Clear Sky Science · ru
Sign4all: набор данных испанского жестового языка
Руки, которые говорят с машинами
Миллионы людей во всём мире полагаются на жестовые языки как на основной способ общения, но большинство современных приложений и устройств по‑прежнему «слышат» только устную речь. Чтобы сократить этот разрыв, компьютерам нужны большие, тщательно продуманные коллекции видеоматериалов с жестами, на которых они могли бы учиться. В этой статье представлен Sign4all — новый набор данных испанского жестового языка, созданный чтобы помочь будущим телефонам, ноутбукам и общественным устройствам справедливо и точно распознавать повседневные жесты.
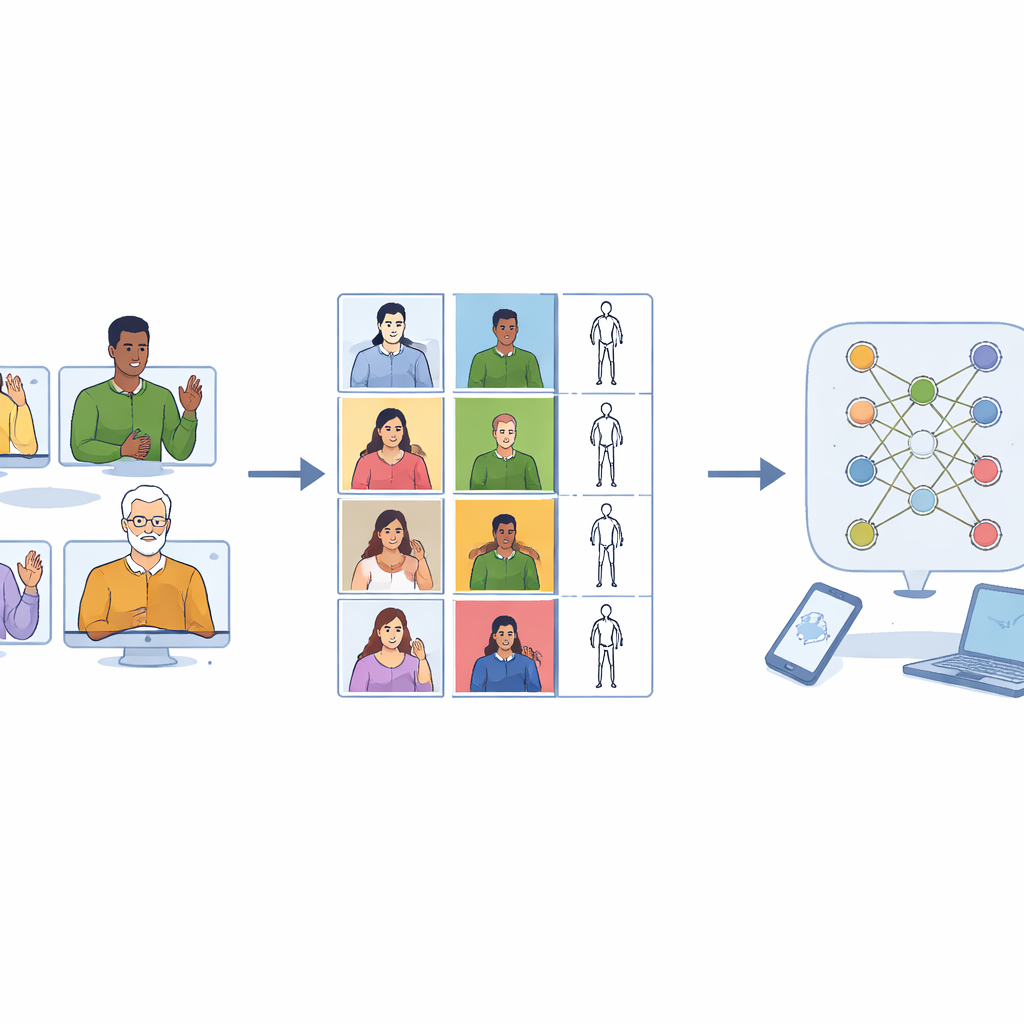
Почему нужны новые данные по жестовому языку
Голосовые помощники быстро прогрессировали потому, что их обучали на огромных аудиоколлекциях. У жестовых языков не было такой же эволюции. Существующие наборы данных часто пытаются охватить тысячи разных слов, но показывают каждое лишь несколько раз. Это затрудняет обучение компьютера тому, как один и тот же жест может немного отличаться у разных людей, в зависимости от одежды, скорости исполнения или угла съёмки. Многие коллекции также записывают только праворуких подающих жесты, хотя заметная часть населения использует левую руку или обе. В результате системы, обученные на таких данных, могут давать сбой при встрече с леворукими исполнителями или при небольших вариациях движения.
