Clear Sky Science · de
Sign4all: ein Datensatz zur spanischen Gebärdensprache
Hände, die mit Maschinen sprechen
Millionen Menschen weltweit nutzen Gebärdensprachen als ihre Hauptkommunikationsform, doch die meisten heutigen Apps und Geräte „hören“ weiterhin nur auf gesprochene Worte. Damit diese Lücke geschlossen werden kann, benötigen Computer große, sorgfältig gestaltete Sammlungen von Gebärdensprachvideos, aus denen sie lernen können. Dieser Artikel stellt Sign4all vor, einen neuen Datensatz zur spanischen Gebärdensprache, der zukünftigen Telefonen, Laptops und öffentlichen Geräten helfen soll, alltägliche Gebärden gerechter und genauer zu verstehen.
Warum neue Daten für Gebärdensprachen nötig sind
Sprachassistenten haben sich schnell verbessert, weil sie auf riesigen Audiosammlungen trainiert wurden. Gebärdensprachen haben nicht denselben Fortschritt erlebt. Bestehende Gebärdensätzen versuchen oft, Tausende unterschiedlicher Wörter abzudecken, zeigen aber jedes davon nur wenige Male. Das erschwert es einem Computer, zu lernen, wie dieselbe Gebärde zwischen Personen, Kleidung, Tempo oder Kamerawinkel leicht variieren kann. Viele Sammlungen zeichnen zudem nur Rechtshänderinnen und Rechtshänder auf, obwohl ein beträchtlicher Teil der Bevölkerung mit der linken Hand oder mit beiden Händen gebärdet. Infolgedessen können Systeme, die auf solchen Daten trainiert wurden, versagen, wenn sie auf linkshändige Gebärdende oder subtile Bewegungsvariationen treffen.
Ein fokussierter Wortschatz aus dem Alltag
Statt auf bloße Breite zu setzen, verfolgt Sign4all einen „klein aber tief“‑Ansatz. Die Autorinnen und Autoren zeichneten 24 gebräuchliche Gebärden der spanischen Gebärdensprache auf, die sich auf Restaurantbesuche und tägliche Mahlzeiten beziehen: Pronomen wie „ich“ und „du“, Lebensmittel wie Fleisch, Fisch und Suppe, Besteck wie Löffel und Gabel sowie Fragewörter wie „was“, „wo“ und „wann“. Für jede Gebärde liegen im Mittel mehr als 300 hochauflösende Videoclips vor, sodass Lernalgorithmen viele Beispiele dafür erhalten, wie jede Geste variieren kann. Der Wortschatz wurde außerdem so gewählt, dass Gebärden zu kurzen Sätzen kombiniert werden können, etwa „Ich mag kein Fleisch“ oder „Zum Frühstück habe ich Fleisch und Eier“, sodass Forschende künftig einfache Satzerkennung untersuchen können.
Gleichgewicht zwischen links und rechts herstellen
Eine zentrale Designentscheidung war, linkshändiges und rechtshändiges Gebärden als gleich wichtig zu behandeln. Acht Freiwillige (vier Frauen und vier Männer) wurden im Labor mit einer hochwertigen Kamera aufgenommen. Jede Person führte jede einhändige oder ungleiche zweihändige Gebärde sowohl mit ihrer dominanten als auch mit ihrer nicht‑dominanten Hand aus. Symmetrische zweihändige Gebärden wurden mit zusätzlichen Wiederholungen aufgenommen, sodass jede Gebärdenklasse am Ende etwa dieselbe Anzahl von Clips aufwies. Nach sorgfältigem manuellen Zuschneiden umfasst die endgültige Sammlung 7.756 Videos, die nahezu gleichmäßig auf linkshändige und rechtshändige Darstellungen verteilt sind. Dieses Gleichgewicht ermöglicht es künftigen Erkennungssystemen, zu lernen, welche Hand die Bewegung anführt, zu ignorieren und sich stattdessen auf das Muster selbst zu konzentrieren.
