Clear Sky Science · it
Sign4all: un dataset della Lingua dei Segni spagnola
Mani che parlano alle macchine
Milioni di persone in tutto il mondo si affidano alle lingue dei segni come principale modalità di comunicazione, eppure la maggior parte delle app e dei dispositivi odierni “ascolta” ancora soltanto le parole pronunciate. Per colmare questo divario, i computer hanno bisogno di grandi raccolte di video di lingua dei segni progettate con cura da cui apprendere. Questo articolo presenta Sign4all, un nuovo dataset della Lingua dei Segni spagnola creato per aiutare futuri telefoni, laptop e dispositivi pubblici a comprendere i segni quotidiani in modo più equo e accurato.
Perché servono nuovi dati per la lingua dei segni
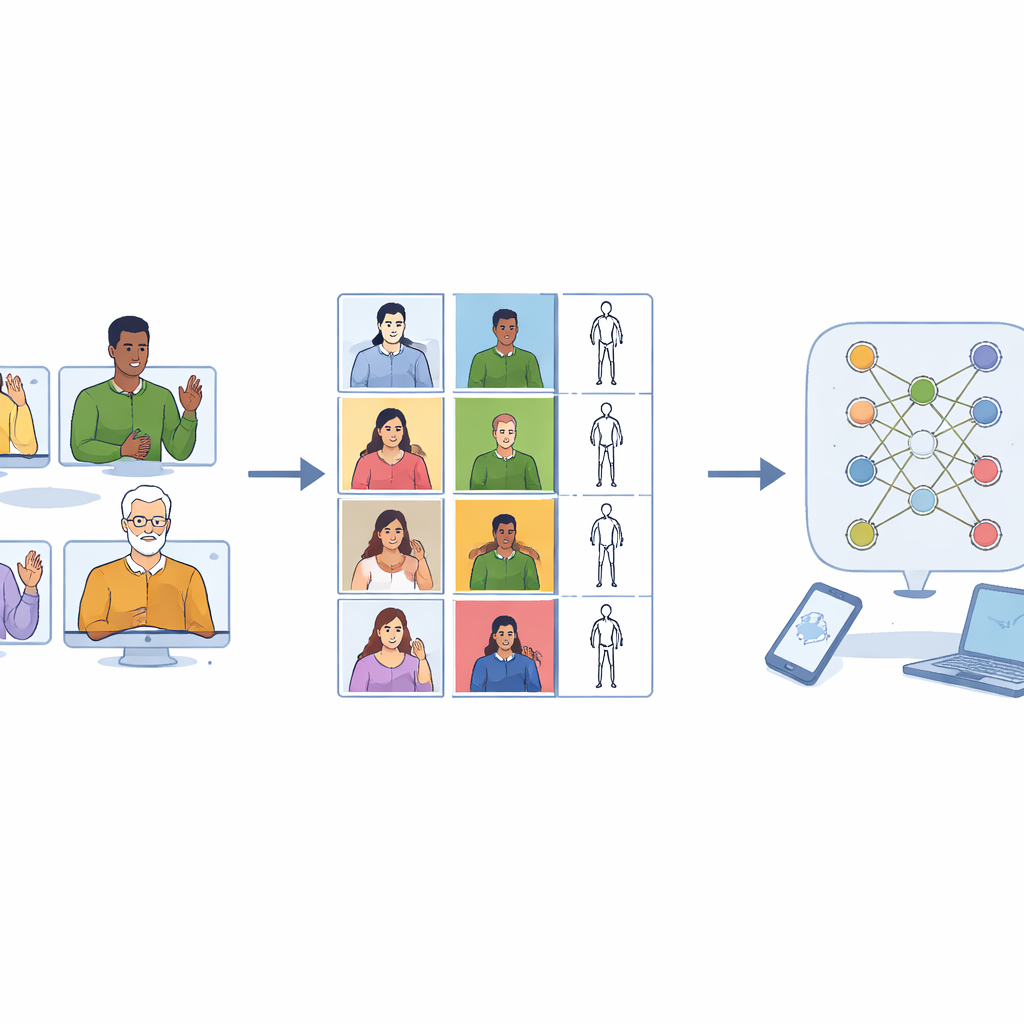
Gli assistenti vocali sono migliorati rapidamente perché sono stati addestrati su vaste raccolte audio. Le lingue dei segni non hanno goduto dello stesso progresso. I dataset esistenti spesso cercano di coprire migliaia di parole diverse ma mostrano ciascuna solo poche volte. Questo rende difficile per un computer imparare come lo stesso segno possa apparire leggermente diverso fra persone, abbigliamento, velocità o angolazione della telecamera. Molte raccolte registrano inoltre soltanto persone che segnano con la mano destra, nonostante una parte consistente della popolazione usi la mano sinistra o entrambe. Di conseguenza, i sistemi addestrati su questi dati possono fallire quando incontrano segnalanti mancini o variazioni sottili nel movimento.
