Clear Sky Science · nl
Genetische diagnose van CYP21A2-gerelateerde CAH: adaptive sampling long-read sequencing is een nauwkeurige en schaalbare oplossing
Waarom dit belangrijk is voor gezinnen en artsen
Veel pasgeborenen worden tegenwoordig bij de geboorte gescreend op aangeboren bijnierhyperplasie, een hormonale aandoening die levensbedreigend kan zijn als ze wordt gemist. Toch is het op DNA-niveau bevestigen van de diagnose verrassend lastig, omdat het sleutelgen zich bevindt in een verwarrend deel van ons genoom met een bijna identieke ‘‘tweeling’’-pseudogen. Deze studie toont aan dat een nieuw soort DNA-lezing, genaamd adaptive sampling long-read sequencing, die verwarring kan doorbreken en snellere en betrouwbaardere antwoorden kan geven voor patiënten en hun families.
Een hormonale aandoening met genetische wendingen
Aangeboren bijnierhyperplasie (CAH) beïnvloedt hoe de bijnieren vitale hormonen produceren die zoutbalans, stressreacties en geslachtshormoonniveaus regelen. In ongeveer 95 procent van de gevallen is het probleem terug te voeren op veranderingen in één gen, CYP21A2, dat helpt bij de productie van het enzym 21-hydroxylase. Als dat enzym ontbreekt of zwak is, kan het lichaam onvoldoende cortisol en aldosteron maken en produceert het in plaats daarvan te veel androgenen, wat leidt tot klachten variërend van zoutverliescrises bij pasgeborenen tot overmatige lichaamshaar en vruchtbaarheidsproblemen later in het leven. De meeste patiënten dragen verschillende ziekteveroorzakende veranderingen op elk exemplaar van het gen, en de combinatie van deze veranderingen bepaalt in sterke mate hoe ernstig hun ziekte zal zijn.
Een gen dat zich verstopt naast zijn dubbelganger
De echte uitdaging is dat CYP21A2 zich bevindt in een ingewikkelde omgeving op chromosoom 6 naast een bijna identiek ‘‘pseudogen’’, CYP21A1P, dat niet meer functioneert. Hun DNA-code is ongeveer 98 procent gelijk, en de regio is gevoelig voor herschikkingsgebeurtenissen waarbij stukken van het werkende gen en het pseudogen van plaats wisselen, samensmelten of verwijderd worden. Traditionele testmethoden vertrouwen op het versterken van specifieke DNA-stukken met PCR en het daarna uitlezen met Sanger-sequentieanalyse, soms gecombineerd met een techniek genaamd MLPA om genkopieën te tellen. Deze methoden zijn traag, arbeidsintensief en kunnen moeite hebben om grote herschikkingen te detecteren of om vast te stellen of meerdere veranderingen op hetzelfde chromosoom zitten of op tegenoverliggende exemplaren—informatie die cruciaal is voor het begrijpen van het ziekte risico bij patiënten en familieleden.
Een nieuwe manier om het lastige gebied te lezen
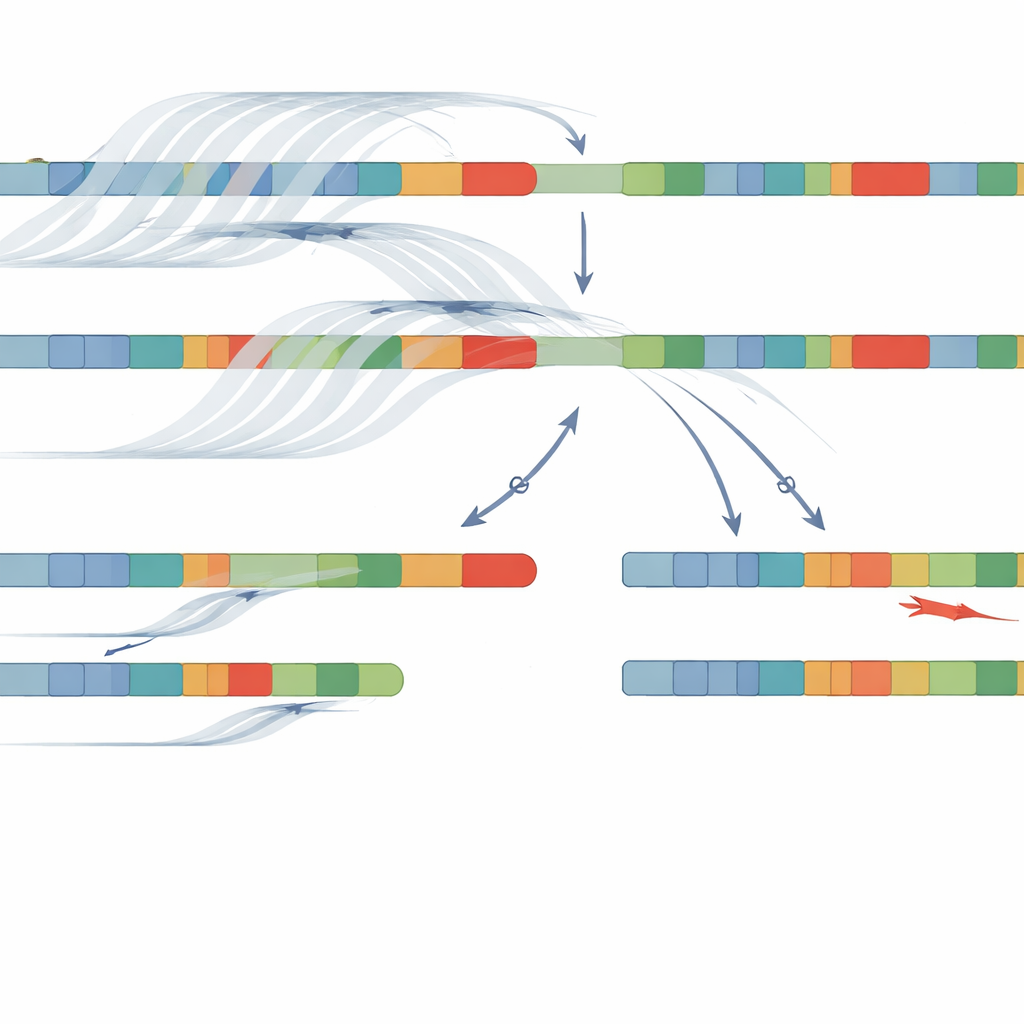
