Clear Sky Science · de
Ein hybrider räumlicher Unschärfe-Erkennungs- und Wiederherstellungsalgorithmus für mit dem Smartphone aufgenommene Dokumentbilder
Warum verschwommene Handyfotos von Papier wichtig sind
Wer schon einmal Notizen, ein Formular oder einen alten Brief mit dem Handy fotografiert hat, kennt die Frustration, danach verschmierte oder ungleichmäßige Schrift zu entziffern. Unschärfe durch zittrige Hände, falschen Fokus oder schlechtes Licht stört nicht nur menschliche Leser — sie verwirrt auch automatische Texterkennungsprogramme, die in Scan-Apps, Archiven und Gerichten eingesetzt werden. Dieses Paper stellt eine praxisnahe Methode vor, um solche fehlerhaften Dokumentfotos zu retten und ungleichmäßig verschwommene Seiten in saubere, computerlesbare Schwarz-Weiß-Bilder zu verwandeln, ohne auf schwere KI-Modelle angewiesen zu sein.
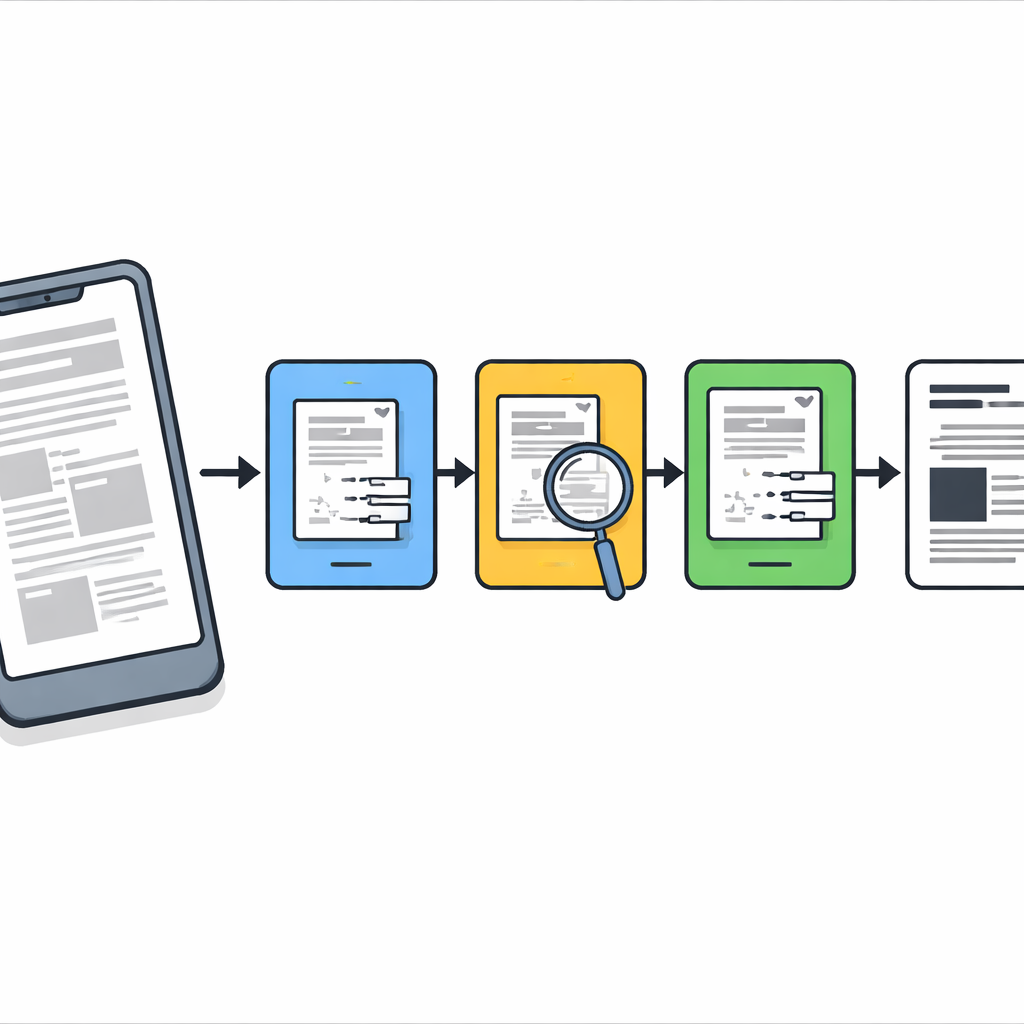
Das Problem bei realen Dokumentfotos
Wenn wir Dokumente mit dem Telefon fotografieren, ist die Unschärfe selten gleichmäßig. Teile einer Seite können scharf sein, während andere Bereiche unscharf, durch Bewegung verwischt oder von Schatten betroffen sind. Die meisten traditionellen Reinigungswerkzeuge behandeln das ganze Bild so, als sei die Unschärfe überall gleich — das führt oft dazu, dass scharfe Schrift zu stark geglättet wird oder stark beschädigte Bereiche nicht korrigiert werden. Moderne Deep-Learning-Systeme können das besser, benötigen aber große gelabelte Datensätze, leistungsfähige Grafikchips und sorgfältiges Training — Ressourcen, die in Büros, Archiven oder günstigen Geräten nicht immer verfügbar sind. Die Autoren zielen stattdessen auf eine leichte, trainingsfreie Methode ab, die auf normalen Computern und Telefonen gut funktioniert.
