Clear Sky Science · pl
Genetyczna diagnoza CAH związanej z CYP21A2: sekwencjonowanie długich odczytów z adaptacyjnym próbkowaniem jako dokładne i skalowalne rozwiązanie
Dlaczego to ma znaczenie dla rodzin i lekarzy
Wiele noworodków jest obecnie przesiewanych po urodzeniu pod kątem wrodzonej hiperplazji nadnerczy — zaburzenia hormonalnego, które może zagrażać życiu, jeśli zostanie przeoczone. Potwierdzenie diagnozy na poziomie DNA jest jednak zaskakująco trudne, ponieważ kluczowy gen leży w zagmatwanym fragmencie genomu obok niemal identycznej „przynęty” w postaci pseudogenu. Badanie to pokazuje, że nowy sposób odczytu DNA, zwany sekwencjonowaniem długich odczytów z adaptacyjnym próbkowaniem, potrafi przejść przez tę niejasność, dostarczając pacjentom i ich rodzinom szybszych i bardziej wiarygodnych odpowiedzi.
Zaburzenie hormonalne z genetycznymi zawiłościami
Wrodzona hiperplazja nadnerczy (CAH) wpływa na to, jak nadnercza wytwarzają niezbędne hormony kontrolujące równowagę soli, reakcje na stres i poziomy hormonów płciowych. W około 95 procentach przypadków problem wywodzi się ze zmian w jednym genie, CYP21A2, który bierze udział w tworzeniu enzymu 21‑hydroksylazy. Jeśli ten enzym jest nieobecny lub osłabiony, organizm nie może wyprodukować wystarczającej ilości kortyzolu i aldosteronu, a zamiast tego nadmiernie produkuje androgeny, co prowadzi do objawów od kryzysów związanych z utratą soli u noworodków po nadmierne owłosienie i problemy z płodnością w późniejszym życiu. Większość pacjentów nosi różne chorobotwórcze zmiany na każdej z kopii genu, a ich kombinacja silnie wpływa na nasilenie choroby.
Gen ukrywający się obok bliźniaka wyglądem
Prawdziwe wyzwanie polega na tym, że CYP21A2 znajduje się w skomplikowanym sąsiedztwie na chromosomie 6 obok niemal identycznego „pseudogenu”, CYP21A1P, który już nie funkcjonuje. Ich kod DNA jest w około 98 procentach taki sam, a region ten jest podatny na zdarzenia przebudowy, w których fragmenty genu