Clear Sky Science · pl
Hybrydowy algorytm wykrywania i przywracania rozmycia przestrzennego w zdjęciach dokumentów wykonanych smartfonem
Dlaczego rozmyte zdjęcia dokumentów ze smartfona mają znaczenie
Każdy, kto fotografował telefonem notatki, formularz czy stary list, zna frustrację związaną z późniejszym odczytywaniem rozmazanego, nierównomiernego tekstu. Rozmycie spowodowane drżącymi rękami, złym ostrojeniem czy słabym oświetleniem nie tylko irytuje ludzi — wprowadza też w błąd automatyczne oprogramowanie do odczytu tekstu używane w aplikacjach skanujących, archiwach i instytucjach. Artykuł przedstawia praktyczny sposób ratowania takich wadliwych zdjęć dokumentów, przekształcając zabałaganione, nierównomiernie rozmyte strony w czyste, komputerowo czytelne obrazy czarno-białe bez polegania na ciężkich modelach sztucznej inteligencji.
Problem ze zdjęciami dokumentów w warunkach rzeczywistych
Gdy fotografujemy dokumenty telefonem, rozmycie rzadko jest jednorodne. Części strony mogą być ostre, podczas gdy inne rejony są nieostre lub rozmazane przez ruch czy cień. Większość tradycyjnych narzędzi oczyszczających traktuje cały obraz, jakby rozmycie było takie samo wszędzie, co często prowadzi do nadmiernego wygładzenia ostrych liter lub do nieskutecznego naprawiania poważnie uszkodzonych fragmentów. Nowoczesne systemy głębokiego uczenia radzą sobie lepiej, lecz wymagają dużych oznakowanych zbiorów danych, wydajnych kart graficznych i starannego szkolenia — zasobów, które nie zawsze są dostępne w biurach, archiwach czy na tanich urządzeniach. Autorzy celują zamiast tego w lekką, nie wymagającą treningu metodę, która dobrze działa na zwykłych komputerach i telefonach.
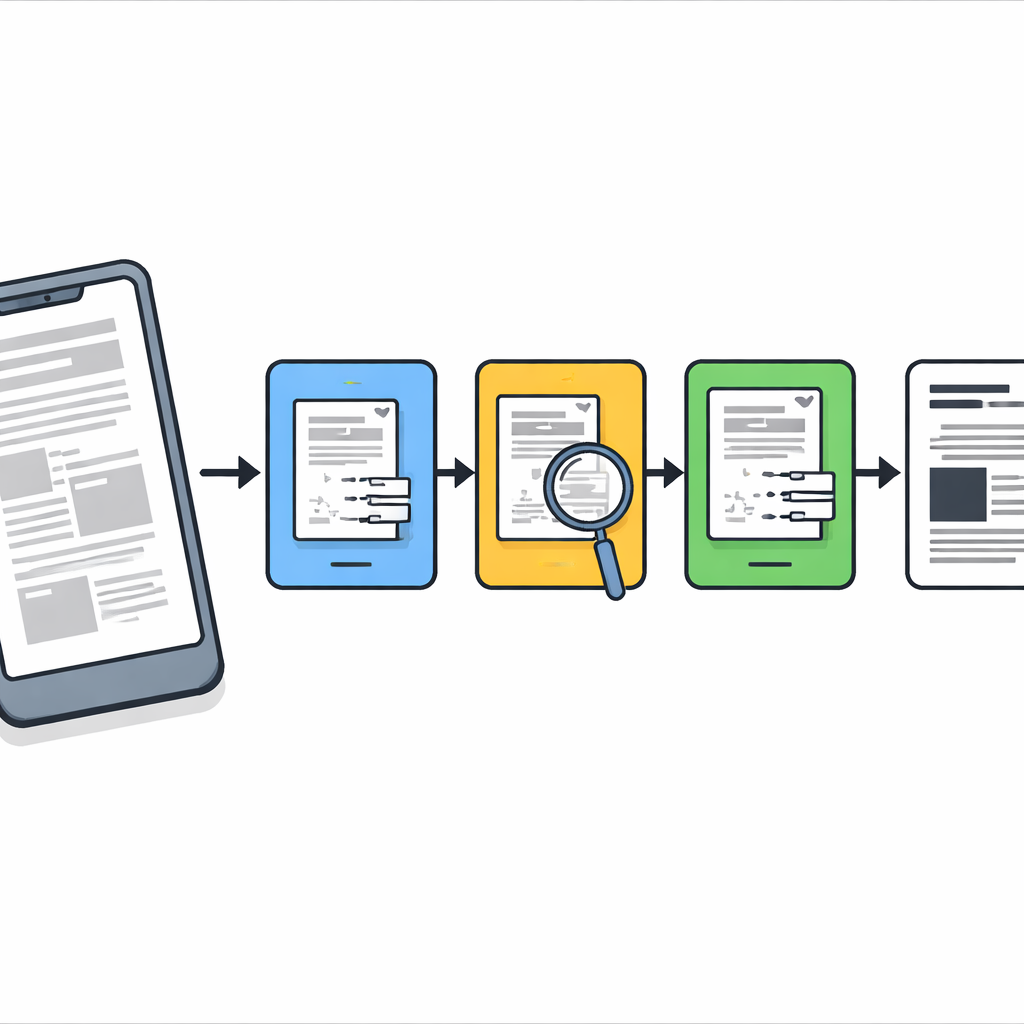
