Clear Sky Science · nl
Sign4all: een dataset voor Spaanse gebarentaal
Handen die tegen machines spreken
Miljoenen mensen over de hele wereld gebruiken gebarentalen als hun primaire communicatiemiddel, maar de meeste apps en apparaten van nu "luisteren" nog steeds alleen naar gesproken woorden. Om die kloof te overbruggen, hebben computers grote, zorgvuldig samengestelde collecties met gebarenvideo’s nodig om van te leren. Dit artikel presenteert Sign4all, een nieuwe dataset voor Spaanse gebarentaal die is opgezet om toekomstige telefoons, laptops en openbare apparaten te helpen alledaagse gebaren eerlijker en nauwkeuriger te begrijpen.
Waarom nieuwe data voor gebarentaal nodig is
Spraakassistenten zijn snel verbeterd omdat ze zijn getraind op omvangrijke audioverzamelingen. Gebarentalen hebben niet van diezelfde vooruitgang geprofiteerd. Bestaande gebarendatasets proberen vaak duizenden verschillende woorden te bestrijken, maar tonen elk woord slechts een paar keer. Dat maakt het lastig voor een computer om te leren hoe hetzelfde gebaar er iets anders uit kan zien bij verschillende mensen, kleding, snelheid of camerahoek. Veel verzamelingen nemen ook alleen rechtshandige gebaarders op, terwijl een aanzienlijk deel van de bevolking linksgebarig is of beide handen gebruikt. Daardoor falen systemen die op deze data zijn getraind soms wanneer ze linksgebarigen of subtiele variaties in beweging tegenkomen.
Een geconcentreerd vocabulaire uit het dagelijks leven
In plaats van te mikken op louter omvang, kiest Sign4all voor een "klein maar diep" ontwerp. De auteurs namen 24 veelvoorkomende gebaren uit de Spaanse gebarentaal op die te maken hebben met uit eten gaan en dagelijkse maaltijden: voornaamwoorden zoals "ik" en "jij", voedingsmiddelen als vlees, vis en soep, gebruiksvoorwerpen zoals lepel en vork, en vraagwoorden waaronder "wat", "waar" en "wanneer." Voor elk gebaar zijn er gemiddeld meer dan 300 video-opnamen met hoge resolutie, waardoor leeralgoritmes veel voorbeelden hebben van hoe elk gebaar kan variëren. Het vocabulaire is ook zo gekozen dat gebaren gecombineerd kunnen worden tot korte zinnen, zoals "Ik hou niet van vlees" of "Ik heb vlees en eieren bij het ontbijt", zodat onderzoekers in de toekomst eenvoudige zinsherkenning kunnen verkennen.
Balans aanbrengen tussen links en rechts
Een belangrijke ontwerpkeuze was om links- en rechtshandig gebaren even zwaar mee te wegen. Acht vrijwilligers (vier vrouwen en vier mannen) werden in een lab vastgelegd met een hoogwaardige camera. Elk van hen voerde elk eenhands of oneven tweehandsgebaar zowel met hun dominante als met hun niet-dominante hand uit. Symmetrische tweehandsgebaren werden extra herhaald zodat elke gebaarklasse ongeveer hetzelfde aantal clips kreeg. Na zorgvuldige handmatige knipbeurten bevat de uiteindelijke collectie 7.756 video’s, bijna perfect verdeeld tussen linkshandige en rechtshandige uitvoeringen. Deze balans stelt toekomstige herkenningssystemen in staat te leren om te negeren welke hand de beweging leidt en zich in plaats daarvan op het patroon zelf te concentreren.
