Clear Sky Science · de
PADP: progressive and adaptive data pruning for efficient incremental learning
Warum intelligenteres Lernen mit weniger Daten wichtig ist
Moderne KI‑Systeme sind hungrig nach Daten und Rechenleistung, wodurch sie teuer zu trainieren sind und sich nur schwer auf Alltagsgeräten wie Telefonen, Kameras oder Hausrobotern betreiben lassen. Zugleich müssen diese Systeme immer öfter über die Zeit hinweg weiterlernen, sobald neue Bildtypen oder Situationen auftreten. Dieses Papier stellt eine Methode namens PADP vor, die neuronalen Netzen hilft, effizienter zu lernen, indem sie während des Trainings entscheidet, welche Beispiele wirklich Aufmerksamkeit verdienen und welche bedenkenlos übersprungen werden können — ohne dabei wichtiges früheres Wissen zu verlieren.
Maschinen in kleinen Schritten lehren
Die meisten Bilderkennungs‑Systeme werden einmal auf einem festen Datensatz trainiert und dann eingesetzt. In der realen Welt tauchen jedoch ständig neue Kategorien auf: Eine Sicherheitskamera muss womöglich neue Objekte erkennen, oder ein medizinisches System mit neuen Krankheiten zurechtkommen. Dieser schrittweise Prozess, bekannt als inkrementelles Lernen, bringt eine große Herausforderung mit sich: Wenn ein Modell sich auf neue Klassen konzentriert, neigt es dazu, ältere zu vergessen — ein Problem, das als katastrophales Vergessen bezeichnet wird. Gleichzeitig ist es verschwenderisch und oft unmöglich, bei jedem neuen Schritt auf allen verfügbaren Daten zu trainieren, besonders auf Geräten mit begrenztem Speicher und Energie. Die Autorinnen und Autoren argumentieren, dass inkrementelles Lernen praktikabel werden muss, indem man sowohl den Trainingsaufwand reduziert als auch die nützlichsten alten und neuen Beispiele sorgfältig bewahrt.
Schwierige und instabile Beispiele auswählen
PADP geht dieses Problem an, indem jede Trainingsprobe danach bewertet wird, wie nützlich sie für das Modell zu verschiedenen Zeitpunkten ist. Der erste Wert, die sogenannte Instant‑Difficulty‑Score, misst, wie stark die aktuelle Vorhersage des Modells von der richtigen Antwort abweicht. Wenn das Modell bei einem Bild konstant sicher und korrekt ist, gilt dieses Bild als einfach und weniger wichtig, noch einmal gesehen zu werden. Wenn das Modell Schwierigkeiten hat, wird das Bild als schwierig eingestuft und behalten. Der zweite Wert, die Variation‑of‑Difficulty‑Score, betrachtet, wie sich diese Schwierigkeit im Verlauf des Trainings verändert. Wenn die Schwierigkeit einer Probe auf und ab springt, signalisiert das instabiles Lernen oder Vergessen, und die Methode behandelt solche Beispiele als besonders informativ. Indem PADP kombiniert, wie schwer ein Beispiel gerade ist und wie sich seine Schwierigkeit entwickelt, entsteht ein reichhaltigeres Bild dessen, worauf das Modell tatsächlich üben sollte.
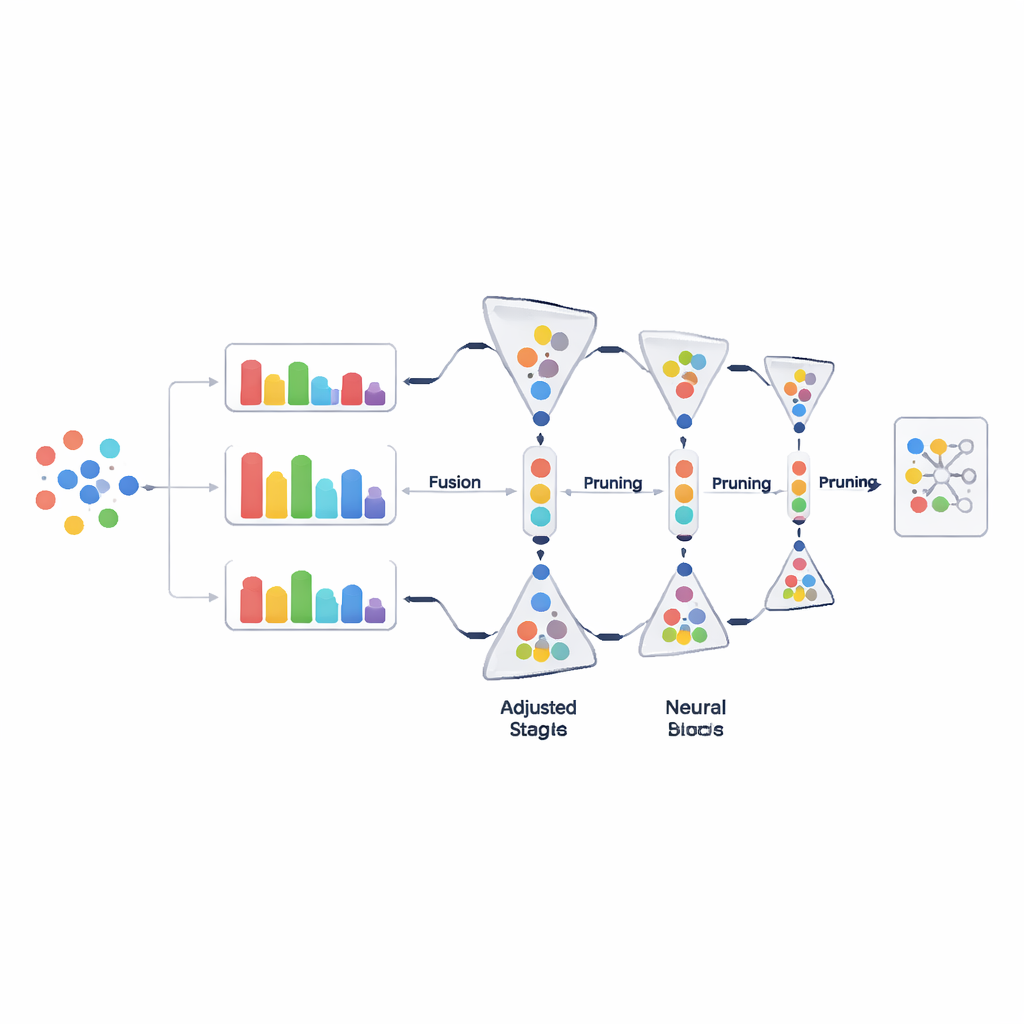
Daten schrittweise beschneiden, nicht auf einmal
