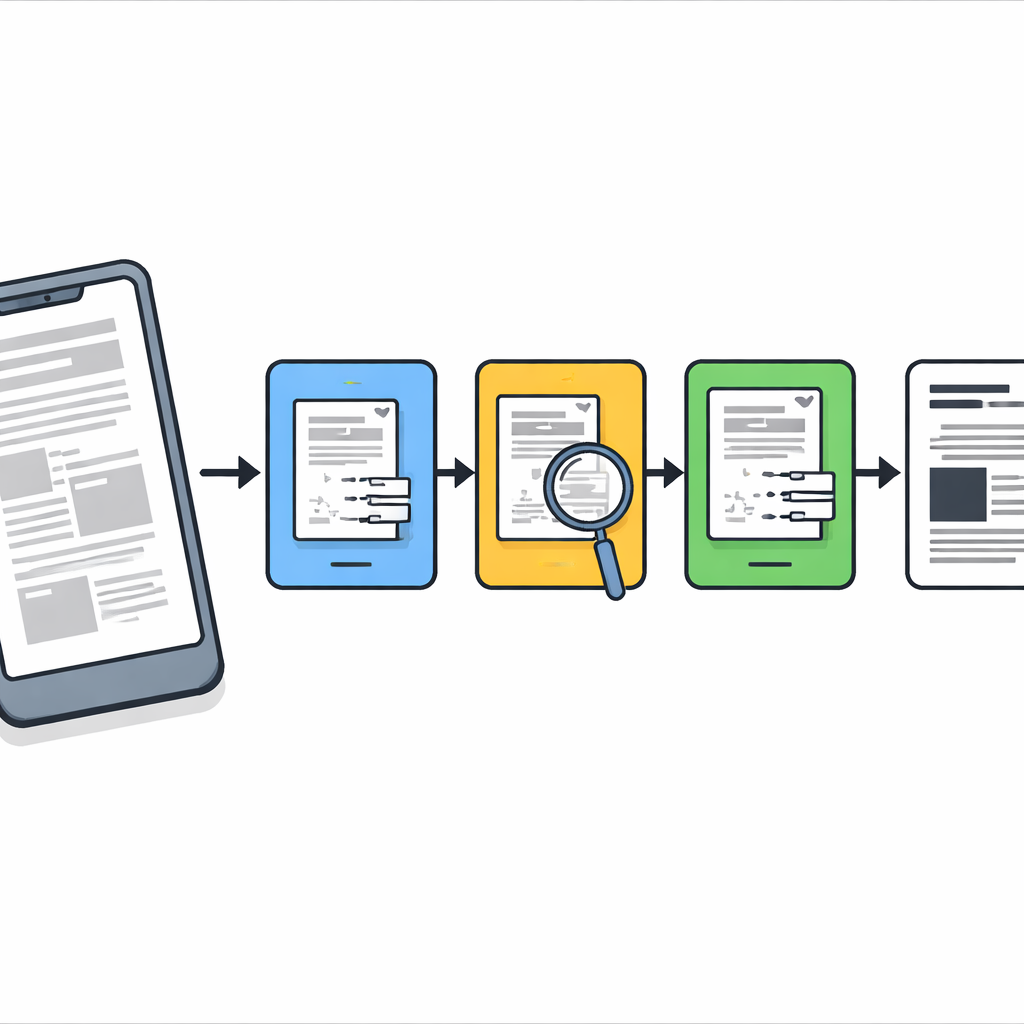
O problema das fotos de documentos no mundo real
Quando fotografamos documentos com celulares, o desfoque raramente é uniforme. Partes de uma página podem estar nítidas enquanto outras regiões ficam fora de foco ou borradas por movimento ou sombra. A maioria das ferramentas tradicionais trata a imagem inteira como se o desfoque fosse o mesmo em todos os pontos, o que frequentemente leva a suavização excessiva de texto nítido ou a falha em corrigir regiões muito danificadas. Sistemas modernos de aprendizado profundo conseguem resultados melhores, mas exigem grandes conjuntos de dados rotulados, placas gráficas potentes e treinamento cuidadoso — recursos que nem sempre estão disponíveis em escritórios, arquivos ou dispositivos de baixo custo. Os autores, em vez disso, buscam um método leve, sem treinamento, que funcione bem em computadores e celulares comuns.
Um pipeline de limpeza em três etapas
Os pesquisadores projetam um fluxo de trabalho passo a passo que age como um conservador digital cuidadoso. Primeiro, cada página capturada pela câmera é endireitada para que a folha pareça um escaneamento plano em vez de uma fotografia distorcida tirada em ângulo. Em seguida, aplica-se um procedimento clássico de nitidez chamado deconvolução de Richardson–Lucy com um formato simples de desfoque para restaurar suavemente a nitidez geral e realçar traços fracos. Após essa etapa a página fica mais clara, mas ainda contém pontos de desfoque persistentes e ruído, então o método não termina aí.
Como o método encontra e corrige manchas borradas
A segunda etapa concentra-se em detectar exatamente onde a página permanece borrada. O sistema analisa cada pequena vizinhança de duas maneiras complementares: no domínio da imagem normal, usa uma medida laplaciana da força de borda local (bordas nítidas indicam texto provavelmente claro, bordas fracas sugerem desfoque), e no domínio da frequência inspeciona quanto detalhe fino foi perdido. Combinando essas duas pistas, constrói uma máscara de desfoque que separa regiões borradas das não borradas. Operações simples de limpeza de forma então suavizam essa máscara em blocos de texto coerentes em vez de pixels ruidosos espalhados.