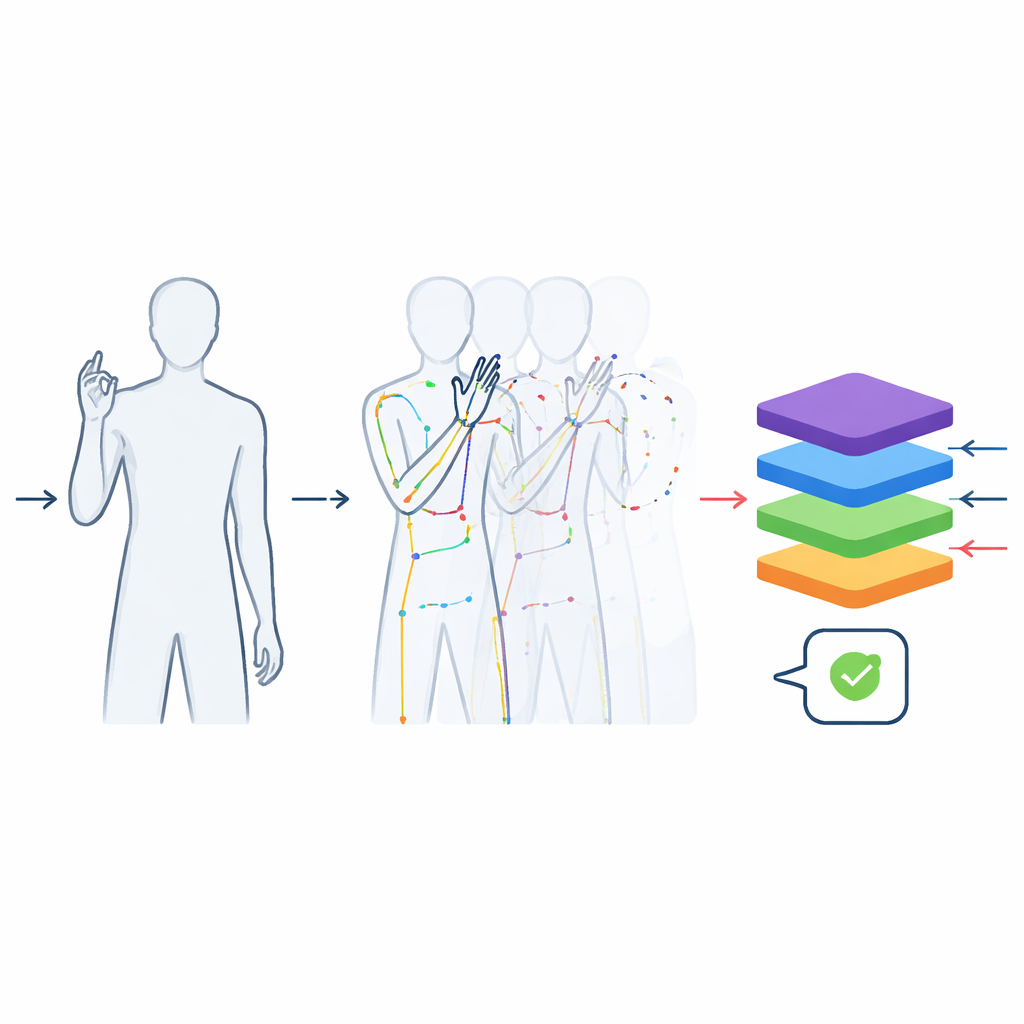
Reiche Videos in saubere Bewegungsdaten überführen
Die Aufnahmen wurden verarbeitet, um sie für maschinelles Lernen so nützlich wie möglich zu machen. Jedes Video wurde so gekürzt, dass es nur die eigentliche Gebärde enthält, nicht die Bewegung zum Einnehmen oder Verlassen der Position. Alle Clips wurden auf 48 Frames standardisiert — lang genug, um eine typische Geste zu erfassen — damit Modelle nicht einfach die Cliplänge nutzen können, um das Wort zu erraten. Die Bilder wurden um die gebärdende Person herum zugeschnitten, um Decke und Boden zu entfernen, während die natürliche Körperform erhalten blieb; so wurden Verzerrungen vermieden, die auftreten würden, wenn unbearbeitetes rechteckiges Material zufällig skaliert würde. Zusätzlich zu den Farbvideos nutzte das Team ein Pose‑Tracking‑Tool, um die Positionen wichtiger Gelenke im Oberkörper und der Finger zu extrahieren und so eine kompakte „Strichmännchen“‑Beschreibung Bild für Bild zu erstellen. Diese Skelette werden in weit verbreiteten wissenschaftlichen Formaten gespeichert, sodass sie direkt in moderne Deep‑Learning‑Software eingespeist werden können.
Computern Variation beibringen, nicht Perfektion
Realweltumgebungen sind unordentlich: Menschen tragen unterschiedliche Kleidung, das Licht ändert sich im Tagesverlauf und Kameras zittern leicht. Um Systeme im Umgang mit solcher Variation zu unterstützen, erstellten die Autorinnen und Autoren zusätzliche, vorverarbeitete Versionen des Datensatzes. Einige Clips wurden links‑rechts gespiegelt, um die gegenteilige Hand zu simulieren; andere wurden mit kleinen Veränderungen in Helligkeit, Farbe, Unschärfe oder Rotation modifiziert, ohne die Bedeutung der Gebärde zu beeinträchtigen. Das erhöhte die Gesamtzahl der Proben auf mehr als 60.000. Tests mit einem videobasierten Transformer‑Modell — einer modernen Art neuronaler Netze — zeigten, dass das Training mit diesen angereicherten Daten die Erkennungsleistung deutlich verbesserte. Ein einfacheres Modell, das nur auf den skelettalen Bewegungsdaten trainiert wurde, erreichte ebenfalls hohe Genauigkeit und bewies damit, dass der Datensatz die wesentlichen Informationen enthält, die nötig sind, um ähnliche Gebärden auseinanderzuhalten.
Was das für inklusive Technologie bedeutet
Für die allgemeine Öffentlichkeit ist die Botschaft von Sign4all klar: Je besser und gerechter das Übungsmaterial ist, das wir unseren Maschinen geben, desto besser werden sie Menschen, die gebärden, verstehen. Indem dieser Datensatz Tausende hochqualitativer, ausgewogener Beispiele alltäglicher spanischer Gebärden sowie einsatzbereite Bewegungsbeschreibungen und standardisierte Trainingsaufteilungen bietet, schafft er die Grundlage für zuverlässigere Systeme zur Gebärdenspracherkennung. Im Laufe der Zeit könnten solche Werkzeuge Echtzeit‑Untertitelung, zugänglichere öffentliche Dienste und reibungslosere Kommunikation zwischen Gehörlosen und Hörenden unterstützen und so dazu beitragen, dass digitale Technologie sowohl auf Hände als auch auf Stimmen hört.
Zitation: Morillas-Espejo, F., Martinez-Martin, E. Sign4all: a Spanish Sign Language dataset. Sci Data 13, 502 (2026). https://doi.org/10.1038/s41597-026-06872-6
Schlüsselwörter: Gebärdenspracherkennung, Spanische Gebärdensprache, Gestendatensätze, assistive Technologie, maschinelles Lernen