Clear Sky Science · en
Sign4all: a Spanish Sign Language dataset
Hands that speak to machines
Millions of people around the world rely on sign languages as their main way to communicate, yet most of today’s apps and gadgets still “listen” only to spoken words. To bridge this gap, computers need large, carefully designed collections of sign language videos to learn from. This article presents Sign4all, a new Spanish Sign Language dataset built to help future phones, laptops and public devices understand everyday signs more fairly and accurately.
Why new data for sign language is needed
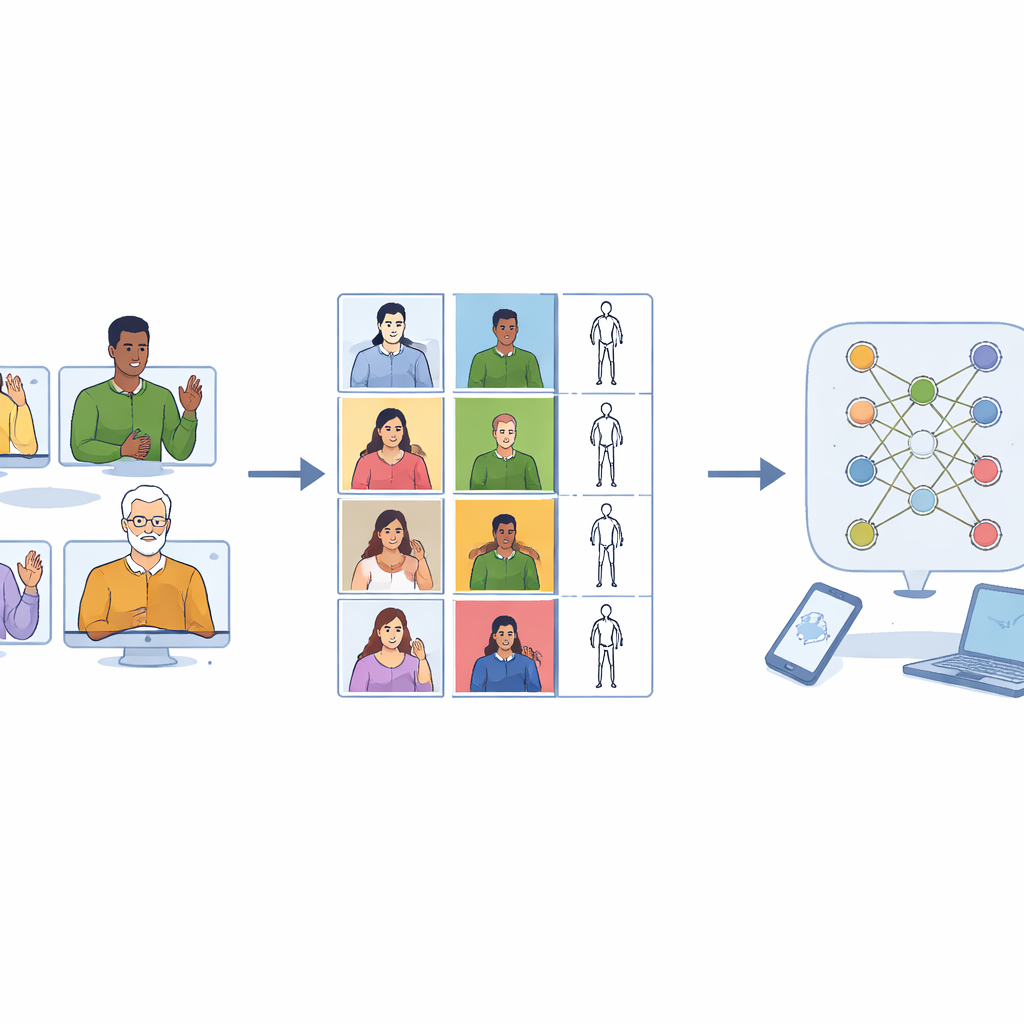
Voice assistants have improved quickly because they were trained on vast audio collections. Sign languages have not enjoyed the same progress. Existing sign datasets often try to cover thousands of different words but only show each one a handful of times. That makes it hard for a computer to learn how the same sign can look slightly different across people, clothing, speed or camera angle. Many collections also record only right-handed signers, even though a sizable share of the population signs with the left hand or uses both. As a result, systems trained on these data can fail when they encounter left-handed signers or subtle variations in movement.
A focused vocabulary from everyday life
Instead of aiming for sheer breadth, Sign4all takes a “small but deep” approach. The authors recorded 24 common Spanish Sign Language signs related to eating out and daily meals: pronouns such as “I” and “you,” food items like meat, fish and soup, utensils such as spoon and fork, and question words including “what,” “where” and “when.” For each sign, there are on average more than 300 high‑resolution video clips, giving learning algorithms many examples of how each gesture can vary. The vocabulary was also chosen so that signs can be combined into short sentences, such as “I do not like meat” or “I have meat and eggs for breakfast,” allowing researchers to explore simple phrase recognition in the future.
Building balance between left and right
A key design choice was to treat left‑handed and right‑handed signing as equally important. Eight volunteers (four women and four men) were recorded in a lab using a high‑quality camera. Every one of them performed each one‑handed or uneven two‑handed sign with both their dominant and non‑dominant hand. Symmetric two‑handed signs were recorded with extra repetitions so that each sign class ended up with roughly the same number of clips. After careful manual cutting, the final collection includes 7,756 videos, almost perfectly split between left‑handed and right‑handed performances. This balance lets future recognition systems learn to ignore which hand leads the movement and focus instead on the pattern itself.