Statt große Datenmengen in einer einzigen Entscheidung wegzuwerfen, beschneidet PADP den Trainingssatz progressiv, während das Lernen voranschreitet. Nach einer anfänglichen Aufwärmphase bewertet die Methode wiederholt alle aktuell verwendeten Beispiele, ordnet sie nach dem kombinierten Schwierigkeitsscore und entfernt einen Teil derjenigen, die am wenigsten hilfreich erscheinen. Das Beschneidungsverhältnis wächst im Laufe der Zeit schrittweise, sodass frühe Entscheidungen vorsichtig sind und später deutlich aggressiver werden, sobald das Modellverständnis stabiler ist. Eine einfache, aber wichtige Schutzmaßnahme stellt sicher, dass jede Klasse mindestens eine minimale Anzahl an Beispielen behält, damit seltene Kategorien nicht unbeabsichtigt ausgelöscht werden. Dieses schrittweise und klassenbewusste Stutzen hält die Trainingsdaten schlank, ohne die Vielfalt einzuschränken.
Stärkere Ergebnisse mit weniger Training
Die Forschenden testeten PADP auf zwei gängigen Bildsammlungen, CIFAR‑100 und Tiny‑ImageNet, unter mehreren inkrementellen Lern‑Szenarien und verglichen es mit vielen bestehenden Techniken zur Auswahl oder Beschneidung von Daten. In direkten Vergleichen erzielte eine Variante von PADP mit festen Beschneidungszielen höhere Genauigkeit als alle Baselines bei denselben Beschneidungsgraden und übertraf in einigen Fällen sogar die Genauigkeit des Trainings auf den kompletten Datensätzen. Die standardmäßige adaptive Version, die kein vorgegebenes Beschneidungsverhältnis benötigt, verbesserte die Genauigkeit um bis zu etwa 6 Prozentpunkte gegenüber dem Training mit vollständigen Daten, während sie die Trainingszeit um bis zu rund 53 Prozent reduzierte. Die Methode ließ sich zudem in mehrere verschiedene inkrementelle Lernrahmen integrieren und verringerte konsistent das Vergessen alter Klassen, während sie die Gesamtgenauigkeit steigerte oder zumindest erhielt — ein Hinweis darauf, dass ihr Nutzen breit anwendbar ist und nicht an ein einzelnes Modell‑Design gebunden ist.
Was das für alltägliche KI bedeutet
Einfach gesagt lehrt PADP neuronale Netze, klüger statt härter zu üben. Indem es fortlaufend beurteilt, welche Bilder einfach, welche knifflig sind und welche das Modell immer wieder neu lernt oder vergisst, kann es überflüssige Trainingsdaten entfernen, ohne die Leistung zu beeinträchtigen — und oft verbessert es diese sogar. Gleichzeitig schützt es seltener vorkommende Klassen davor, bei dieser Beschneidung zu verschwinden. Diese Kombination aus Effizienz und Stabilität ist besonders wichtig für KI‑Systeme, die sich im Laufe der Zeit auf ressourcenbeschränkten Geräten aktualisieren müssen. Während die aktuelle Arbeit auf Bildklassifikation fokussiert ist, könnte die zugrunde liegende Idee der schwierigkeits‑bewussten, progressiven Datenbeschneidung künftigen Systemen in vielen Bereichen helfen, neue Fähigkeiten live zu erlernen, ohne bereits Gelerntes zu vergessen.
Zitation: Duan, B., Liu, D., He, Z. et al. PADP: progressive and adaptive data pruning for efficient incremental learning. Sci Rep 16, 13440 (2026). https://doi.org/10.1038/s41598-026-43959-x
Schlüsselwörter: inkrementelles Lernen, Datenbeschneidung, Effizienz des Deep Learning, katastrophales Vergessen, Auswahl von Beispielen