Узкая, но жизненная лексика
Вместо стремления к максимальной широте Sign4all придерживается подхода «мало, но глубоко». Авторы записали 24 распространённых знака испанского жестового языка, связанных с посещением заведения общественного питания и повседневными приёмами пищи: местоимения, такие как «я» и «ты», продукты питания — мясо, рыба, суп, столовые приборы — ложка и вилка, а также вопросительные слова «что», «где» и «когда». Для каждого знака в среднем подготовлено более 300 видеоклипов в высоком разрешении, что даёт алгоритмам обучения множество примеров того, как может варьироваться каждый жест. Лексика была выбрана так, чтобы знаки можно было комбинировать в короткие фразы, например «Мне не нравится мясо» или «У меня на завтрак мясо и яйца», что в будущем позволит исследовать распознавание простых предложений.
Создание баланса между левой и правой рукой
Ключевое проектное решение заключалось в том, чтобы одинаково учитывать леворукое и праворукое исполнение жестов. В лаборатории было записано восемь добровольцев (четыре женщины и четыре мужчины) с использованием качественной камеры. Каждый из них выполнял одноручные или асимметричные двуручные знаки как доминирующей, так и недоминантной рукой. Симметричные двуручные знаки записывались с дополнительными повторами, чтобы каждый класс знаков получил примерно одинаковое число клипов. После тщательной ручной нарезки итоговая коллекция включает 7 756 видео, почти в равных долях разделённых между леворукими и праворукими исполнениями. Такой баланс позволяет будущим системам распознавания научиться не обращать внимания на то, какая рука ведёт движение, а фокусироваться на самом паттерне жеста.
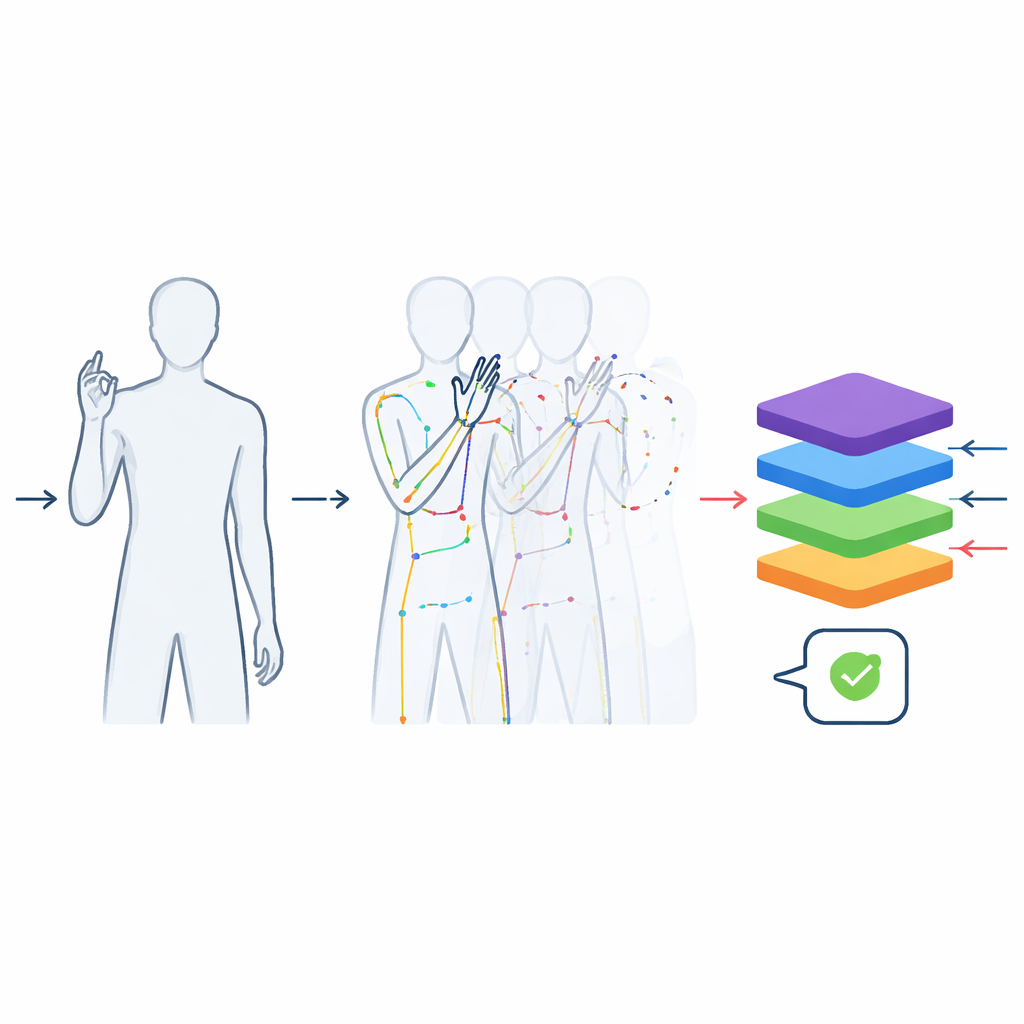
Преобразование богатых видео в чистые данные движения
Записи были обработаны так, чтобы быть максимально полезными для машинного обучения. Каждое видео было обрезано так, чтобы в нём оставался только сам знак, без переходов в позицию и из неё. Все клипы стандартизированы до 48 кадров — достаточно, чтобы захватить типичный жест, и чтобы модели не могли «жульничать», угадывая слово по длине клипа. Изображения были обрезаны вокруг исполнителя, чтобы убрать потолок и пол, при этом сохраняя естественную форму тела и избегая искажений, которые возникли бы при произвольном изменении размеров исходных прямоугольных кадров. Помимо