Clear Sky Science · pl
Sign4all: zbiór danych hiszpańskiego języka migowego
Ręce, które mówią do maszyn
Miliony ludzi na świecie polegają na językach migowych jako podstawowym sposobie komunikacji, tymczasem większość współczesnych aplikacji i urządzeń „słucha” wciąż tylko słów mówionych. Aby zmniejszyć tę przepaść, komputery potrzebują dużych, starannie zaprojektowanych kolekcji nagrań języka migowego, z których mogą się uczyć. W artykule przedstawiono Sign4all — nowy zbiór danych hiszpańskiego języka migowego stworzony po to, aby przyszłe telefony, laptopy i urządzenia publiczne lepiej i sprawiedliwiej rozumiały codzienne znaki.
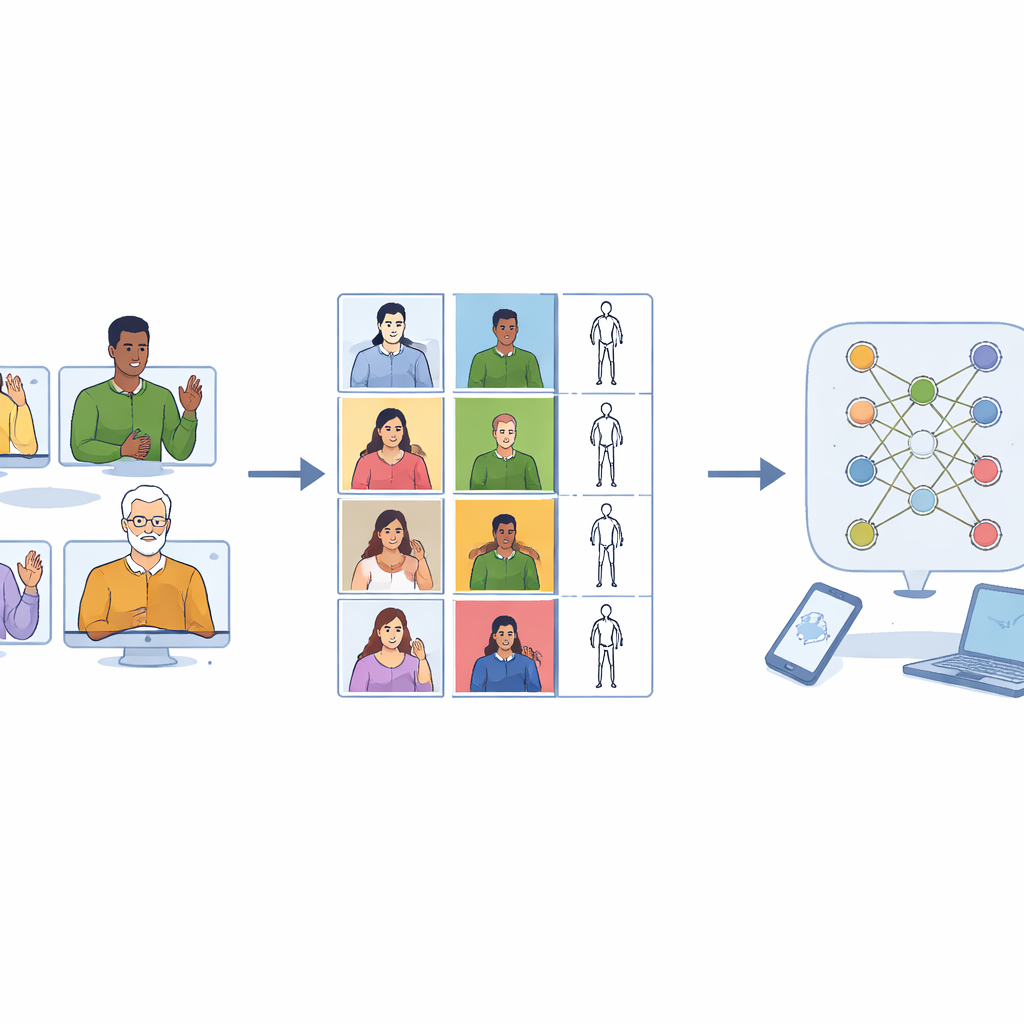
Dlaczego potrzebne są nowe dane dla języka migowego
Asystenci głosowi szybko się poprawili, ponieważ trenowano ich na ogromnych zbiorach nagrań dźwiękowych. Języki migowe nie odnotowały podobnego postępu. Istniejące zbiory często starają się objąć tysiące różnych słów, ale każde pojawia się tylko kilka razy. Utrudnia to komputerowi nauczenie się, jak ten sam znak może wyglądać nieco inaczej u różnych osób, w zależności od ubioru, tempa czy kąta kamery. Wiele kolekcji rejestruje też wyłącznie osoby posługujące się prawą ręką, mimo że znaczna część populacji używa lewej ręki lub obu rąk. W efekcie systemy trenowane na takich danych mogą zawodzić, gdy napotkają osoby leworęczne lub subtelne wariacje ruchu.