Trzystopniowy proces oczyszczania
Naukowcy zaprojektowali etapowy pipeline, który działa jak ostrożny cyfrowy konserwator. Najpierw każda strona zrobiona aparatem jest wyprostowana, tak aby arkusz wyglądał jak płaski skan, a nie zniekształcone zdjęcie wykonane pod kątem. Następnie stosuje się klasyczny zabieg wyostrzający, zwany dekonwolucją Richardsona–Lucy’ego, z prostym profilem rozmycia, by delikatnie przywrócić ogólną ostrość i uwydatnić słabe kreski. Po tym etapie strona jest jaśniejsza, ale wciąż zawiera miejsca uporczywego rozmycia i szumu, dlatego metoda nie kończy się na tym kroku.
Jak metoda wykrywa i naprawia rozmyte miejsca
Drugi etap koncentruje się na wykryciu dokładnych miejsc, które wciąż są rozmyte. System analizuje każde małe sąsiedztwo dwiema komplementarnymi metodami: w zwykłej domenie obrazu korzysta z miary Laplace’a siły krawędzi lokalnych (ostre krawędzie zwykle oznaczają wyraźny tekst, słabe krawędzie sugerują rozmycie), a w domenie częstotliwości bada, ile drobnych detali zostało utraconych. Łącząc te dwa wskaźniki, buduje maskę rozmycia, która oddziela regiony rozmyte od nierozmytych. Proste operacje oczyszczania kształtów wygładzają następnie tę maskę, tworząc spójne bloki tekstu zamiast porozrzucanych szumem pikseli.
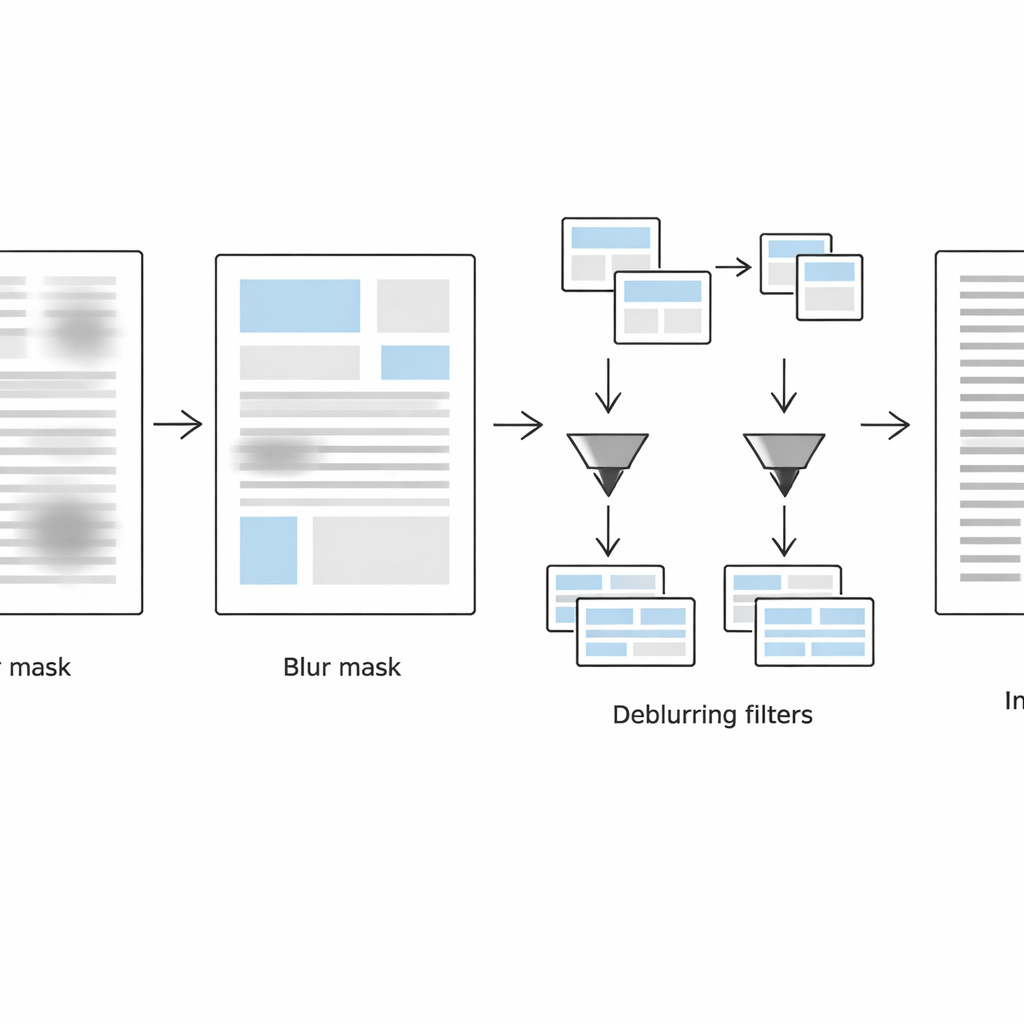
Różne traktowanie ostrego i rozmytego tekstu
W trzecim etapie strona jest wirtualnie podzielona na dwie wersje: jedną zawierającą głównie rozmyte bloki tekstu, a drugą złożoną przeważnie z ostrych fragmentów, sterowaną przez maskę rozmycia. Dla każdego zestawu regionów metoda stosuje adaptacyjną konwersję do czerni i bieli dostosowaną do lokalnych warunków. Regiony rozmyte otrzymują