цветных видео, команда использовала инструмент отслеживания позы для извлечения положений ключевых суставов верхней части тела и пальцев, строя компактное покадровое описание в виде «каркасной» (скелетной) модели. Эти скелеты сохранены в широко используемых научных форматах, чтобы их можно было подключить напрямую к современному ПО глубокого обучения.
Обучение компьютеров на вариациях, а не на совершенстве
Реальная среда далека от идеала: люди носят разную одежду, освещение меняется в течение дня, камеры слегка дрожат. Чтобы помочь системам справляться с такими вариациями, авторы создали дополнительные предварительно обработанные версии набора данных. Некоторые клипы зеркально отражены слева направо, имитируя противоположную руку; другие изменены небольшими корректировками яркости, цвета, размытия или поворота, без искажения смысла знака. Это увеличило общее число образцов до более чем 60 000. Тесты с видеобазированной моделью Transformer — современным типом нейросети — показали, что обучение на этих обогащённых данных значительно улучшает точность распознавания. Более простая модель, обученная только на данных скелетной кинематики, также достигла высокой точности, что доказывает: набор данных фиксирует ключевую информацию, необходимую для различения схожих знаков.
Что это значит для инклюзивных технологий
Для неспециалиста посыл Sign4all ясен: чем лучше и справедливее учебные материалы, которые мы даём нашим машинам, тем точнее они будут понимать людей, использующих жестовый язык. Предоставляя тысячи высококачественных, сбалансированных примеров повседневных испанских знаков — вместе с готовыми описаниями движения и стандартными разбиениями для обучения — этот набор данных закладывает основу для более надёжных систем распознавания жестового языка. Со временем такие инструменты могут поддерживать субтитрирование в реальном времени, делать общественные сервисы более доступными и облегчать общение между глухими и слышащими сообществами, помогая цифровым технологиям «слушать» руки так же, как и голоса.
Цитирование: Morillas-Espejo, F., Martinez-Martin, E. Sign4all: a Spanish Sign Language dataset. Sci Data 13, 502 (2026). https://doi.org/10.1038/s41597-026-06872-6
Ключевые слова: распознавание жестового языка, испанский жестовый язык, наборы данных жестов, ассистивные технологии, машинное обучение