Skoncentrowane słownictwo z życia codziennego
Zamiast dążyć do samej rozległości, Sign4all przyjmuje podejście „mało, ale dogłębnie”. Autorzy nagrali 24 powszechne znaki hiszpańskiego języka migowego związane z jedzeniem poza domem i posiłkami: zaimki takie jak „ja” i „ty”, produkty spożywcze jak mięso, ryba i zupa, przybory takie jak łyżka i widelec oraz słowa pytające, w tym „co”, „gdzie” i „kiedy”. Dla każdego znaku dostępne jest średnio ponad 300 klipów w wysokiej rozdzielczości, co daje algorytmom wiele przykładów pokazujących, jak dany gest może się różnić. Słownictwo wybrano też tak, by znaki dało się łączyć w krótkie zdania, np. „Nie lubię mięsa” lub „Na śniadanie mam mięso i jajka”, co pozwoli badaczom w przyszłości badać rozpoznawanie prostych fraz.
Budowanie równowagi między lewą i prawą ręką
Kluczowym wyborem projektowym było potraktowanie migania lewą i prawą ręką jako równie istotnego. Osiem osób (cztery kobiety i czterech mężczyzn) zostało nagranych w laboratorium przy użyciu kamery wysokiej jakości. Każda z nich wykonała każdy jednoręczny lub asymetryczny dwuręczny znak zarówno ręką dominującą, jak i niedominującą. Symetryczne znaki dwuręczne nagrano z dodatkowymi powtórzeniami tak, by każda klasa znaków miała mniej więcej taką samą liczbę klipów. Po starannym ręcznym przycięciu, ostateczna kolekcja obejmuje 7 756 filmów, niemal równo podzielonych między wykonania lewo- i praworęczne. Taka równowaga pozwala przyszłym systemom rozpoznawania nauczyć się ignorować, która ręka inicjuje ruch, i skupić się na samym wzorcu.
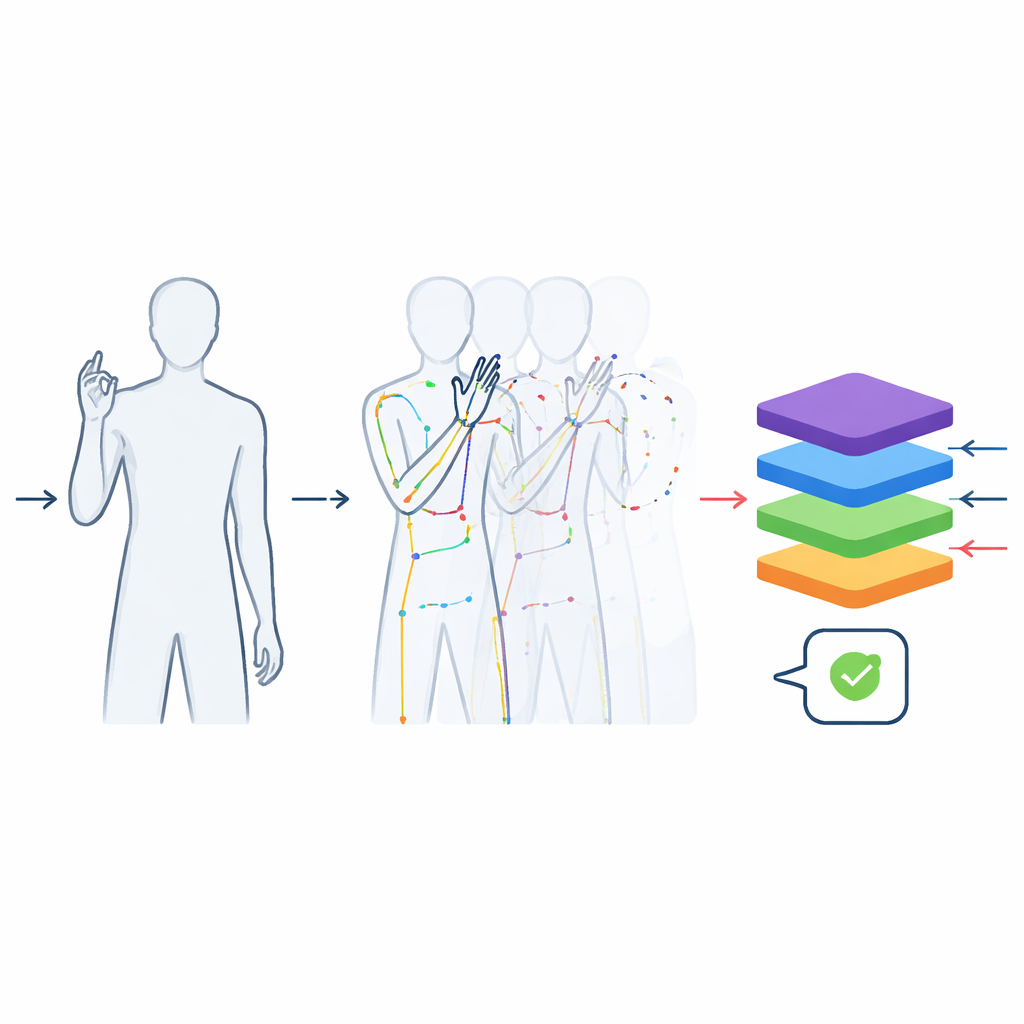
Przekształcanie bogatych nagrań w czyste dane ruchu
Nagrania przetworzono tak, by były jak najbardziej użyteczne dla uczenia maszynowego. Każdy film został przycięty tak, by zawierał jedynie właściwy znak, bez ruchu wchodzenia w pozycję lub wychodzenia z niej. Wszystkie klipy standaryzowano do 48 klatek — na tyle, aby uchwycić typowy gest — aby modele nie mogły oszukiwać, zgadując słowo na podstawie długości klipu. Obrazy wykadrowano wokół osoby pokazującej znak, usuwając sufit i podłogę, przy zachowaniu naturalnych proporcji ciała i unikając zniekształceń, które pojawiłyby się przy losowym skalowaniu surowego prostokątnego materiału. Oprócz kolorowych nagrań zespół użył narzędzia śledzącego pozę, by wydobyć pozycje kluczowych stawów górnej części ciała i palców, tworząc zwarte opisanie „patyczkowej” sylwetki klatka po klatce. Te szkielety zapisano w szeroko stosowanych formatach naukowych, tak aby można je było od razu podłączyć do nowoczesnego oprogramowania głębokiego uczenia.