Un vocabolario mirato dalla vita quotidiana
Invece di puntare alla massima ampiezza, Sign4all adotta un approccio “poco ma profondo”. Gli autori hanno registrato 24 segni comuni della Lingua dei Segni spagnola legati al mangiare fuori e ai pasti quotidiani: pronomi come “io” e “tu”, alimenti come carne, pesce e zuppa, utensili come cucchiaio e forchetta, e parole interrogative tra cui “che”, “dove” e “quando”. Per ogni segno sono disponibili in media più di 300 clip video ad alta risoluzione, fornendo agli algoritmi di apprendimento molti esempi di come ogni gesto possa variare. Il vocabolario è stato inoltre scelto in modo che i segni possano essere combinati in frasi brevi, come “non mi piace la carne” o “a colazione ho carne e uova”, permettendo ai ricercatori di esplorare in futuro il riconoscimento di semplici frasi.
Costruire un equilibrio fra sinistra e destra
Una scelta di progettazione chiave è stata trattare il segnalare con la mano sinistra e con la mano destra come ugualmente importanti. Otto volontari (quattro donne e quattro uomini) sono stati registrati in laboratorio con una videocamera di alta qualità. Ognuno di loro ha eseguito ogni segno monomanuale o asimmetrico bimanuale sia con la mano dominante sia con la non dominante. I segni bimanuali simmetrici sono stati registrati con ripetizioni extra in modo che ogni classe di segni avesse all’incirca lo stesso numero di clip. Dopo un accurato taglio manuale, la collezione finale include 7.756 video, quasi perfettamente divisi tra esecuzioni mancina e destra. Questo equilibrio permette ai futuri sistemi di riconoscimento di imparare a ignorare quale mano guida il movimento e concentrarsi invece sul modello stesso.
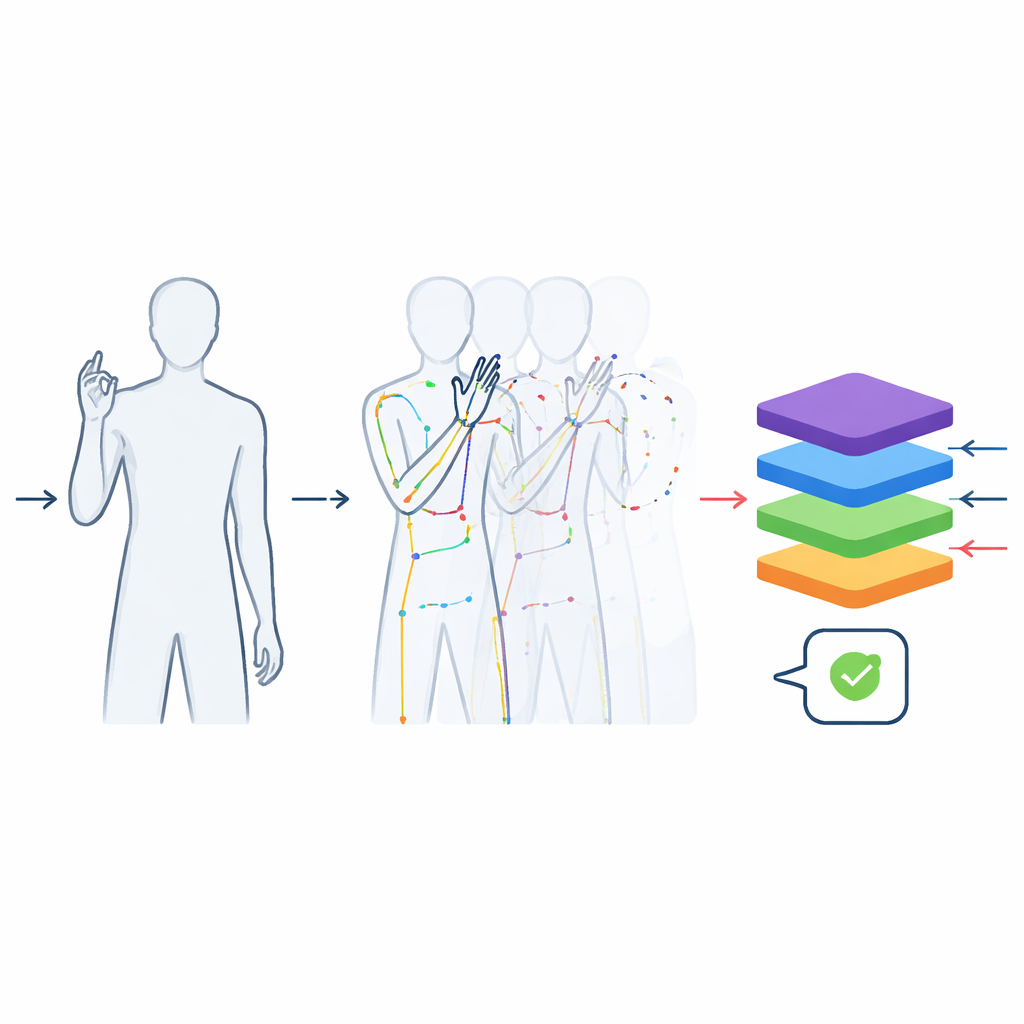
Trasformare video ricchi in dati di movimento puliti
Le registrazioni sono state elaborate per renderle il più utili possibile per l’apprendimento automatico. Ogni video è stato ritagliato in modo da contenere solo il segno effettivo, non il movimento di avvicinamento o allontanamento dalla posizione. Tutte le clip sono state standardizzate a 48 frame—sufficienti per catturare un gesto tipico—così che i modelli non possano barare usando semplicemente la durata della clip per indovinare la parola. Le immagini sono state ritagliate attorno alla persona che segnava per rimuovere soffitto e pavimento preservando la forma corporea naturale, evitando distorsioni che apparirebbero se il filmato rettangolare grezzo fosse ridimensionato a caso. Oltre ai video a colori, il team ha usato