Clear Sky Science · es
Sign4all: un conjunto de datos de Lengua de Signos Española
Manos que hablan con máquinas
Millones de personas en todo el mundo dependen de las lenguas de signos como su forma principal de comunicarse, pero la mayoría de las aplicaciones y dispositivos actuales todavía «oyen» solo palabras habladas. Para salvar esa brecha, los ordenadores necesitan grandes colecciones de vídeos de lengua de signos, cuidadosamente diseñadas, para aprender. Este artículo presenta Sign4all, un nuevo conjunto de datos de Lengua de Signos Española creado para ayudar a que futuros teléfonos, portátiles y dispositivos públicos comprendan los signos cotidianos de manera más justa y precisa.
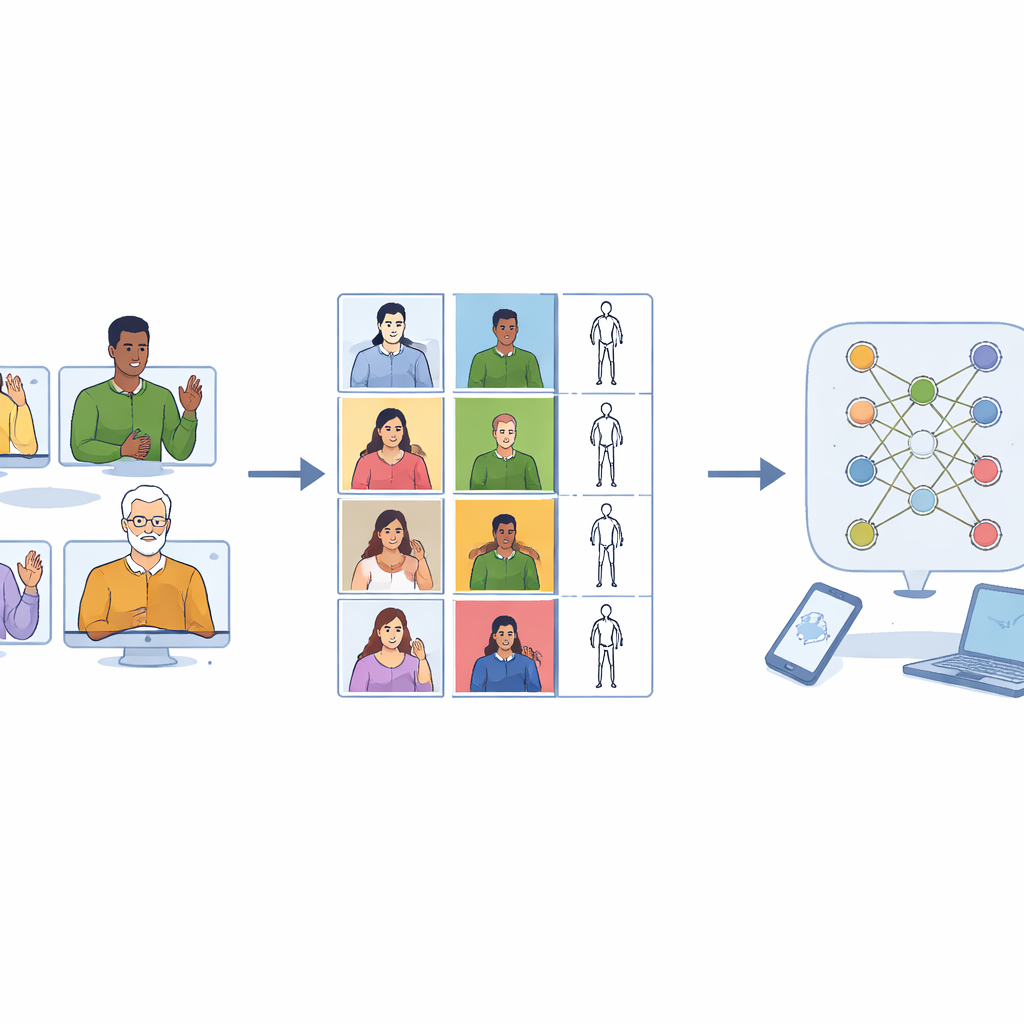
Por qué se necesitan nuevos datos para la lengua de signos
Los asistentes de voz han mejorado rápidamente porque se entrenaron con vastas colecciones de audio. Las lenguas de signos no han disfrutado del mismo progreso. Los conjuntos de datos existentes a menudo intentan cubrir miles de palabras diferentes pero muestran cada una solo unas pocas veces. Eso dificulta que un ordenador aprenda cómo un mismo signo puede verse ligeramente distinto según la persona, la ropa, la velocidad o el ángulo de cámara. Muchas colecciones también graban solo a personas que signan con la mano derecha, aunque una parte considerable de la población usa la mano izquierda o ambas. Como resultado, los sistemas entrenados con estos datos pueden fallar al encontrarse con firmantes zurdos o con variaciones sutiles en el movimiento.
