Clear Sky Science · ru
PADP: прогрессивная и адаптивная очистка данных для эффективного инкрементального обучения
Почему важно учиться умнее на меньшем объеме данных
Современные системы искусственного интеллекта требуют больших объемов данных и вычислительных ресурсов, что делает их дорогими в обучении и затрудняет запуск на повседневных устройствах — телефонах, камерах или домашних роботах. В то же время такие системы все чаще должны продолжать учиться по мере появления новых типов изображений или ситуаций. В статье предлагается метод под названием PADP, который помогает нейронным сетям учиться эффективнее, решая во время обучения, какие примеры действительно заслуживают внимания, а какие можно безопасно пропустить, при этом не теряя важные знания из прошлого.
Обучение машинами шаг за шагом
Большинство систем распознавания изображений обучают один раз на фиксированном наборе данных и затем разворачивают. В реальном мире, однако, появляются новые категории: например, камера видеонаблюдения может потребовать распознавания новых объектов, а медицинская система — работать с новыми заболеваниями. Этот пошаговый процесс, называемый инкрементальным обучением, несет серьезную проблему: когда модель сосредотачивается на новых классах, она склонна забывать старые — это называется катастрофическим забыванием. Одновременно обучение на всех доступных данных на каждом шаге расточительно и часто невозможно на устройствах с ограниченной памятью и энергией. Авторы утверждают, что для практического инкрементального обучения необходимы методы, которые одновременно сокращают затраты на обучение и аккуратно сохраняют наиболее полезные старые и новые примеры.
Выбор трудных и нестабильных примеров
PADP решает эту задачу, присваивая каждому тренировочному примеру оценку полезности для модели в разные моменты времени. Первая оценка, называемая мгновенной сложностью, измеряет, насколько текущее предсказание модели отличается от правильного ответа. Если модель стабильно уверена и права по отношению к изображению, это изображение считается легким и менее важным для повторного показа. Если модель испытывает затруднения, изображение считается трудным и стоит оставить. Вторая оценка, вариация сложности, отслеживает, как эти значения сложности меняются в ходе обучения. Если сложность примера скачет вверх и вниз, это сигнализирует о нестабильном обучении или забывании — такие примеры особенно информативны. Объединяя текущую «трудность» примера и динамику её изменения, PADP формирует более богатое представление о том, над чем модели действительно нужно работать.
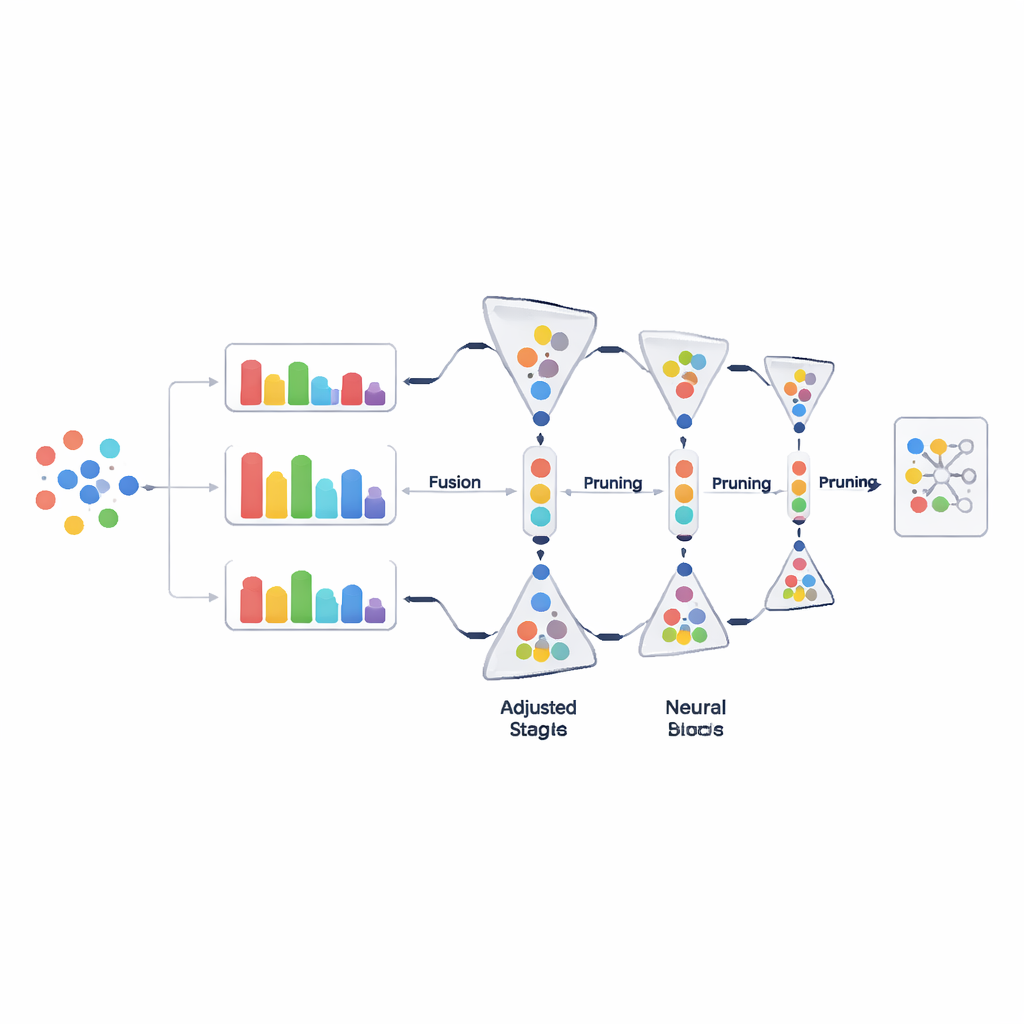
Постепенная очистка данных, а не одномоментное отбрасывание
