Clear Sky Science · fr
Sign4all : un jeu de données de langue des signes espagnole
Mains qui parlent aux machines
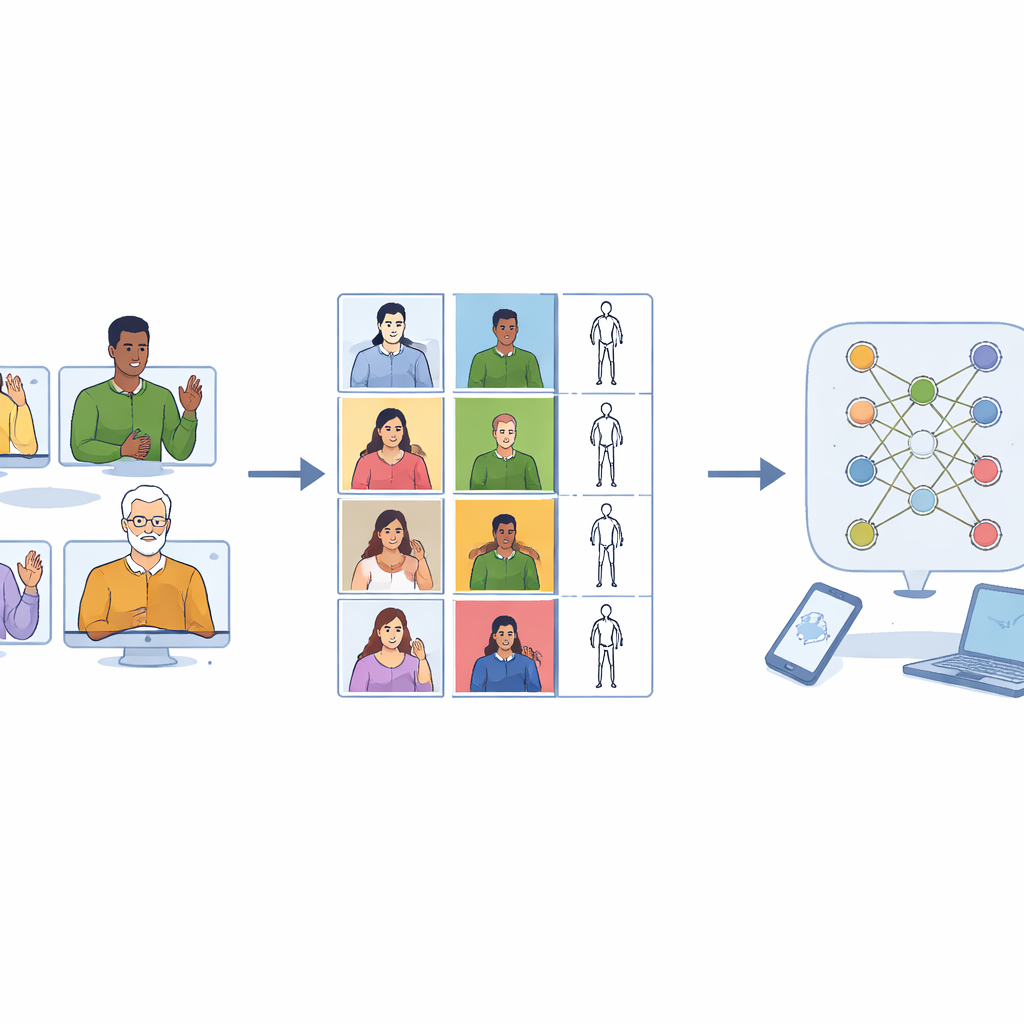
Des millions de personnes à travers le monde utilisent les langues des signes comme principal moyen de communication, et pourtant la plupart des applications et appareils actuels n’«entendent» que les paroles. Pour combler cet écart, les ordinateurs ont besoin de grandes collections de vidéos de langue des signes, conçues avec soin, à partir desquelles apprendre. Cet article présente Sign4all, un nouveau jeu de données de langue des signes espagnole conçu pour aider les futurs téléphones, ordinateurs portables et dispositifs publics à reconnaître les signes du quotidien de manière plus juste et plus précise.