Un vocabulario centrado en la vida cotidiana
En lugar de aspirar solo a la amplitud, Sign4all adopta un enfoque de «poco pero profundo». Los autores grabaron 24 signos comunes de la Lengua de Signos Española relacionados con comer fuera y las comidas diarias: pronombres como «yo» y «tú», alimentos como carne, pescado y sopa, utensilios como cuchara y tenedor, y palabras interrogativas como «qué», «dónde» y «cuándo». Para cada signo hay en promedio más de 300 clips de vídeo de alta resolución, dando a los algoritmos de aprendizaje muchos ejemplos de cómo puede variar cada gesto. El vocabulario también se eligió para que los signos puedan combinarse en frases cortas, como «no me gusta la carne» o «tengo carne y huevos en el desayuno», permitiendo a los investigadores explorar en el futuro el reconocimiento de frases simples.
Construir equilibrio entre zurdos y diestros
Una decisión clave de diseño fue tratar el firmado con la mano izquierda y la mano derecha como igualmente importante. Ocho voluntarios (cuatro mujeres y cuatro hombres) fueron grabados en un laboratorio con una cámara de alta calidad. Cada uno de ellos realizó cada signo de una mano o los signos asimétricos de dos manos tanto con su mano dominante como con la no dominante. Los signos simétricos de dos manos se grabaron con repeticiones adicionales para que cada clase de signo tuviera al final un número de clips aproximadamente igual. Tras un recorte manual cuidadoso, la colección final incluye 7.756 vídeos, casi perfectamente repartidos entre ejecuciones zurdas y diestras. Este equilibrio permite a futuros sistemas de reconocimiento aprender a ignorar qué mano lidera el movimiento y centrarse en el patrón en sí.
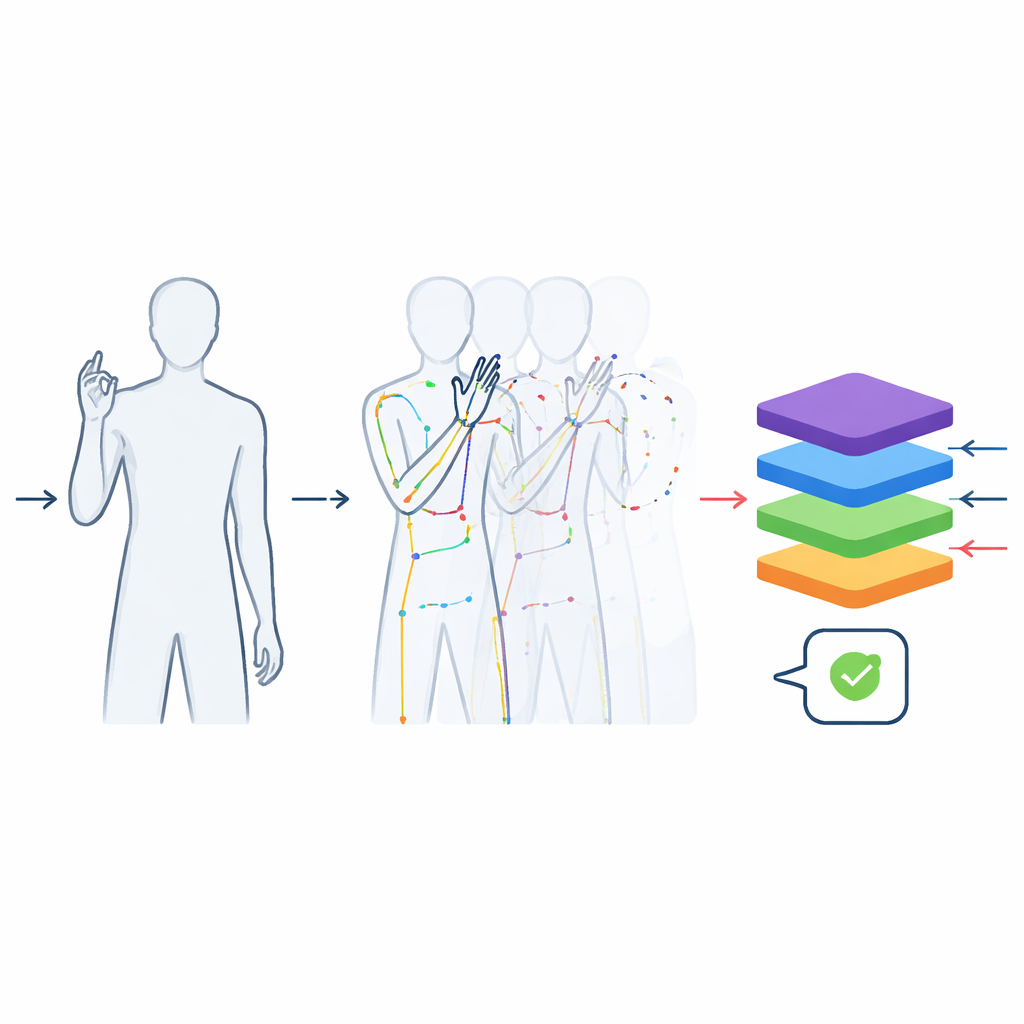
Convertir vídeos ricos en datos de movimiento limpios
Las grabaciones se procesaron para que fueran lo más útiles posible para el aprendizaje automático. Cada vídeo se recortó para que contuviera solo el signo real, no el movimiento de entrar o salir de la posición. Todos los clips se estandarizaron a 48 fotogramas—lo bastante largos para capturar un gesto típico—para que los modelos no puedan hacer trampa usando simplemente la duración del clip para adivinar la palabra. Las imágenes se recortaron alrededor del firmante para eliminar el techo y el suelo a la vez que se preserva la forma corporal natural, evitando distorsiones que aparecerían si el metraje rectangular bruto se redimensionara al azar. Además de los vídeos en color, el equipo usó una herramienta de seguimiento de pose para extraer las posiciones de las articulaciones clave del torso superior y los dedos, construyendo una descripción compacta tipo «muñeco de palo» fotograma a fotograma. Estos esqueletos se almacenan en formatos científicos ampliamente usados para que puedan integrarse directamente en el software moderno de aprendizaje profundo.