Вместо того чтобы удалять большие куски данных одним решением, PADP постепенно сокращает тренировочный набор по мере обучения. После начального периода разогрева метод многократно оценивает все текущие примеры, ранжирует их по комбинированной оценке сложности и удаляет часть тех, которые кажутся наименее полезными. Доля удаления растет постепенно со временем, поэтому ранние решения консервативны, а поздние становятся более решительными, когда понимание модели стабилизируется. Простой, но важный механизм защиты гарантирует, что для каждого класса сохраняется по крайней мере минимальное число примеров, чтобы редкие категории случайно не исчезли. Такая постепенная и учитывающая классы обрезка делает тренировочные данные компактными без потери разнообразия.
Лучшие результаты при меньших затратах на обучение
Исследователи протестировали PADP на двух стандартных наборах изображений, CIFAR-100 и Tiny-ImageNet, в нескольких сценариях инкрементального обучения и сравнили его с многочисленными существующими методиками отбора или очистки данных. В прямых сравнениях вариант PADP с фиксированными целями по очистке показал более высокую точность, чем все базовые методы при тех же уровнях удаления, а в некоторых случаях превзошел точность обучения на полном наборе данных. Стандартная адаптивная версия, которая не требует заранее заданной доли удаления, улучшала точность примерно до 6 процентных пунктов по сравнению с обучением на всех данных, одновременно сокращая время обучения примерно до 53 процентов. Метод также интегрировался в разные фреймворки инкрементального обучения и последовательно уменьшал забывание старых классов, при этом повышая или по крайней мере сохраняя общую точность, что указывает на широкую применимость его преимуществ, а не на привязку к единой архитектуре модели.
Что это значит для повседневного ИИ
Проще говоря, PADP учит нейронные сети тренироваться умнее, а не усерднее. Постоянно оценивая, какие изображения легкие, какие сложные и какие модель постоянно переучивает или забывает, метод может отбрасывать избыточные примеры без вреда для производительности — и часто даже с её улучшением. При этом он защищает редкие классы от исчезновения при очистке. Такое сочетание эффективности и устойчивости особенно важно для ИИ-систем, которые должны обновляться со временем на устройствах с ограниченными ресурсами. Хотя текущее исследование сосредоточено на классификации изображений, базовая идея учета сложности и прогрессивной очистки данных может помочь будущим системам в разных областях осваивать новые навыки на ходу, не забывая уже изученное.
Цитирование: Duan, B., Liu, D., He, Z. et al. PADP: progressive and adaptive data pruning for efficient incremental learning. Sci Rep 16, 13440 (2026). https://doi.org/10.1038/s41598-026-43959-x
Ключевые слова: инкрементальное обучение, очистка данных, эффективность глубокого обучения, катастрофическое забывание, отбор образцов