większe okna analizy i silniejsze korekty kontrastu, aby odzyskać wyblakłe kreski, podczas gdy obszary już ostre są przetwarzane łagodniej, by uniknąć ziarnistości lub przerywania kresek. Algorytm przechowuje jedynie dane o położeniu tych regionów — zapisywane w lekkich plikach metadanych — dzięki czemu może połączyć przetworzone fragmenty w jeden, czysty, binarizowany dokument gotowy do optycznego rozpoznawania znaków.
Skuteczność i znaczenie metody
Autorzy testują swoje podejście na 417 rzeczywistych zdjęciach dokumentów ze smartfonów oraz na wielu poziomach dodanego rozmycia, problemów z oświetleniem i szumu. Porównują swój pipeline z kilkoma popularnymi metodami binarizacji oraz z nowoczesnymi systemami przywracania obrazu, używając szerokiego zakresu miar jakości i bezpośrednich pomiarów dokładności rozpoznawania tekstu. Zarówno przy umiarkowanym, jak i silnym rozmyciu ich metoda konsekwentnie zachowuje więcej kresek, traci mniej znaków i utrzymuje stabilniejszą wydajność niż alternatywy — i to wszystko bez trenowania sieci neuronowej. Dla zwykłych użytkowników oznacza to, że zdjęcia notatek, dokumentów prawnych czy stron historycznych wykonane telefonem mogą zostać przekształcone w ostrzejsze, bardziej czytelne i łatwiejsze do przeszukiwania dokumenty, nawet na skromnym sprzęcie i w środowiskach o ograniczonych zasobach.
Cytowanie: Karthik, U., Nair, B.J.B., Rani, N.S. et al. A hybrid spatial blur detection and restoration algorithm for smartphone captured document images. Sci Rep 16, 12648 (2026). https://doi.org/10.1038/s41598-026-38494-8
Słowa kluczowe: odtwarzanie obrazu dokumentu, rozmyte skany ze smartfona, optyczne rozpoznawanie znaków, poprawa obrazu, archiwizacja cyfrowa