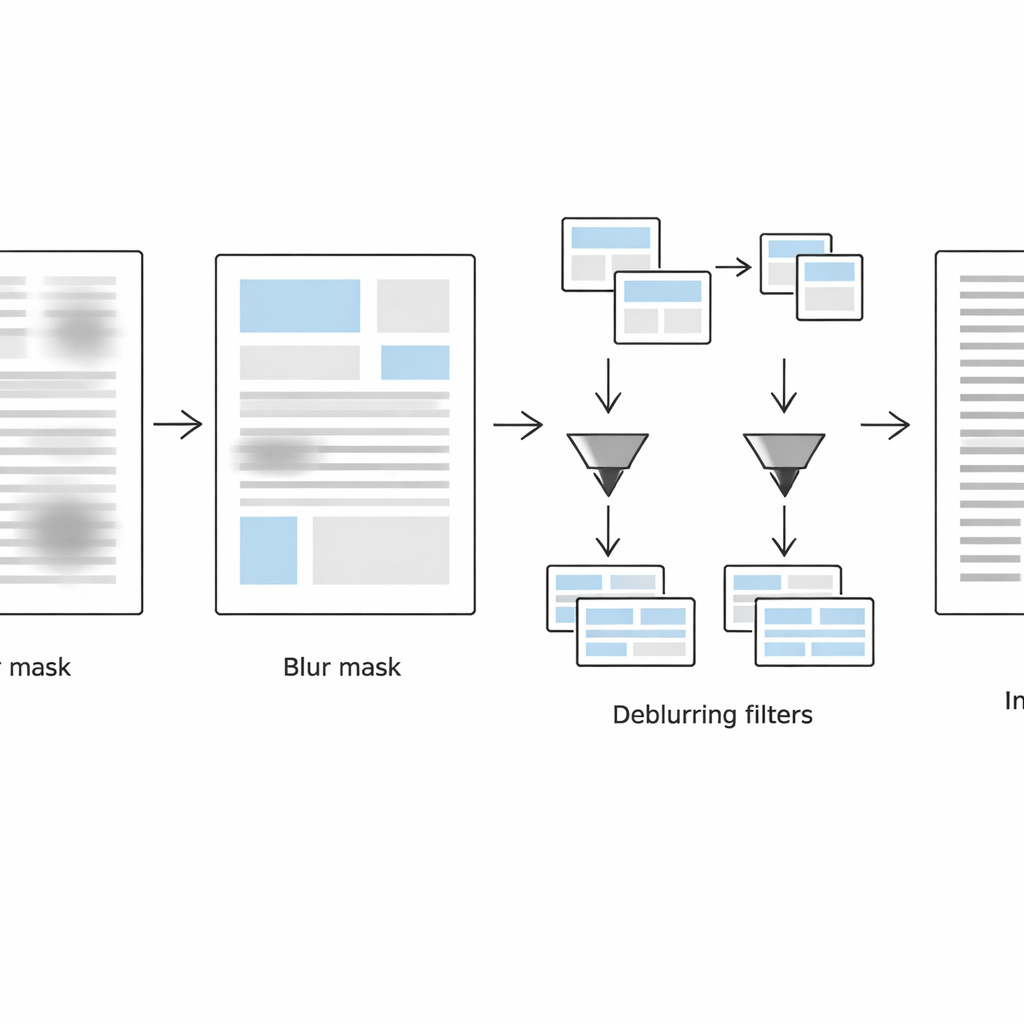
Tratar texto nítido e borrado de forma diferente
Na terceira etapa, a página é virtualmente dividida em duas versões: uma contendo principalmente blocos de texto borrado e outra contendo em sua maior parte blocos nítidos, guiadas pela máscara de desfoque. Para cada conjunto de regiões, o método aplica uma conversão adaptativa para preto e branco ajustada às condições locais. Regiões borradas recebem janelas de análise maiores e ajustes de contraste mais fortes para recuperar traços desbotados, enquanto regiões já nítidas são processadas com mais suavidade para evitar criar artefatos granulados ou quebrar traços. O algoritmo guarda apenas os dados de localização dessas regiões — armazenados em arquivos de metadados leves — para poder recombinar as peças processadas em um único documento binarizado, limpo e pronto para reconhecimento óptico de caracteres.
Quão bem funciona e por que isso importa
Os autores testam sua abordagem em 417 imagens reais de documentos feitas com smartphone e em múltiplos níveis de desfoque, problemas de iluminação e ruído adicionados. Eles comparam seu pipeline com vários métodos populares de binarização e com sistemas modernos de restauração de imagem, usando uma ampla gama de métricas de qualidade e medições diretas de precisão de reconhecimento de texto. Tanto em níveis moderados quanto severos de desfoque, o método deles preserva consistentemente mais traços, perde menos caracteres e mantém um desempenho mais estável que as alternativas, tudo isso sem treinar uma rede neural. Para usuários do dia a dia, isso significa que fotos de anotações, documentos legais ou páginas históricas feitas com o celular podem ser transformadas em documentos mais nítidos, legíveis e pesquisáveis, mesmo em hardware modesto e em ambientes com recursos limitados.
Citação: Karthik, U., Nair, B.J.B., Rani, N.S. et al. A hybrid spatial blur detection and restoration algorithm for smartphone captured document images. Sci Rep 16, 12648 (2026). https://doi.org/10.1038/s41598-026-38494-8
Palavras-chave: restauração de imagem de documento, digitalizações borradas de smartphone, reconhecimento óptico de caracteres, melhoria de imagem, arquivamento digital