Clear Sky Science · sv
Genetisk diagnos av CYP21A2‑relaterad CAH: adaptiv sampling med långläsning är en exakt och skalbar lösning
Varför detta är viktigt för familjer och läkare
Många nyfödda screenas idag för medfödd binjurebarkshyperplasi (CAH), en hormonell rubbning som kan vara livshotande om den förbises. Att bekräfta diagnosen på DNA‑nivå är ändå förvånansvärt svårt, eftersom nyckelgenen ligger i ett förvillande område av vårt genom med en nästan identisk tvilling — en ”decoy”‑gen. Denna studie visar att en ny typ av DNA‑avläsning, kallad adaptiv sampling med långläsning, kan skära igenom den förvirringen och ge snabbare och mer tillförlitliga svar för patienter och deras familjer.
En hormonstörning med genetiska komplikationer
Medfödd binjurebarkshyperplasi (CAH) påverkar hur binjurarna producerar viktiga hormoner som reglerar saltbalans, stressreaktioner och könshormonnivåer. I ungefär 95 procent av fallen härstammar problemet från förändringar i en enda gen, CYP21A2, som hjälper till att bilda enzymet 21‑hydroxylas. Om det enzymet saknas eller är för svagt kan kroppen inte producera tillräckligt med kortisol och aldosteron, och istället överproduceras androgener, vilket leder till symtom som sträcker sig från saltbristskriser hos nyfödda till ökad kroppsbehåring och fertilitetsproblem senare i livet. De flesta patienter bär olika sjukdomsframkallande förändringar på vardera kopian av genen, och blandningen av dessa förändringar påverkar starkt hur allvarlig sjukdomen blir.
En gen som gömmer sig bredvid sin dubbelgångare
Den verkliga utmaningen är att CYP21A2 ligger i ett komplicerat kvarter på kromosom 6 intill en nästan identisk ”pseudogen”, CYP21A1P, som inte längre fungerar. Deras DNA‑kod är ungefär 98 procent lik, och regionen är benägen för omarrangemang där delar av den fungerande genen och pseudogenen byter plats, fusionerar eller raderats. Traditionella testmetoder bygger på att först amplifiera specifika DNA‑sträckor med PCR och sedan läsa dem med Sanger‑sekvensering, ibland kombinerat med en teknik kallad MLPA för att räkna genkopior. Dessa metoder är långsamma, arbetsintensiva och kan ha svårt att upptäcka stora omarrangemang eller att avgöra om flera förändringar sitter på samma kromosom eller på varsin — information som är avgörande för att förstå sjukdomsrisk för patienter och anhöriga.
Ett nytt sätt att läsa den besvärliga regionen
Forskarna utforskade en annan strategi med långläsningssekvensering på Oxford Nanopore‑plattformen. Istället för att hugga DNA i mycket korta fragment läser denna teknik betydligt längre sträckor, vilket hjälper till att koppla ihop avlägsna drag längs kromosomen. De använde ”adaptiv sampling”, där sekvenseraren styrs i realtid att fokusera på ett valt område — i detta fall kromosom 6 — och därmed öka täckningen utan komplicerade laboratoriesteg. Från 34 patienter med klinisk diagnos CAH sekvenserades DNA utan PCR, vilket undvek bias som kan få en version av genen att försvinna ur sikte. För att hantera den extrema likheten mellan CYP21A2 och dess pseudogen byggde teamet ett skräddarsytt mjukvaruverktyg kallat NanoCAH, som noggrant granskar hur varje lång DNA‑läsning alignerar, avgör om den faktiskt kommer från den fungerande genen eller från decoyen, och rekonstruerar varje patients två versioner av regionen.