Nauczanie komputerów przez wariację, nie perfekcję
Środowiska rzeczywiste są chaotyczne: ludzie noszą różne ubrania, oświetlenie zmienia się w ciągu dnia, a kamery nieznacznie się chwiej�ą. Aby pomóc systemom radzić sobie z takimi zmianami, autorzy stworzyli dodatkowe, wstępnie przetworzone wersje zbioru. Niektóre klipy odwrócono lewo–prawo, aby zasymulować przeciwną dłoń; inne zmodyfikowano poprzez niewielkie zmiany jasności, koloru, rozmycia lub rotacji, bez zmiany znaczenia znaku. Dzięki temu łączna liczba próbek wzrosła do ponad 60 000. Testy z użyciem modelu wideo typu Transformer — nowoczesnego rodzaju sieci neuronowej — wykazały, że trenowanie na tych wzbogaconych danych znacząco poprawiło skuteczność rozpoznawania. Prostszemu modelowi trenowanemu wyłącznie na danych ze szkieletem ruchu także udało się osiągnąć wysoką dokładność, co dowodzi, że zbiór uchwytuje istotne informacje potrzebne do rozróżniania podobnych znaków.
Co to oznacza dla inkluzywnej technologii
Dla laika przekaz Sign4all jest jasny: im lepsze i bardziej sprawiedliwe materiały treningowe damy naszym maszynom, tym lepiej będą rozumiały osoby migające. Dostarczając tysiące wysokiej jakości, zrównoważonych przykładów codziennych hiszpańskich znaków — wraz z gotowymi opisami ruchu i standardowymi podziałami treningowymi — ten zbiór danych tworzy podstawy pod bardziej niezawodne systemy rozpoznawania języka migowego. Z czasem takie narzędzia mogłyby wspierać napisy w czasie rzeczywistym, bardziej dostępne usługi publiczne i łatwiejszą komunikację między społecznościami głuchych i słyszących, pomagając zapewnić, że technologie cyfrowe słuchają rąk tak samo jak głosów.
Cytowanie: Morillas-Espejo, F., Martinez-Martin, E. Sign4all: a Spanish Sign Language dataset. Sci Data 13, 502 (2026). https://doi.org/10.1038/s41597-026-06872-6
Słowa kluczowe: rozpoznawanie języka migowego, hiszpański język migowy, zbiory gestów, technologie wspomagające, uczenie maszynowe