Clear Sky Science · en
PADP: progressive and adaptive data pruning for efficient incremental learning
Why smarter learning from less data matters
Modern artificial intelligence systems are hungry for data and computing power, which makes them expensive to train and hard to run on everyday devices like phones, cameras, or home robots. At the same time, these systems increasingly need to keep learning over time as new types of images or situations appear. This paper introduces a method called PADP that helps neural networks learn more efficiently by deciding, during training, which examples are truly worth paying attention to and which can be safely skipped, all while avoiding the loss of important past knowledge.
Teaching machines in small steps
Most image recognition systems are trained once on a fixed pile of data and then deployed. In the real world, however, new categories keep appearing: a security camera might need to recognize new objects, or a medical system might have to deal with new diseases. This step-by-step process, known as incremental learning, brings a major challenge: when a model focuses on new classes, it tends to forget older ones, a problem called catastrophic forgetting. At the same time, training on all available data for every new step is wasteful and often impossible on devices with limited memory and power. The authors argue that to make incremental learning practical, we need methods that both reduce training effort and carefully preserve the most useful old and new examples.
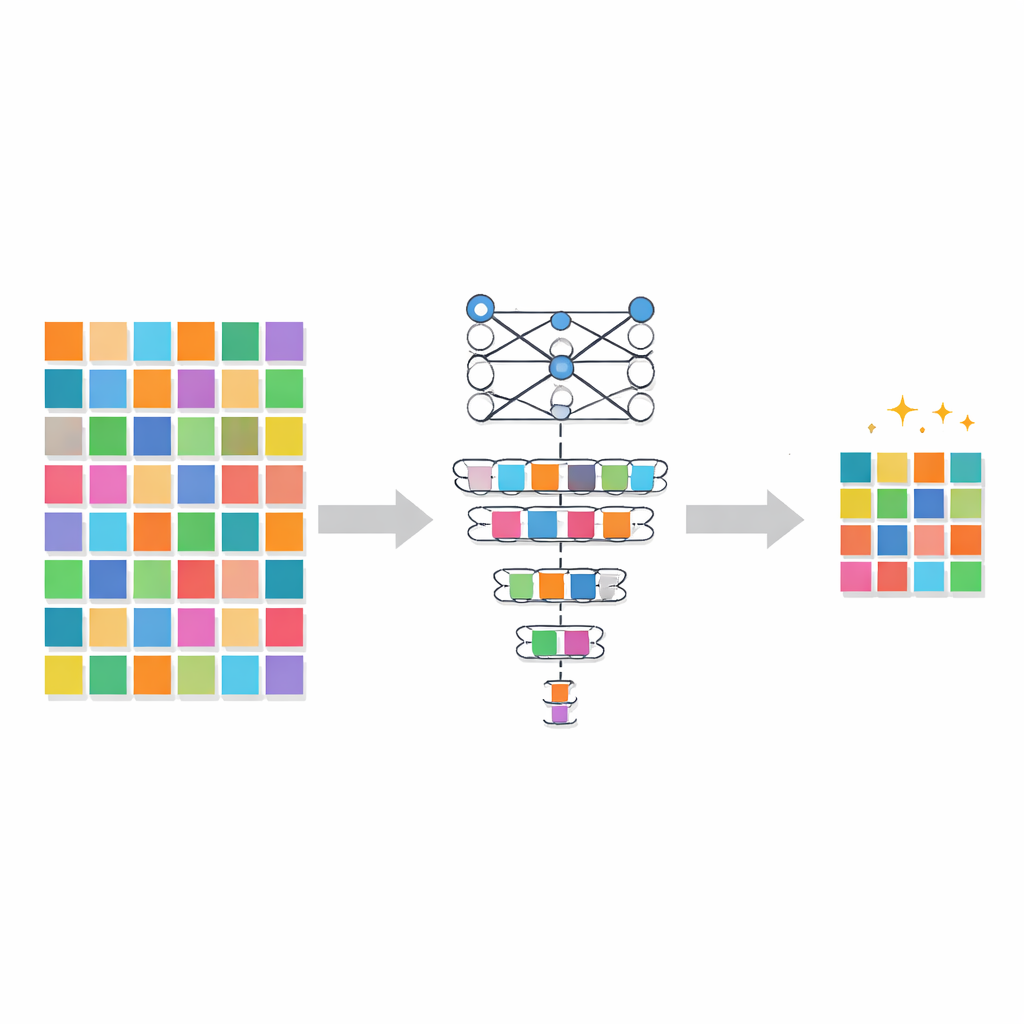
Picking hard and unstable examples
PADP tackles this by scoring each training example according to how useful it is for the model at different moments in time. The first score, called the instant difficulty score, measures how much the model’s current prediction differs from the correct answer. If the model is consistently confident and correct on an image, that image is considered easy and less critical to see again. If it struggles, the image is treated as difficult and worth keeping. The second score, the variation of difficulty score, looks at how these difficulty values change over the course of training. If an example’s difficulty jumps up and down, it signals unstable learning or forgetting, and the method treats such examples as especially informative. By combining how hard an example is right now with how its difficulty evolves, PADP builds a richer picture of what the model truly needs to practice on.