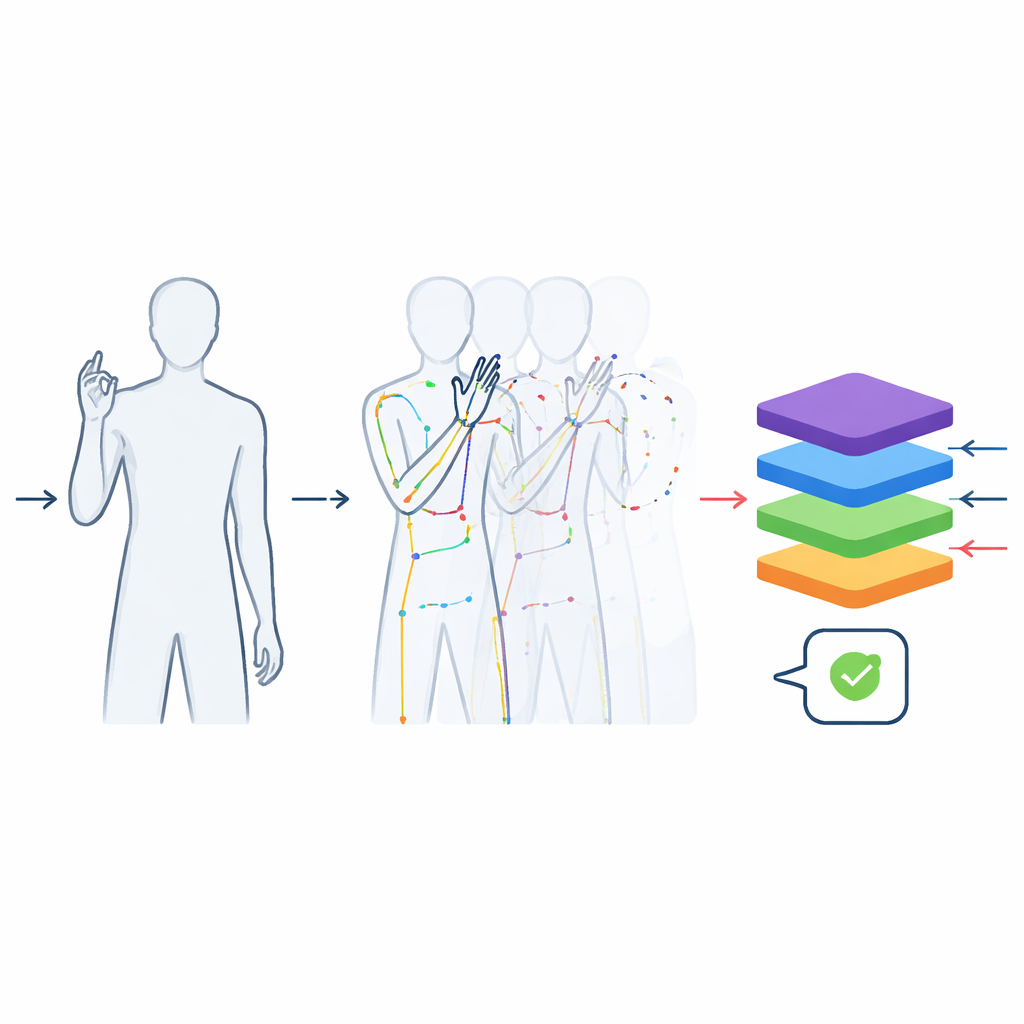
Rijke video’s omzetten in schone bewegingsdata
De opnamen zijn verwerkt om ze zo nuttig mogelijk te maken voor machine learning. Elke video is ingekort zodat alleen het werkelijke gebaar resteert, niet de beweging naar of van de startpositie. Alle clips zijn genormaliseerd tot 48 frames—lang genoeg om een typisch gebaar vast te leggen—zodat modellen niet valselijk het woord kunnen raden op basis van de duur van de clip. De beelden zijn bijgesneden rond de gebaarder om plafond en vloer te verwijderen, terwijl de natuurlijke lichaamsvorm behouden blijft, zodat vervormingen door willekeurige her-scaling van de rechthoekige opname worden vermeden. Naast de kleurvideo’s gebruikte het team een pose-tracking tool om de posities van belangrijke gewrichten in het bovenlichaam en de vingers te extraheren, en zo een compacte "stokfiguur"-beschrijving frame voor frame op te bouwen. Deze skeletdata worden opgeslagen in veelgebruikte wetenschappelijke formaten zodat ze direct in moderne deep learning-software kunnen worden gebruikt.
Computers leren met variatie, niet perfectie
Omgevingen in de echte wereld zijn rommelig: mensen dragen verschillende kleding, het licht verandert door de dag en camera’s trillen licht. Om systemen te helpen omgaan met zulke variatie, maakten de auteurs extra, voorbewerkte versies van de dataset. Sommige clips zijn horizontaal gespiegeld om de tegenovergestelde hand te simuleren; andere zijn aangepast met kleine veranderingen in helderheid, kleur, vervaging of rotatie, zonder de betekenis van het gebaar aan te tasten. Dit verhoogde het totale aantal voorbeelden tot meer dan 60.000. Tests met een video-gebaseerd Transformer-model—een moderne soort neuraal netwerk—toonden aan dat trainen met deze verrijkte data de herkenningsprestaties sterk verbeterde. Een eenvoudiger model dat alleen op de skeletbewegingen werd getraind behaalde ook hoge nauwkeurigheid, wat bewijst dat de dataset de essentiële informatie bevat om vergelijkbare gebaren uit elkaar te houden.
Wat dit betekent voor inclusieve technologie
Voor een leek is de boodschap van Sign4all duidelijk: hoe beter en eerlijker het oefenmateriaal dat we onze machines geven, hoe beter ze mensen die gebaren zullen begrijpen. Door duizenden voorbeelden van hoge kwaliteit en gebalanceerde alledaagse Spaanse gebaren aan te bieden—samen met kant-en-klare bewegingsbeschrijvingen en standaard trainingssplits—legt deze dataset de basis voor betrouwbaardere herkenningssystemen voor gebarentaal. Naar verloop van tijd zouden zulke hulpmiddelen realtime ondertiteling kunnen ondersteunen, openbare diensten toegankelijker maken en de communicatie tussen dove en horende gemeenschappen soepeler laten verlopen, en zo helpen ervoor te zorgen dat digitale technologie naar handen luistert net zo goed als naar stemmen.
Bronvermelding: Morillas-Espejo, F., Martinez-Martin, E. Sign4all: a Spanish Sign Language dataset. Sci Data 13, 502 (2026). https://doi.org/10.1038/s41597-026-06872-6
Trefwoorden: herkenning van gebarentaal, Spaanse gebarentaal, gebarendatasets, hulpmiddelen, machine learning