Turning rich videos into clean motion data
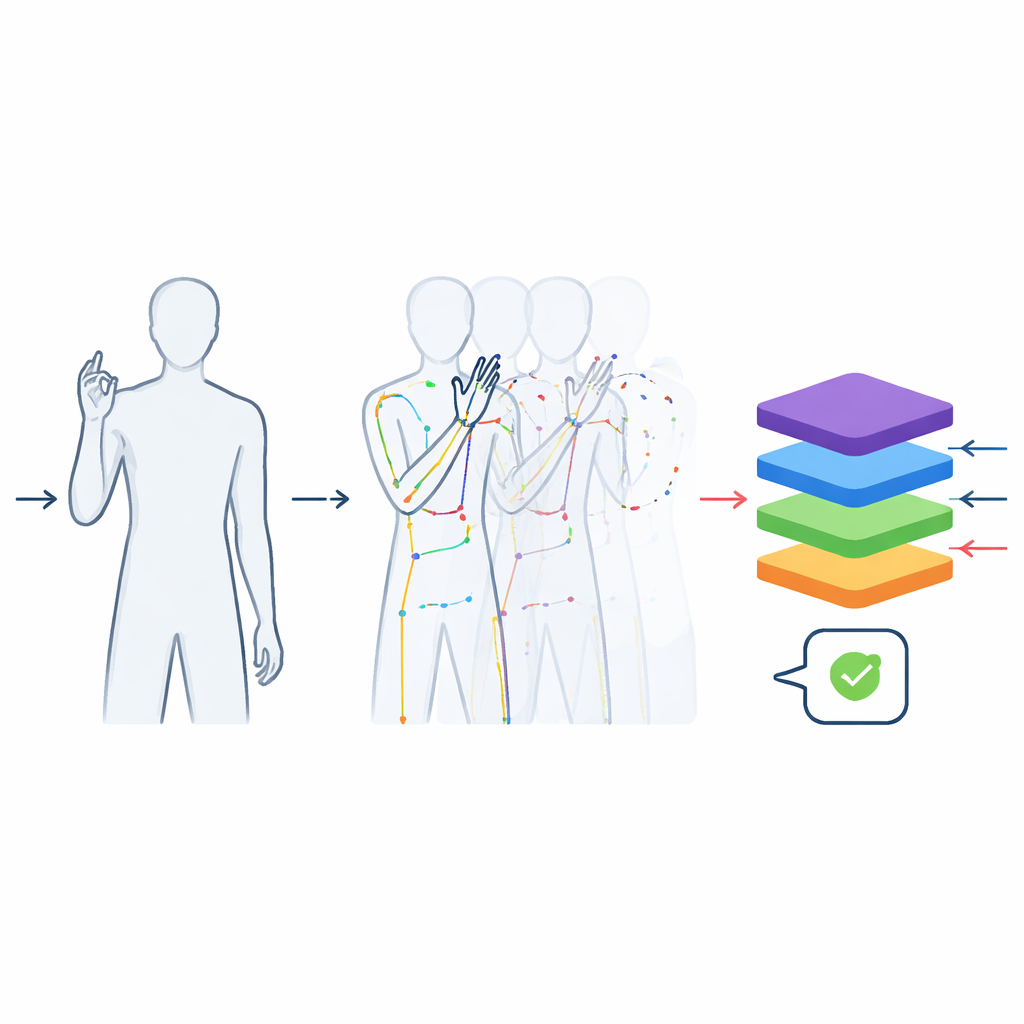
The recordings were processed to make them as useful as possible for machine learning. Each video was trimmed so that it contains only the actual sign, not the motion of moving into or out of position. All clips were standardized to 48 frames—long enough to capture a typical gesture—so that models cannot cheat by simply using clip length to guess the word. The images were cropped around the signer to remove ceiling and floor while preserving the natural body shape, avoiding distortions that would appear if raw rectangular footage were randomly resized. In addition to the color videos, the team used a pose‑tracking tool to extract the positions of key joints in the upper body and fingers, building a compact “stick‑figure” description frame by frame. These skeletons are stored in widely used scientific formats so they can be plugged straight into modern deep learning software.
Teaching computers with variation, not perfection
Real‑world environments are messy: people wear different clothes, lighting changes during the day, and cameras shake slightly. To help systems cope with such variation, the authors created extra, pre‑processed versions of the dataset. Some clips are flipped left‑to‑right to simulate the opposite hand; others are altered with small changes in brightness, color, blur or rotation, without harming the meaning of the sign. This boosted the total number of samples to more than 60,000. Tests with a video‑based Transformer model—a modern type of neural network—showed that training with these enriched data sharply improved recognition performance. A simpler model trained only on the skeletal motion data also reached high accuracy, proving that the dataset captures the essential information needed to tell similar signs apart.
What this means for inclusive technology
For a layperson, the message of Sign4all is straightforward: the better and fairer the practice material we give our machines, the better they will be at understanding people who sign. By offering thousands of high‑quality, balanced examples of everyday Spanish signs—along with ready‑to‑use motion descriptions and standard training splits—this dataset lays the groundwork for more reliable sign language recognition systems. In time, such tools could support real‑time captioning, more accessible public services and smoother communication between deaf and hearing communities, helping ensure that digital technology listens to hands as well as to voices.
Citation: Morillas-Espejo, F., Martinez-Martin, E. Sign4all: a Spanish Sign Language dataset. Sci Data 13, 502 (2026). https://doi.org/10.1038/s41597-026-06872-6
Keywords: sign language recognition, Spanish Sign Language, gesture datasets, assistive technology, machine learning