Clear Sky Science · sv
Sign4all: en dataset för spansk teckenspråk
Händer som talar med maskiner
Miljontals människor världen över förlitar sig på teckenspråk som sitt främsta kommunikationssätt, ändå ”lyssnar” de flesta av dagens appar och prylar fortfarande bara på talade ord. För att överbrygga detta gap behöver datorer stora, noggrant utformade samlingar av teckenspråksvideor att lära sig från. Denna artikel presenterar Sign4all, en ny dataset för spansk teckenspråk framtagen för att hjälpa framtida telefoner, bärbara datorer och offentliga enheter att förstå vardagliga tecken mer rättvist och med högre precision.
Varför nytt data för teckenspråk behövs
Röstassistenter har förbättrats snabbt eftersom de tränats på enorma ljudsamlingar. Teckenspråk har inte haft samma framsteg. Befintliga teckendatamängder försöker ofta täcka tusentals olika ord men visar varje ord bara ett fåtal gånger. Det gör det svårt för en dator att lära sig hur samma tecken kan se lite olika ut mellan personer, kläder, hastighet eller kameravinkel. Många samlingar spelar också in endast högerhänta tecknare, trots att en betydande del av befolkningen tecknar med vänster hand eller använder båda. Som en följd kan system som tränats på dessa data misslyckas när de stöter på vänsterhänta tecknare eller subtila variationer i rörelse.
Ett fokuserat ordförråd från vardagslivet
I stället för att sträva efter ren bredd tar Sign4all ett ”litet men djupt” angreppssätt. Författarna spelade in 24 vanliga tecken från spanska teckenspråket relaterade till att äta ute och dagliga måltider: pronomen som ”jag” och ”du”, maträtter som kött, fisk och soppa, bestick som sked och gaffel samt frågeord inklusive ”vad”, ”var” och ”när”. För varje tecken finns i genomsnitt mer än 300 högupplösta videoklipp, vilket ger inlärningsalgoritmer många exempel på hur varje gest kan variera. Ordförrådet valdes också så att tecken kan kombineras till korta meningar, till exempel ”jag gillar inte kött” eller ”jag har kött och ägg till frukost”, vilket låter forskare utforska enkel frasigenkänning i framtiden.
Bygga balans mellan vänster och höger
Ett viktigt designval var att behandla vänsterhänt och högerhänt tecknande som lika viktigt. Åtta frivilliga (fyra kvinnor och fyra män) spelades in i ett laboratorium med en högkvalitativ kamera. Var och en av dem utförde varje enhands- eller ojämnt tvåhands-tecken med både sin dominanta och icke-dominanta hand. Symmetriska tvåhands-tecken spelades in med extra repetitionsomgångar så att varje teckenklass slutade med ungefär samma antal klipp. Efter noggrann manuell klippning innehåller den slutliga samlingen 7 756 videor, nästan perfekt delade mellan vänster- och högerhändiga uppvisningar. Denna balans låter framtida igenkänningssystem lära sig att bortse från vilken hand som leder rörelsen och i stället fokusera på själva mönstret.
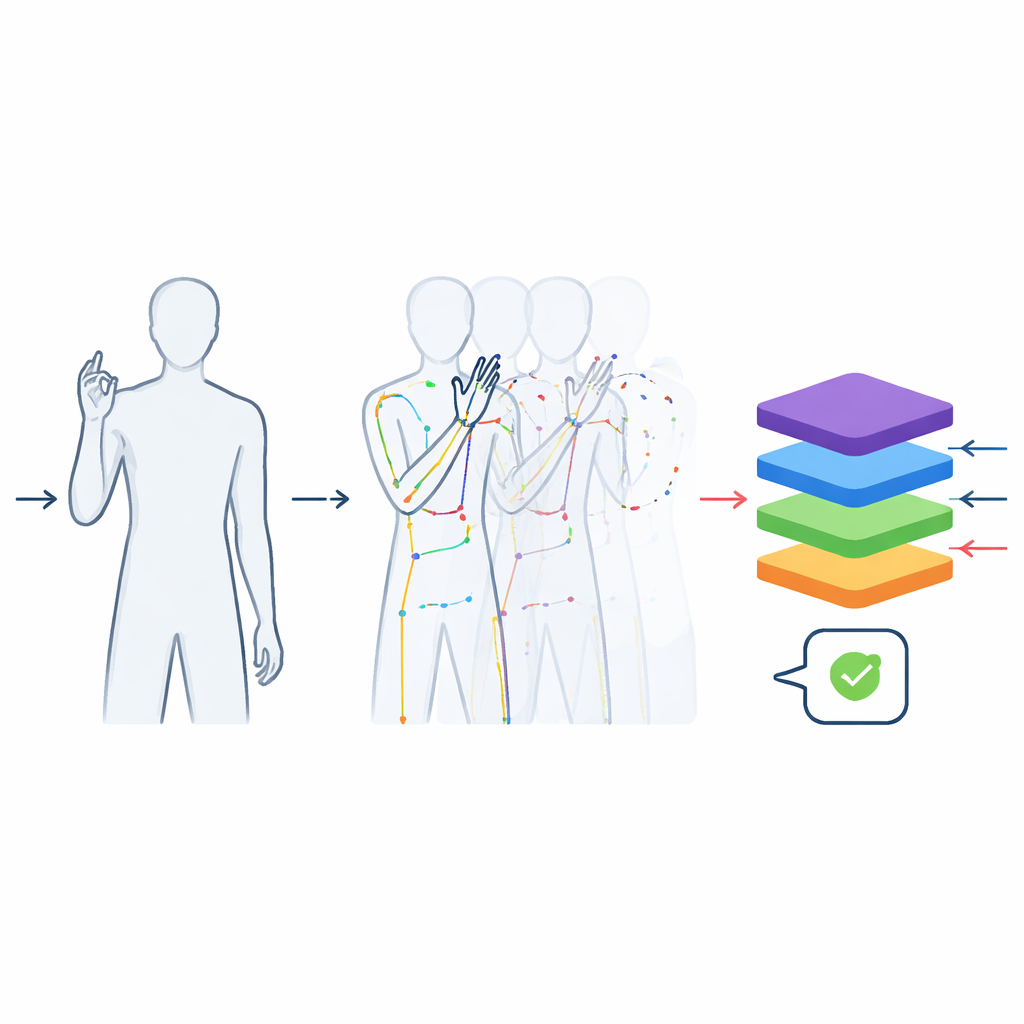
