Clear Sky Science · de
Genetische Diagnose von CYP21A2-assoziierter CAH: Adaptive Sampling Long-Read-Sequenzierung ist eine genaue und skalierbare Lösung
Warum das für Familien und Ärzte wichtig ist
Viele Neugeborene werden heute kurz nach der Geburt auf kongenitale Nebennierenhyperplasie (CAH) untersucht, eine hormonelle Störung, die lebensbedrohlich sein kann, wenn sie übersehen wird. Die Bestätigung der Diagnose auf DNA-Ebene ist jedoch überraschend schwierig, weil das entscheidende Gen in einem verwirrenden Abschnitt unseres Genoms liegt, neben einem nahezu identischen «Köder»-Gen. Diese Studie zeigt, dass eine neue Art des DNA-Lesens, genannt adaptive sampling Long-Read-Sequenzierung, diese Verwirrung durchdringen kann und schnellere sowie verlässlichere Antworten für Patienten und ihre Familien liefert.
Eine Hormonstörung mit genetischen Verwicklungen
Kongenitale Nebennierenhyperplasie (CAH) beeinflusst, wie die Nebennieren lebenswichtige Hormone produzieren, die Salzhaushalt, Stressreaktionen und Sexualhormonspiegel regulieren. Bei etwa 95 Prozent der Fälle liegt die Ursache in Veränderungen eines einzelnen Gens, CYP21A2, das an der Bildung des Enzyms 21‑Hydroxylase beteiligt ist. Fehlt dieses Enzym oder ist es geschwächt, kann der Körper nicht genügend Cortisol und Aldosteron produzieren und stellt stattdessen vermehrt Androgene her. Das führt zu Symptomen, die von Salzverlustkrisen bei Neugeborenen bis hin zu vermehrter Körperbehaarung und Fruchtbarkeitsproblemen im späteren Leben reichen. Die meisten Patienten tragen verschiedene krankheitsverursachende Veränderungen auf den beiden Genkopien, und die Kombination dieser Veränderungen beeinflusst stark, wie schwer die Erkrankung verläuft.
Ein Gen, das neben seinem Doppelgänger versteckt liegt
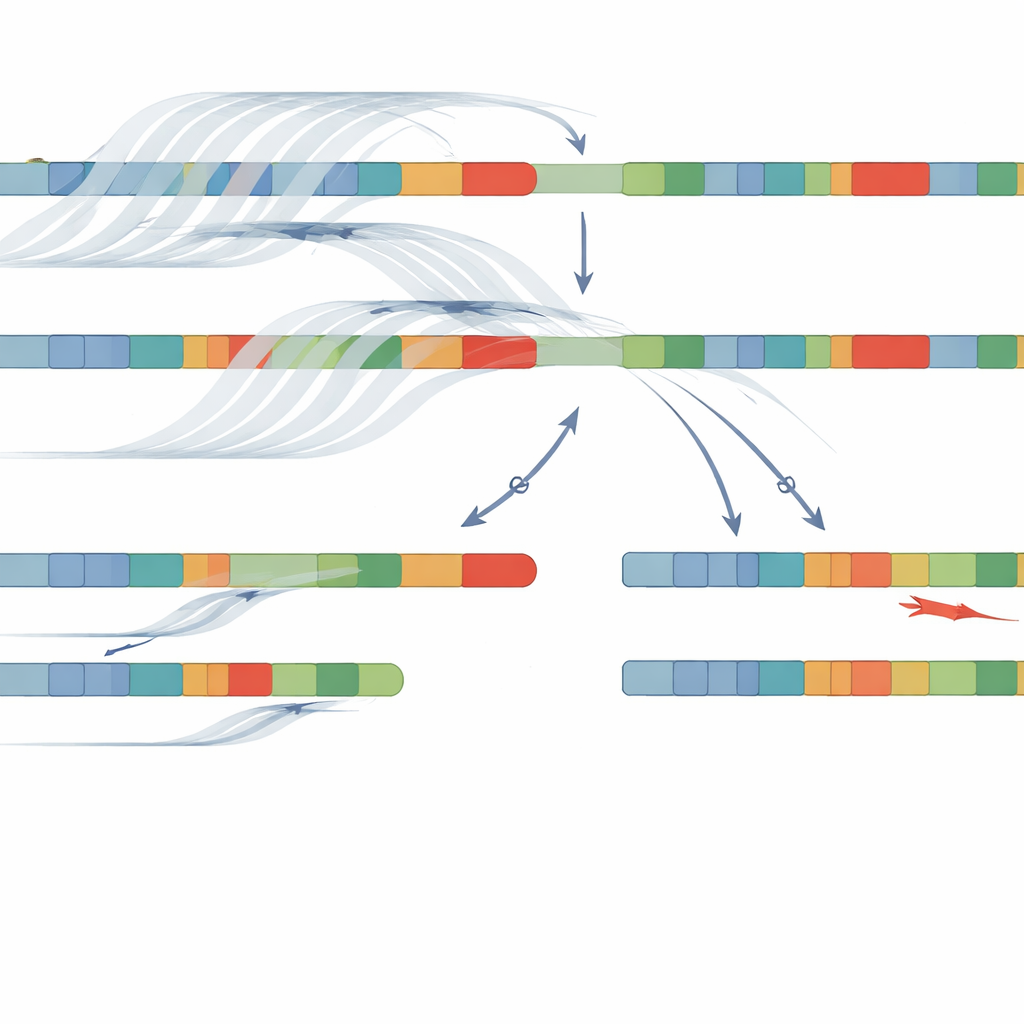
Die eigentliche Schwierigkeit besteht darin, dass CYP21A2 in einer komplizierten Nachbarschaft auf Chromosom 6 neben einem nahezu identischen «Pseudogen», CYP21A1P, liegt, das nicht mehr funktional ist. Ihr DNA-Code ist zu etwa 98 Prozent gleich, und die Region ist anfällig für Umstrukturierungen, bei denen Teile des funktionierenden Gens und des Pseudogens die Plätze tauschen, miteinander verschmelzen oder gelöscht werden. Traditionelle Testmethoden basieren auf der Amplifikation bestimmter DNA-Abschnitte mittels PCR und deren anschließender Bestimmung durch Sanger-Sequenzierung, oft kombiniert mit einer Technik namens MLPA zur Bestimmung der Genkopienzahl. Diese Methoden sind langsam, arbeitsintensiv und haben Schwierigkeiten, große Umlagerungen zu erkennen oder festzustellen, ob mehrere Veränderungen auf demselben Chromosom oder auf unterschiedlichen Chromosomen liegen — Informationen, die für das Verständnis des Erkrankungsrisikos bei Patienten und Verwandten entscheidend sind.