czynnego i pseudogenu zamieniają się miejscami, łączą lub ulegają delecji. Tradycyjne metody testowania opierają się na amplifikacji konkretnych odcinków DNA metodą PCR, a następnie odczytywaniu ich techniką Sangera, czasami w połączeniu z metodą MLPA do zliczania kopii genu. Metody te są powolne, pracochłonne i mogą mieć trudności z wykryciem dużych przebudów lub ustaleniem, czy wiele zmian znajduje się na tej samej chromatydzie czy na przeciwległych — informacji kluczowej dla oceny ryzyka choroby u pacjentów i krewnych.
Nowy sposób czytania trudnego obszaru
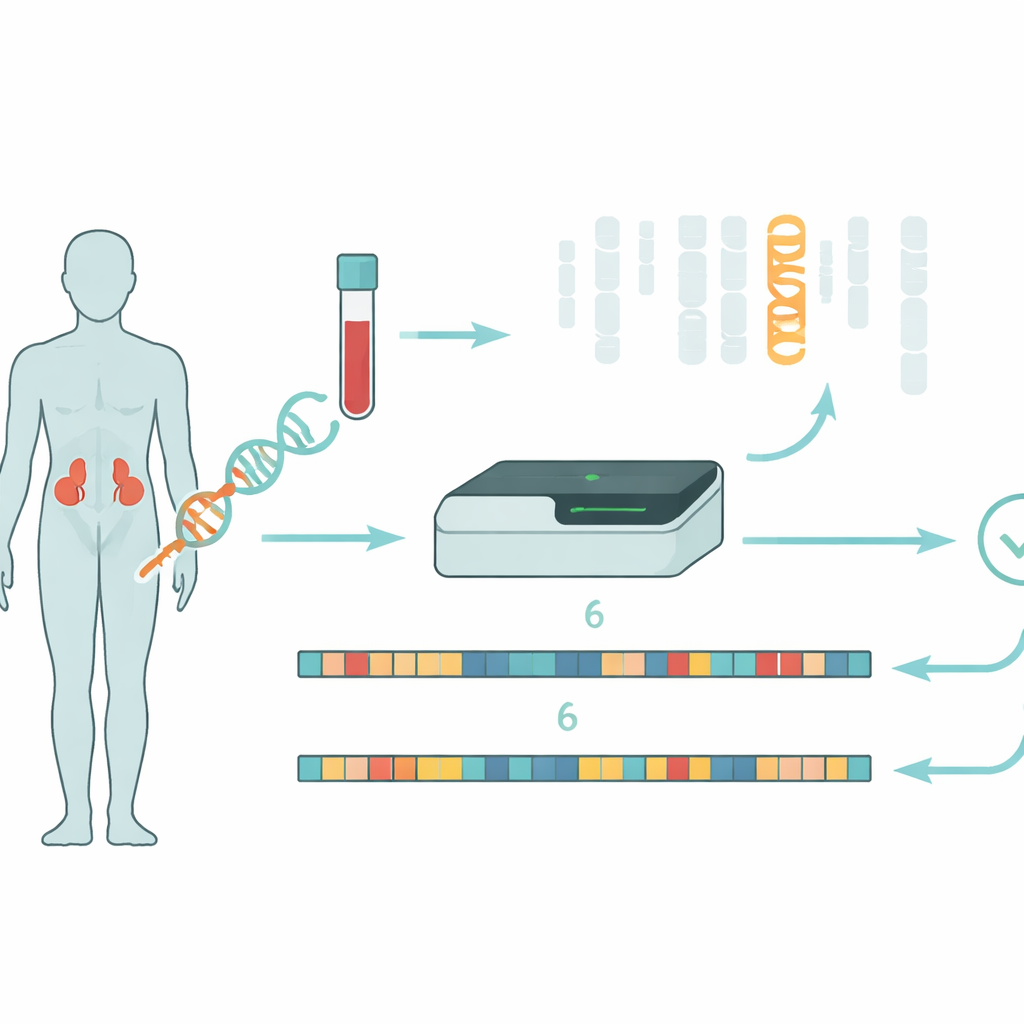
Naukowcy zastosowali inną strategię, wykorzystując sekwencjonowanie długich odczytów na platformie Oxford Nanopore. Zamiast rozdrabniać DNA na bardzo krótkie fragmenty, ta technologia odczytuje znacznie dłuższe odcinki, co pomaga łączyć odległe cechy wzdłuż chromosomu. Zastosowali „adaptacyjne próbkowanie”, w którym sekwencer w czasie rzeczywistym jest kierowany do fokusowania się na wybranym regionie — w tym wypadku na chromosomie 6 — zwiększając pokrycie bez skomplikowanych kroków laboratoryjnych. Z 34 pacjentów z kliniczną diagnozą CAH pobrano DNA i zsekwencjonowano je bez użycia PCR, unikając zniekształceń, które mogą powodować „znikanie” jednej wersji genu z pola widzenia. Aby poradzić sobie z ogromnym podobieństwem między CYP21A2 a jego pseudogenem, zespół opracował niestandardowe narzędzie programowe o nazwie NanoCAH, które dokładnie analizuje wyrównania każdego długiego odczytu DNA, decyduje, czy pochodzi on rzeczywiście z genu czynnego czy z przynęty, i rekonstruuje dwie kopie badanego regionu u każdego pacjenta.
Bardziej jednoznaczne odpowiedzi u większości pacjentów
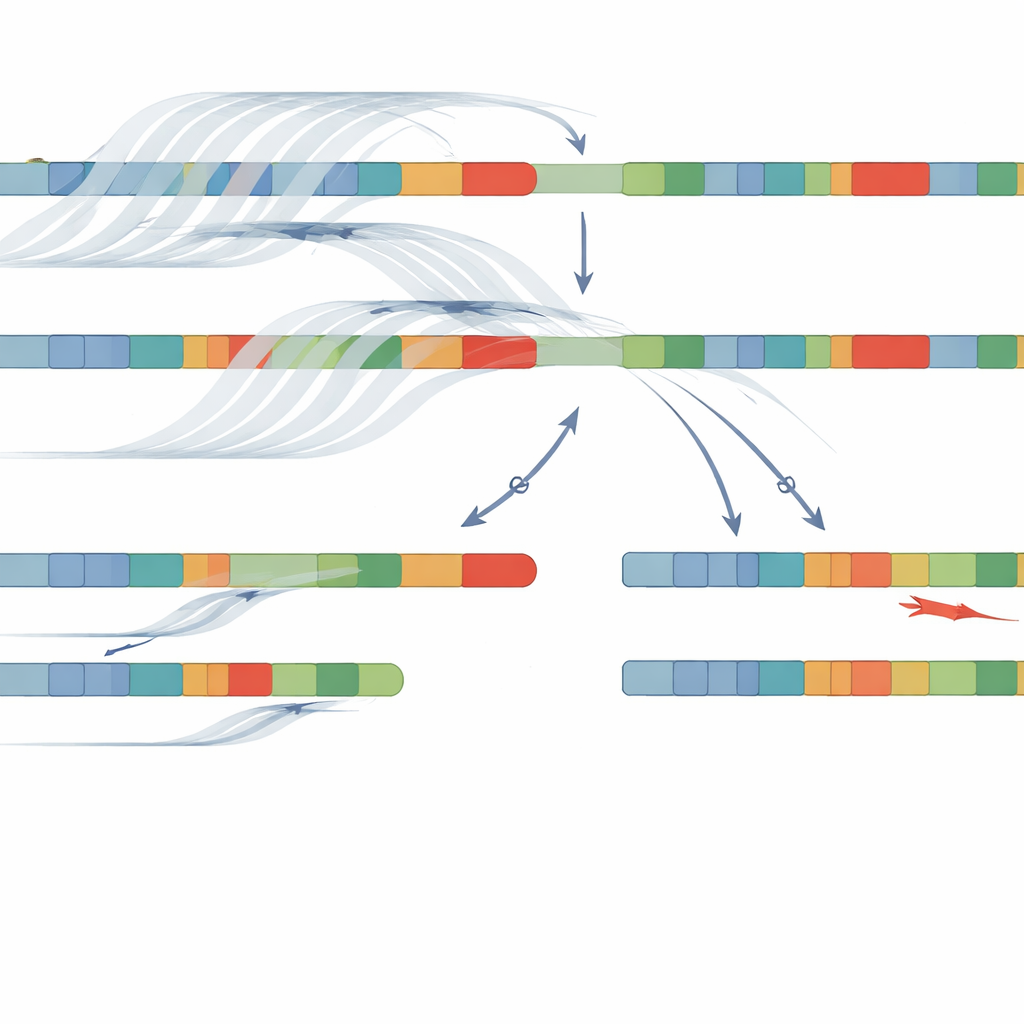