uno strumento di tracciamento della posa per estrarre le posizioni delle articolazioni chiave nella parte superiore del corpo e delle dita, costruendo una descrizione compatta “a bastoncino” fotogramma per fotogramma. Questi scheletri sono memorizzati in formati scientifici ampiamente utilizzati in modo che possano essere inseriti direttamente nel software di deep learning moderno.
Insegnare ai computer con la variazione, non con la perfezione
Gli ambienti reali sono disordinati: le persone indossano abiti diversi, l’illuminazione cambia durante il giorno e le fotocamere tremano leggermente. Per aiutare i sistemi a gestire tali variazioni, gli autori hanno creato versioni extra pre‑processate del dataset. Alcune clip sono state specchiate da sinistra a destra per simulare la mano opposta; altre sono state modificate con piccoli cambiamenti di luminosità, colore, sfocatura o rotazione, senza alterare il significato del segno. Questo ha aumentato il numero totale di campioni a oltre 60.000. Test con un modello Transformer basato su video—un tipo moderno di rete neurale—hanno mostrato che l’addestramento con questi dati arricchiti ha migliorato nettamente le prestazioni di riconoscimento. Un modello più semplice addestrato solo sui dati di movimento scheletrico ha raggiunto anch’esso alta accuratezza, dimostrando che il dataset cattura le informazioni essenziali necessarie per distinguere segni simili.
Cosa significa per una tecnologia inclusiva
Per un lettore non esperto, il messaggio di Sign4all è semplice: migliore e più equo è il materiale d’esercizio che forniamo alle nostre macchine, migliore sarà la loro capacità di comprendere chi segnala. Offrendo migliaia di esempi di alta qualità e bilanciati di segni spagnoli di uso quotidiano—insieme a descrizioni di movimento pronte all’uso e a suddivisioni standard per l’addestramento—questo dataset pone le basi per sistemi di riconoscimento della lingua dei segni più affidabili. Col tempo, tali strumenti potrebbero supportare sottotitolazione in tempo reale, servizi pubblici più accessibili e una comunicazione più fluida fra comunità sorde e udenti, contribuendo a garantire che la tecnologia digitale ascolti le mani tanto quanto le voci.
Citazione: Morillas-Espejo, F., Martinez-Martin, E. Sign4all: a Spanish Sign Language dataset. Sci Data 13, 502 (2026). https://doi.org/10.1038/s41597-026-06872-6
Parole chiave: riconoscimento della lingua dei segni, Lingua dei Segni spagnola, dataset di gesti, tecnologia assistiva, apprendimento automatico