Eine neue Methode, die schwierige Region zu lesen
Die Forschenden verfolgten eine andere Strategie mit Long-Read-Sequenzierung auf der Oxford Nanopore-Plattform. Anstatt die DNA in sehr kurze Fragmente zu zerschneiden, liest diese Technologie deutlich längere Abschnitte, was hilft, entfernte Merkmale entlang des Chromosoms zu verbinden. Sie nutzten «adaptive sampling», bei dem der Sequencer in Echtzeit angewiesen wird, sich auf eine ausgewählte Region — in diesem Fall Chromosom 6 — zu konzentrieren und so die Abdeckung zu erhöhen, ohne komplexe Laborverfahren. Von 34 Patienten mit klinischer CAH-Diagnose wurde DNA ohne PCR sequenziert, wodurch Verzerrungen vermieden wurden, die dazu führen können, dass eine Genvariante aus dem Blickfeld verschwindet. Um mit der extremen Ähnlichkeit zwischen CYP21A2 und seinem Pseudogen umzugehen, entwickelte das Team ein kundenspezifisches Softwarewerkzeug namens NanoCAH, das sorgfältig untersucht, wie jede lange DNA-Lesung ausgerichtet wird, entscheidet, ob sie wirklich vom funktionalen Gen oder vom Doppelgänger stammt, und die beiden Genvarianten jedes Patienten rekonstruiert.
Klarere Antworten bei den meisten Patienten
Mit dieser Kombination aus adaptive sampling Long-Read-Sequenzierung und NanoCAH identifizierte das Team krankheitsverursachende DNA-Veränderungen bei 32 der 34 Patienten, eine Erfolgsrate von 94 Prozent. Sie bestätigten nicht nur nahezu alle Befunde älterer Methoden, sondern entdeckten auch wichtige Details, die zuvor übersehen oder falsch klassifiziert worden waren. Bei einigen Patienten hatten frühere Tests eine Veränderung als «homozygot» eingestuft, als hätten beide Chromosomen denselben Fehler; die neue Methode zeigte, dass auf einem Chromosom tatsächlich eine Deletion oder eine komplexe Fusion zwischen Gen und Pseudogen vorlag. Bei anderen wurden zuvor unentdeckte Fehlbasen im Gen aufgedeckt, weil der neue Ansatz die gesamte Region und nicht nur eine feste Auswahl häufiger Hotspots liest. Entscheidend war, dass die langen Reads dem Team erlaubten, Varianten zu phasieren — also zu zeigen, welche Veränderungen zusammen auf demselben Chromosom liegen — ohne DNA der Eltern zu benötigen.
Was das für zukünftige Tests bedeutet
Die Studie kommt zu dem Schluss, dass adaptive sampling Long-Read-Sequenzierung in Kombination mit spezialisierter Analysesoftware schnellere, skalierbarere und genauere genetische Diagnosen für CAH liefern kann als die derzeitigen Standardtests. Indem sie ein klareres Bild komplexer Genumlagerungen liefert und das echte Gen zuverlässig vom nahezu identischen Gegenstück trennt, kann dieser Ansatz die Diagnostik verbessern, Behandlungsentscheidungen leiten und präzisere Träger- sowie Pränataldiagnostik in betroffenen Familien unterstützen. Da viele andere krankheitsrelevante Gene ebenfalls in verstrickten, repetitiven Bereichen unserer DNA liegen, könnte dieselbe Strategie helfen, schwierige genetische Fragestellungen weit über CAH hinaus zu entwirren.
Zitation: Lildballe, D.L., Huno, M.R., Ridder, L.O.R. et al. Genetic diagnosis of CYP21A2-related CAH: adaptive sampling long-read sequencing is an accurate and scalable solution. Eur J Hum Genet 34, 535–542 (2026). https://doi.org/10.1038/s41431-026-02019-8
Schlüsselwörter: kongenitale Nebennierenhyperplasie, CYP21A2, Long-Read-Sequenzierung, genetische Diagnostik, adaptive sampling