Eine dreistufige Bereinigungspipeline
Die Forschenden entwickeln eine Schritt-für-Schritt-Pipeline, die wie ein sorgfältiger digitaler Konservator arbeitet. Zunächst wird jede mit der Kamera aufgenommene Seite begradigt, sodass das Blatt wie ein flacher Scan statt wie ein aus der Perspektive aufgenommenes Foto wirkt. Anschließend wird ein klassisches Schärfverfahren, die Richardson–Lucy-Dekonvolution, mit einer einfachen Unschärfeform angewendet, um die Gesamtschärfe behutsam wiederherzustellen und schwache Striche hervorzuheben. Nach diesem Schritt ist die Seite klarer, enthält aber weiterhin hartnäckige Unschärfe und Rauschen, sodass die Methode hier nicht aufhört.
Wie die Methode verschwommene Stellen findet und behebt
Die zweite Stufe konzentriert sich darauf, genau zu erkennen, wo die Seite noch unscharf ist. Das System betrachtet jede kleine Nachbarschaft auf zwei komplementäre Arten: Im normalen Bildraum nutzt es ein Laplace-Maß zur lokalen Kantenschärfe (scharfe Kanten deuten auf klare Schrift hin, schwache Kanten auf Unschärfe) und im Frequenzraum untersucht es, wie viele feine Details verloren gegangen sind. Durch die Kombination dieser beiden Hinweise erstellt es eine Unschärfemaske, die verschwommene von nicht-verschwommenen Regionen trennt. Einfache Formbereinigungsoperationen glätten diese Maske anschließend zu zusammenhängenden Textblöcken statt zu verstreuten, verrauschten Pixeln.
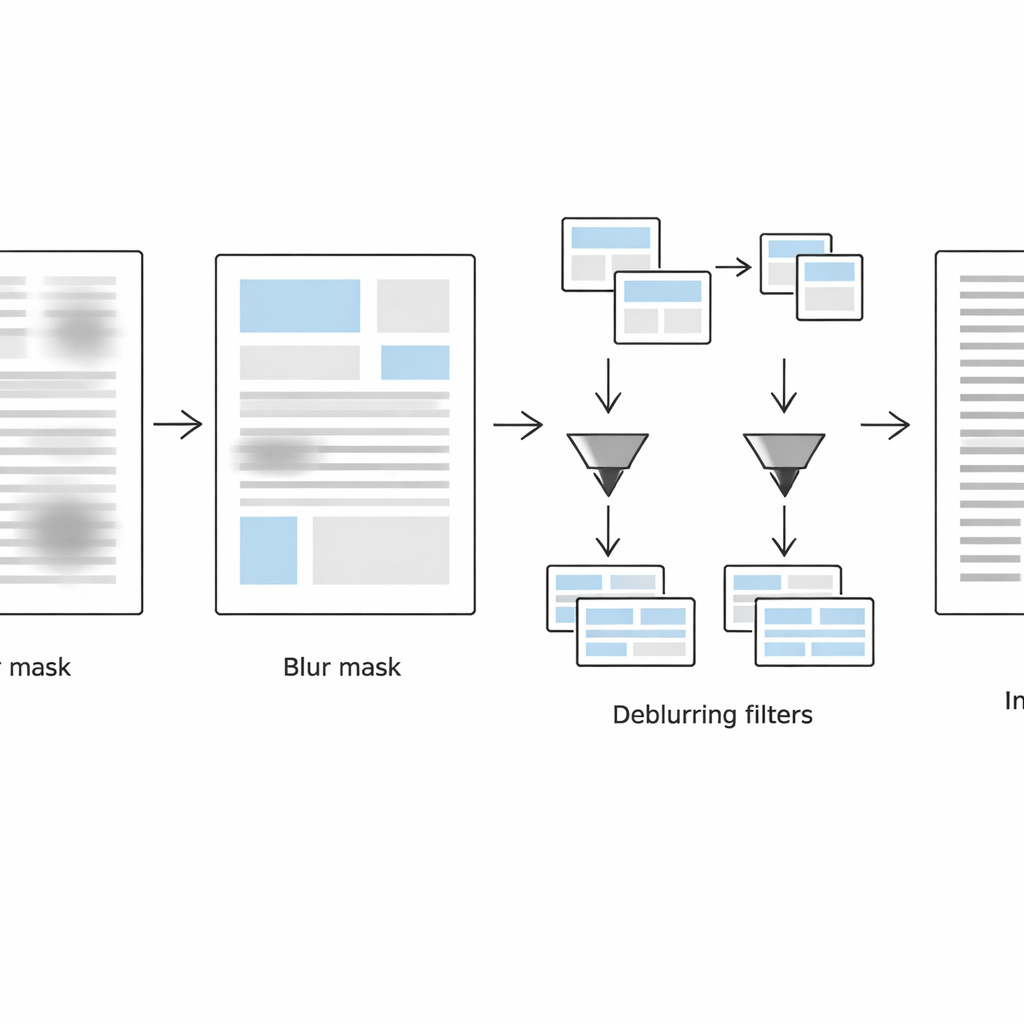
Scharfe und verschwommene Schrift unterschiedlich behandeln
In der dritten Stufe wird die Seite virtuell in zwei Versionen aufgeteilt: eine, die hauptsächlich verschwommene Textblöcke enthält, und eine, die überwiegend scharfe Regionen enthält, gesteuert von der Unschärfemaske. Für jede Regionengruppe wendet die Methode eine adaptive Schwarz-Weiß-Umwandlung an, die an lokale Bedingungen