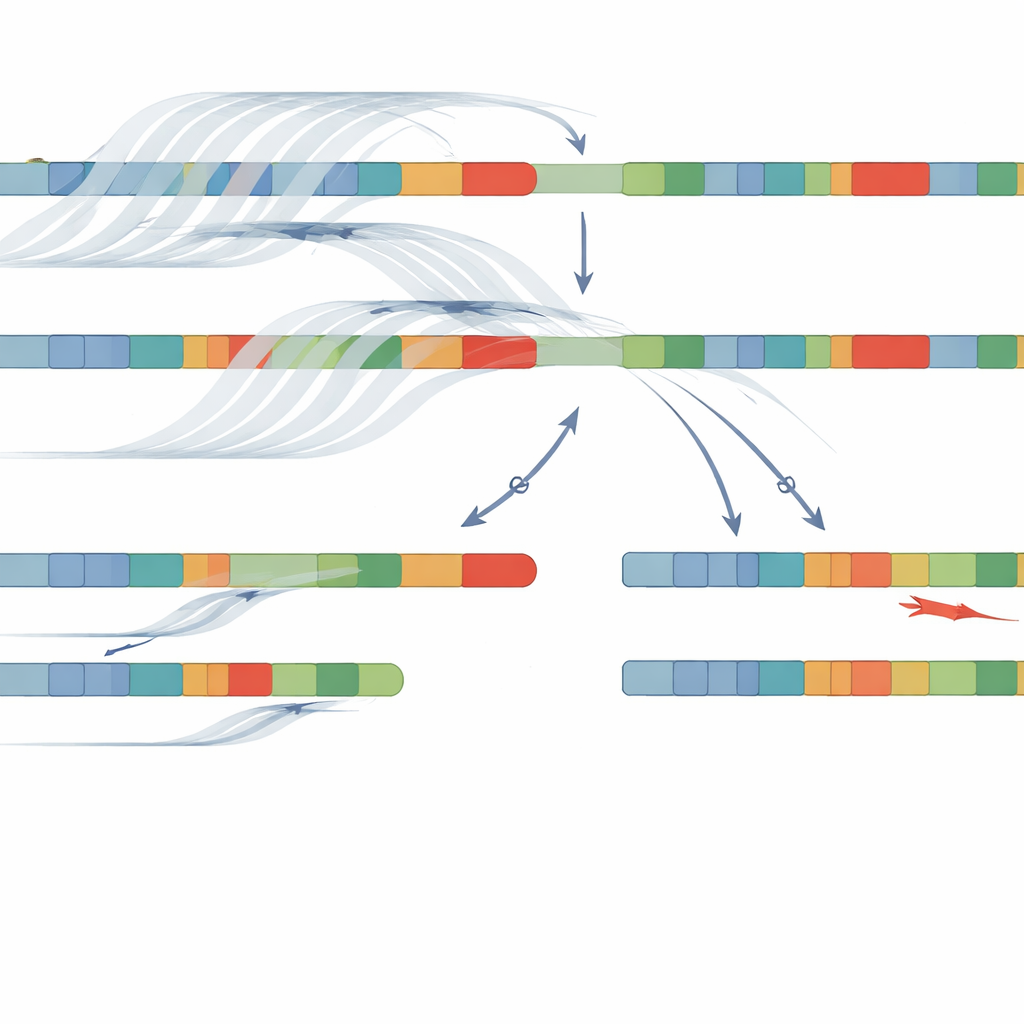
Tydligare svar hos de flesta patienter
Med denna kombination av adaptiv sampling långläsning och NanoCAH identifierade teamet sjukdomsframkallande DNA‑förändringar hos 32 av de 34 patienterna, en träffsäkerhet på 94 procent. De bekräftade inte bara nästan alla fynd från äldre metoder utan upptäckte också viktiga detaljer som tidigare hade missats eller felklassificerats. Hos vissa patienter hade tidigare tester kallat en förändring ”homozygot”, som om båda kromosomerna bar samma fel; den nya metoden visade att en kromosom faktiskt bar en deletion eller en komplex fusion mellan genen och pseudogenen. Hos andra identifierades tidigare osedda felstavningar i genen eftersom den nya metoden läser hela regionen i stället för en fast uppsättning vanliga hotspots. Avgörande var att de långa läsningarna gjorde det möjligt att ”fasa” varianter — visa vilka förändringar som sitter ihop på samma kromosom — utan att behöva DNA från föräldrar.
Vad detta innebär för framtida tester
Studien drar slutsatsen att adaptiv sampling med långläsningssekvensering i kombination med specialiserad analysmjukvara kan ge snabbare, mer skalbara och mer exakta genetiska diagnoser för CAH än dagens standardtester. Genom att ge en klarare bild av komplexa genomarrangemang och pålitligt skilja den riktiga genen från dess nästintill‑tvilling kan detta tillvägagångssätt förbättra diagnostik, vägleda behandlingsbeslut och stödja mer precisa bärarekontroller och prenatala tester i berörda familjer. Eftersom många andra sjukdomsrelaterade gener också ligger i invecklade, repetitiva delar av vårt DNA kan samma strategi hjälpa till att reda ut svåra genetiska frågor långt utöver CAH.
Citering: Lildballe, D.L., Huno, M.R., Ridder, L.O.R. et al. Genetic diagnosis of CYP21A2-related CAH: adaptive sampling long-read sequencing is an accurate and scalable solution. Eur J Hum Genet 34, 535–542 (2026). https://doi.org/10.1038/s41431-026-02019-8
Nyckelord: medfödd binjurebarkshyperplasi, CYP21A2, långläsningssekvensering, genetisk diagnos, adaptiv sampling