Förvandla rika videor till ren rörelsedata
Inspelningarna bearbetades för att göra dem så användbara som möjligt för maskininlärning. Varje video klipptes så att den bara innehåller själva tecknet, inte rörelsen in i eller ut ur position. Alla klipp standardiserades till 48 ramar—tillräckligt länge för att fånga en typisk gest—så att modeller inte kan fuska genom att enbart använda klippets längd för att gissa ordet. Bildrutorna beskars runt tecknaren för att ta bort tak och golv samtidigt som den naturliga kroppssilhuetten bevarades, vilket undviker förvrängningar som skulle uppstå om rå, rektangulär film slumpmässigt ändrats i storlek. Utöver färgvideorna använde teamet ett pose‑spårningsverktyg för att extrahera positionerna för nyckelleder i överkroppen och fingrarna, och byggde en kompakt ”käppfigur”-beskrivning bildruta för bildruta. Dessa skelett lagras i allmänt använda vetenskapliga format så att de kan kopplas direkt in i modern djupinlärningsprogramvara.
Att lära datorer med variation, inte perfektion
Verkliga miljöer är röriga: människor bär olika kläder, ljusförhållanden ändras under dagen och kameror skakar lätt. För att hjälpa system hantera sådan variation skapade författarna extra, förbearbetade versioner av datasetet. Vissa klipp speglas vänster–höger för att simulera motsatt hand; andra förändras med små justeringar i ljusstyrka, färg, oskärpa eller rotation, utan att tecknets betydelse skadas. Detta ökade det totala antalet prover till mer än 60 000. Tester med en video‑baserad Transformer‑modell—en modern typ av neuralt nätverk—visade att träning med dessa förhöjda data avsevärt förbättrade igenkänningens prestanda. En enklare modell som tränades enbart på det skelettbaserade rörelsedata nådde också hög noggrannhet, vilket bevisar att datasetet fångar den väsentliga information som behövs för att skilja liknande tecken åt.
Vad detta betyder för inkluderande teknik
För en lekmannapublik är budskapet från Sign4all tydligt: ju bättre och rättvisare övningsmaterial vi ger våra maskiner, desto bättre blir de på att förstå personer som tecknar. Genom att erbjuda tusentals högkvalitativa, balanserade exempel på vardagliga spanska tecken—tillsammans med färdiga rörelsebeskrivningar och standardiserade träningsdelningar—lägger denna dataset grunden för mer pålitliga system för teckenspråksigenkänning. Med tiden skulle sådana verktyg kunna stödja realtidsundertexter, mer tillgängliga offentliga tjänster och smidigare kommunikation mellan döva och hörande samhällen, vilket hjälper till att säkerställa att digital teknik lyssnar på händer lika väl som på röster.
Citering: Morillas-Espejo, F., Martinez-Martin, E. Sign4all: a Spanish Sign Language dataset. Sci Data 13, 502 (2026). https://doi.org/10.1038/s41597-026-06872-6
Nyckelord: teckenspråksigenkänning, spanskt teckenspråk, gestdatamängder, hjälpteknik, maskininlärning