De onderzoekers onderzochten een andere strategie met long-read sequencing op het Oxford Nanopore-platform. In plaats van DNA in zeer korte fragmenten te knippen, leest deze technologie veel langere stukken, wat helpt om verafgelegen kenmerken langs het chromosoom te verbinden. Ze gebruikten ‘‘adaptive sampling’’, waarbij de sequentielezer in realtime wordt geïnstrueerd zich te concentreren op een gekozen regio—in dit geval chromosoom 6—waardoor de dekking toeneemt zonder complexe laboratoriumstappen. Van 34 patiënten met een klinische CAH-diagnose werd DNA gesequenced zonder PCR, waardoor biases die ervoor kunnen zorgen dat één versie van het gen uit beeld verdwijnt, werden vermeden. Om de extreme gelijkenis tussen CYP21A2 en het pseudogen aan te pakken, bouwde het team een aangepast softwarehulpmiddel genaamd NanoCAH, dat zorgvuldig onderzoekt hoe elke lange DNA-read uitlijnt, beslist of deze echt van het werkende gen of van de decoy afkomstig is, en de twee exemplaren van de regio van elke patiënt reconstrueert.
Heldere antwoorden bij de meeste patiënten
Met deze combinatie van adaptive sampling long-read sequencing en NanoCAH identificeerde het team ziekteveroorzakende DNA-veranderingen bij 32 van de 34 patiënten, een slagingspercentage van 94 procent. Ze bevestigden niet alleen vrijwel alle bevindingen van oudere methoden, maar ontdekten ook belangrijke details die waren gemist of verkeerd geclassificeerd. Bij sommige patiënten hadden eerdere tests een verandering als ‘‘homozygoot’’ aangemerkt, alsof beide chromosomen dezelfde fout droegen; de nieuwe methode toonde aan dat het ene chromosoom in werkelijkheid een deletie of een complexe fusie tussen het gen en het pseudogen droeg. Bij anderen werden eerder onopgemerkte spelfouten in het gen geïdentificeerd omdat de nieuwe benadering de hele regio leest in plaats van een vaste set veelvoorkomende hotspots. Cruciaal was dat de lange reads het team in staat stelden varianten te ‘‘fazen’’—aan te tonen welke veranderingen samen op hetzelfde chromosoom zitten—zonder DNA van ouders nodig te hebben.
Wat dit betekent voor toekomstige testen
De studie concludeert dat adaptive sampling long-read sequencing, gecombineerd met gespecialiseerde analysetools, snellere, beter schaalbare en nauwkeurigere genetische diagnoses voor CAH kan opleveren dan de huidige standaardtests. Door een duidelijker beeld te geven van complexe genherschikkingen en betrouwbaar het echte gen te onderscheiden van zijn bijna-tweeling, kan deze aanpak de diagnose verbeteren, behandelbeslissingen sturen en preciezere dragers- en prenatale testen ondersteunen in getroffen families. Omdat veel andere ziektegerelateerde genen zich ook bevinden in verwarde, repetitieve gedeelten van ons DNA, zou dezelfde strategie kunnen helpen bij het ontwarren van moeilijke genetische vragen ver buiten CAH.
Bronvermelding: Lildballe, D.L., Huno, M.R., Ridder, L.O.R. et al. Genetic diagnosis of CYP21A2-related CAH: adaptive sampling long-read sequencing is an accurate and scalable solution. Eur J Hum Genet 34, 535–542 (2026). https://doi.org/10.1038/s41431-026-02019-8
Trefwoorden: aangeboren bijnierhyperplasie, CYP21A2, long-read sequencing, genetische diagnose, adaptive sampling