Pourquoi de nouvelles données pour la langue des signes sont nécessaires
Les assistants vocaux se sont rapidement améliorés parce qu’ils ont été entraînés sur d’immenses collections audio. Les langues des signes n’ont pas bénéficié du même progrès. Les jeux de données existants essaient souvent de couvrir des milliers de mots différents mais ne montrent chaque mot que quelques fois. Cela rend difficile pour un algorithme d’apprendre comment un même signe peut varier légèrement selon la personne, les vêtements, la vitesse ou l’angle de la caméra. De nombreuses collections n’enregistrent aussi que des signants droitiers, alors qu’une part non négligeable de la population signe avec la main gauche ou utilise les deux mains. En conséquence, les systèmes entraînés sur ces données peuvent échouer face à des signants gauchers ou à des variations subtiles du mouvement.
Un vocabulaire ciblé issu de la vie quotidienne
Plutôt que de viser une simple amplitude, Sign4all adopte une approche «petit mais profond». Les auteurs ont enregistré 24 signes courants de la langue des signes espagnole liés à la restauration et aux repas quotidiens : des pronoms comme «je» et «tu», des aliments tels que viande, poisson et soupe, des ustensiles comme cuillère et fourchette, et des mots interrogatifs incluant «quoi», «où» et «quand». Pour chaque signe, il y a en moyenne plus de 300 clips vidéo en haute résolution, offrant aux algorithmes d’apprentissage de nombreux exemples des variations possibles de chaque geste. Le vocabulaire a aussi été choisi pour permettre la combinaison des signes en courtes phrases, comme «Je n’aime pas la viande» ou «J’ai de la viande et des œufs au petit‑déjeuner», permettant aux chercheurs d’explorer à l’avenir la reconnaissance de simples phrases.
Construire l’équilibre entre gauche et droite
Un choix de conception clé a été de traiter le signe gaucher et le signe droit comme également importants. Huit volontaires (quatre femmes et quatre hommes) ont été enregistrés en laboratoire à l’aide d’une caméra de haute qualité. Chacun d’eux a effectué chaque signe à une main ou chaque signe asymétrique à deux mains avec sa main dominante puis avec sa main non dominante. Les signes symétriques à deux mains ont été enregistrés avec des répétitions supplémentaires afin que chaque classe de signe comporte à peu près le même nombre de clips. Après un découpage manuel soigné, la collection finale comprend 7 756 vidéos, presque parfaitement réparties entre performances gauchères et droitières. Cet équilibre permet aux futurs systèmes de reconnaissance d’apprendre à ignorer quelle main guide le mouvement et de se concentrer sur le motif lui‑même.
Transformer des vidéos riches en données de mouvement propres
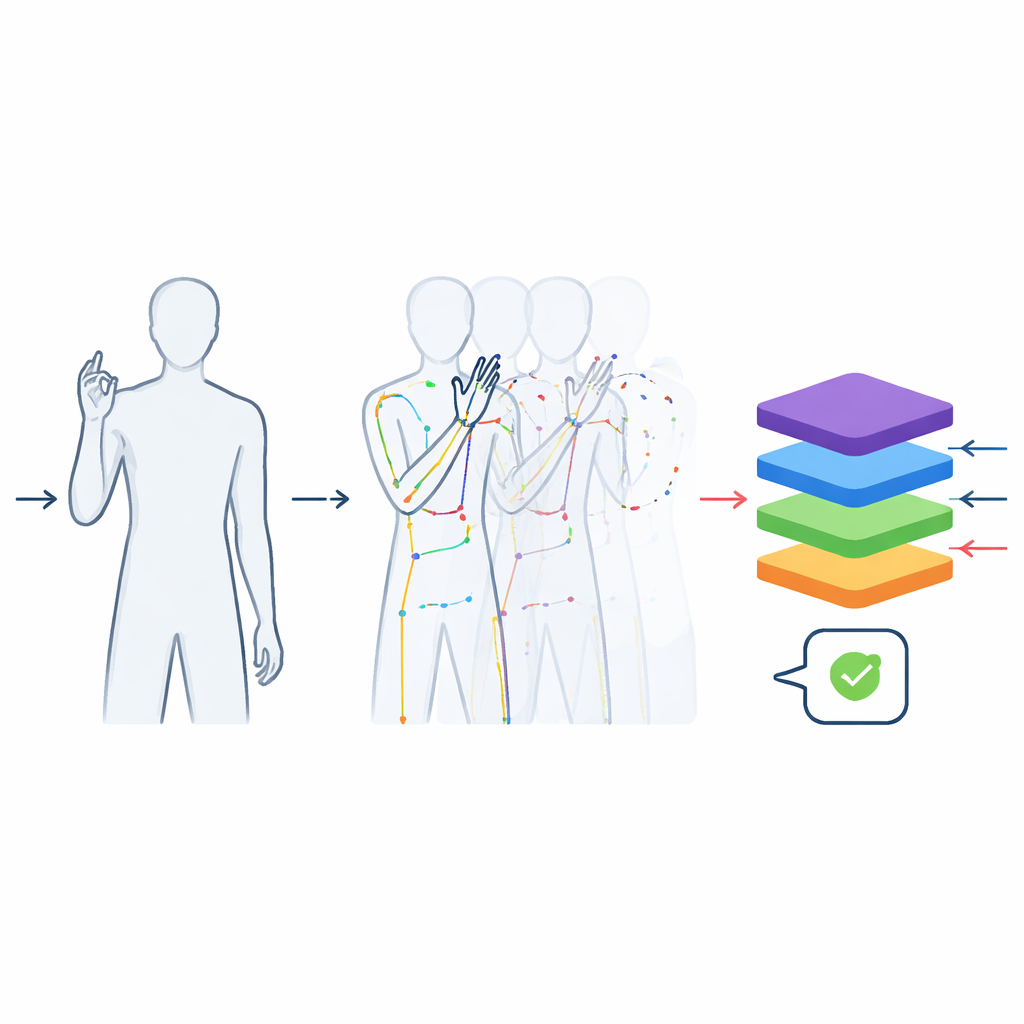