Enseñar a las máquinas con variación, no con perfección
Los entornos del mundo real son caóticos: la gente viste de forma distinta, la iluminación cambia durante el día y las cámaras se mueven ligeramente. Para ayudar a los sistemas a lidiar con esa variación, los autores crearon versiones adicionales preprocesadas del conjunto de datos. Algunos clips se invirtieron horizontalmente para simular la mano opuesta; otros se alteraron con pequeños cambios de brillo, color, desenfoque o rotación, sin alterar el significado del signo. Esto elevó el número total de muestras a más de 60.000. Pruebas con un modelo Transformer basado en vídeo—un tipo moderno de red neuronal—mostraron que entrenar con estos datos enriquecidos mejoró de forma notable el rendimiento de reconocimiento. Un modelo más simple entrenado solo con los datos de movimiento esquelético también alcanzó alta precisión, demostrando que el conjunto captura la información esencial necesaria para distinguir signos similares.
Qué significa esto para la tecnología inclusiva
Para un lector no especializado, el mensaje de Sign4all es claro: cuanto mejores y más equitativos sean los materiales de práctica que demos a nuestras máquinas, mejor entenderán a las personas que usan la lengua de signos. Al ofrecer miles de ejemplos de alta calidad y equilibrados de signos españoles cotidianos—junto con descripciones de movimiento listas para usar y particiones de entrenamiento estándar—este conjunto de datos sienta las bases para sistemas de reconocimiento de lengua de signos más fiables. Con el tiempo, herramientas así podrían apoyar subtitulado en tiempo real, servicios públicos más accesibles y una comunicación más fluida entre las comunidades sordas y oyentes, ayudando a que la tecnología digital escuche a las manos tanto como a las voces.
Cita: Morillas-Espejo, F., Martinez-Martin, E. Sign4all: a Spanish Sign Language dataset. Sci Data 13, 502 (2026). https://doi.org/10.1038/s41597-026-06872-6
Palabras clave: reconocimiento de lengua de signos, Lengua de Signos Española, conjuntos de datos de gestos, tecnología asistencial, aprendizaje automático