Wykorzystując połączenie sekwencjonowania długich odczytów z adaptacyjnym próbkowaniem i narzędzia NanoCAH, zespół zidentyfikował chorobotwórcze zmiany DNA u 32 z 34 pacjentów, co daje 94‑procentową skuteczność. Nie tylko potwierdzili niemal wszystkie wyniki uzyskane starszymi metodami, ale też odkryli istotne szczegóły, które wcześniej zostały pominięte lub błędnie sklasyfikowane. U niektórych pacjentów wcześniejsze testy uznały zmianę za „homozygotyczną”, jakby obie kopie chromosomu miały ten sam błąd; nowa metoda wykazała, że na jednym chromosomie znajduje się w rzeczywistości delecja lub złożona fuzja między genem a pseudogenem. U innych wykryto wcześniej niewidoczne błędy zapisu (missequence) w genie, ponieważ nowe podejście czyta cały region zamiast ograniczać się do zestawu typowych hotspotów. Kluczowe jest to, że długie odczyty umożliwiły zafazowanie wariantów — pokazanie, które zmiany występują razem na tej samej chromatydzie — bez konieczności korzystania z DNA rodziców.
Co to oznacza dla przyszłych badań diagnostycznych
Badanie konkluduje, że sekwencjonowanie długich odczytów z adaptacyjnym próbkowaniem, w parze ze specjalistycznym oprogramowaniem analitycznym, może dostarczać szybszych, bardziej skalowalnych i dokładniejszych diagnoz genetycznych dla CAH niż obecne standardowe testy. Dzięki jaśniejszemu obrazowi złożonych przebudów genów i niezawodnemu rozróżnieniu prawdziwego genu od jego niemal bliźniaka, podejście to może polepszyć diagnozę, wspomóc decyzje terapeutyczne oraz umożliwić dokładniejsze testy nosicielstwa i badania prenatalne w dotkniętych rodzinach. Ponieważ wiele innych genów związanych z chorobami również leży w splątanych, powtarzalnych obszarach naszego DNA, ta sama strategia może pomóc rozwiązywać trudne zagadnienia genetyczne znacznie wykraczające poza CAH.
Cytowanie: Lildballe, D.L., Huno, M.R., Ridder, L.O.R. et al. Genetic diagnosis of CYP21A2-related CAH: adaptive sampling long-read sequencing is an accurate and scalable solution. Eur J Hum Genet 34, 535–542 (2026). https://doi.org/10.1038/s41431-026-02019-8
Słowa kluczowe: wrodzona hiperplazja nadnerczy, CYP21A2, sekwencjonowanie długich odczytów, diagnoza genetyczna, adaptacyjne próbkowanie