Les enregistrements ont été traités pour les rendre aussi utiles que possible pour l’apprentissage automatique. Chaque vidéo a été coupée pour ne contenir que le signe lui‑même, et non le déplacement pour se positionner ou sortir de la position. Tous les clips ont été standardisés à 48 images—suffisamment pour capturer un geste typique—pour empêcher les modèles de tricher en devinant le mot d’après la durée du clip. Les images ont été recadrées autour du signant afin de supprimer plafond et sol tout en préservant la silhouette naturelle du corps, évitant les déformations qui apparaîtraient si une prise rectangulaire brute était redimensionnée aléatoirement. Outre les vidéos en couleur, l’équipe a utilisé un outil de suivi de pose pour extraire les positions des articulations clés du haut du corps et des doigts, construisant une description compacte en «bonhomme‑allumette» image par image. Ces squelettes sont stockés dans des formats scientifiques largement utilisés afin qu’ils puissent être directement intégrés aux logiciels modernes d’apprentissage profond.
Apprendre aux ordinateurs avec la variation, pas la perfection
Le monde réel est désordonné : les gens portent des vêtements différents, l’éclairage change au cours de la journée et les caméras bougent légèrement. Pour aider les systèmes à faire face à de telles variations, les auteurs ont créé des versions supplémentaires prétraitées du jeu de données. Certains clips sont inversés gauche‑droite pour simuler la main opposée ; d’autres sont modifiés par de petits changements de luminosité, de couleur, de flou ou de rotation, sans altérer le sens du signe. Cela a porté le nombre total d’échantillons à plus de 60 000. Des tests avec un modèle Transformer basé sur la vidéo—un type moderne de réseau neuronal—ont montré que l’entraînement avec ces données enrichies améliorait nettement les performances de reconnaissance. Un modèle plus simple entraîné uniquement sur les données de mouvement squelettiques a également atteint une forte précision, prouvant que le jeu de données capture l’information essentielle nécessaire pour distinguer des signes similaires.
Ce que cela signifie pour une technologie inclusive
Pour le grand public, le message de Sign4all est simple : plus le matériel d’entraînement que nous fournissons à nos machines est bon et équitable, mieux elles comprendront les personnes qui signent. En offrant des milliers d’exemples quotidiens espagnols de haute qualité et équilibrés—ainsi que des descriptions de mouvement prêtes à l’emploi et des découpages d’entraînement standard—ce jeu de données jette les bases de systèmes de reconnaissance de la langue des signes plus fiables. Avec le temps, de tels outils pourraient soutenir la génération de sous‑titres en temps réel, rendre les services publics plus accessibles et fluidifier la communication entre sourds et entendants, contribuant à faire en sorte que la technologie numérique écoute autant les mains que les voix.
Citation: Morillas-Espejo, F., Martinez-Martin, E. Sign4all: a Spanish Sign Language dataset. Sci Data 13, 502 (2026). https://doi.org/10.1038/s41597-026-06872-6
Mots-clés: reconnaissance de la langue des signes, langue des signes espagnole, jeux de données de gestes, technologie d'assistance, apprentissage automatique