angepasst ist. Verschwommene Bereiche erhalten größere Analysefenster und stärkere Kontrastanpassungen, um verblasste Striche wiederherzustellen, während bereits scharfe Bereiche schonender behandelt werden, um körnige Artefakte oder das Zerstören von Strichen zu vermeiden. Der Algorithmus speichert nur Positionsdaten für diese Regionen — in leichtgewichtigen Metadatendateien — sodass er die verarbeiteten Teile zu einem einzigen, sauberen, binarisierten Dokument zusammenfügen kann, das für die optische Zeichenerkennung bereit ist.
Wie gut es funktioniert und warum es wichtig ist
Die Autoren testen ihren Ansatz an 417 realen Smartphone-Dokumentbildern sowie an mehreren Stufen hinzugefügter Unschärfe, Beleuchtungsproblemen und Rauschen. Sie vergleichen ihre Pipeline mit mehreren verbreiteten Binarisierungsmethoden und modernen Bildwiederherstellungssystemen, wobei sie eine breite Palette von Qualitätsmaßen und direkte Messungen der Texterkennungsgenauigkeit verwenden. Sowohl bei moderater als auch bei starker Unschärfe erhält ihre Methode konstant mehr erhaltene Striche, verliert weniger Zeichen und zeigt stabilere Leistung als die Alternativen — und das alles ohne ein neuronales Netz zu trainieren. Für Alltagsnutzer bedeutet das, dass Handyfotos von Notizen, Rechtsdokumenten oder historischen Seiten auch mit bescheidener Hardware und in ressourcenbegrenzten Umgebungen in schärfere, besser lesbare und durchsuchbare Dokumente verwandelt werden können.
Zitation: Karthik, U., Nair, B.J.B., Rani, N.S. et al. A hybrid spatial blur detection and restoration algorithm for smartphone captured document images. Sci Rep 16, 12648 (2026). https://doi.org/10.1038/s41598-026-38494-8
Schlüsselwörter: Wiederherstellung von Dokumentbildern, verschwommene Smartphone-Scans, optische Zeichenerkennung, Bildverbesserung, digitale Archivierung