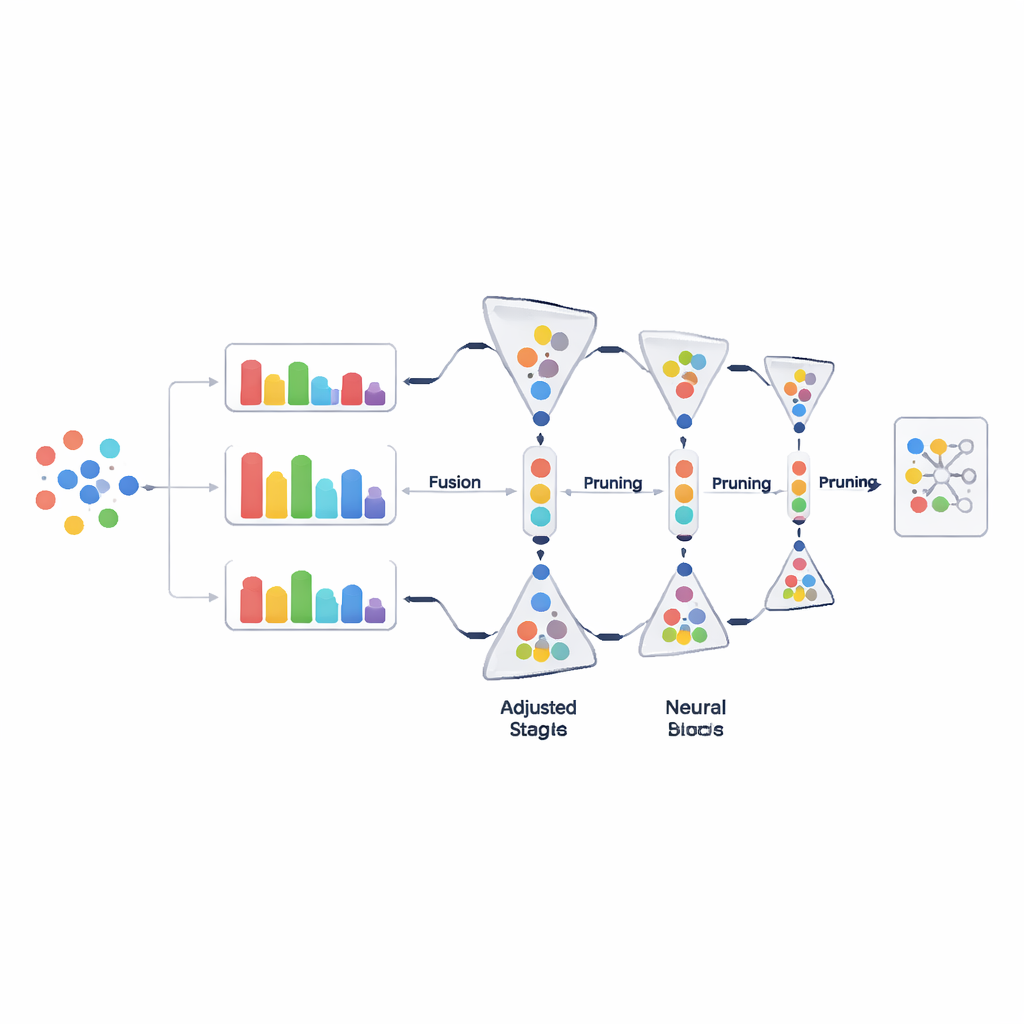
Pruning data step by step, not all at once
Instead of throwing away large chunks of data in a single decision, PADP prunes the training set progressively as learning proceeds. After an initial warm-up period, the method repeatedly evaluates all currently used examples, ranks them by the combined difficulty score, and removes a portion of those that appear least helpful. The pruning ratio grows gradually over time, so early decisions are conservative and later ones are more aggressive once the model’s understanding has stabilized. A simple but important safeguard ensures that each class keeps at least a minimum number of examples, so rare categories are not unintentionally wiped out. This gradual and class-aware trimming keeps the training data lean without sacrificing variety.
Stronger results with less training
The researchers tested PADP on two standard image collections, CIFAR-100 and Tiny-ImageNet, under several incremental learning setups and compared it against many existing techniques for selecting or pruning data. In head-to-head comparisons, a variant of PADP with fixed pruning targets achieved higher accuracy than all baselines at the same pruning levels, and even exceeded the accuracy of training on the full datasets in some cases. The default adaptive version, which does not require a preset pruning ratio, improved accuracy by up to about 6 percentage points over full-data training while cutting training time by as much as roughly 53 percent. The method also plugged into several different incremental learning frameworks and consistently reduced forgetting of old classes while boosting or at least maintaining overall accuracy, suggesting that its benefits are broad rather than tied to a single model design.
What this means for everyday AI
In plain terms, PADP teaches neural networks to practice smarter, not harder. By continuously judging which images are easy, which are tricky, and which the model keeps relearning or forgetting, it can trim away redundant training without harming performance—and often even improves it. At the same time, it protects less common classes from disappearing during this pruning. This combination of efficiency and stability is especially important for AI systems that must update themselves over time on resource-limited devices. While the current work focuses on image classification, the underlying idea of difficulty-aware, progressive data pruning could help future systems in many domains learn new skills on the fly without forgetting what they already know.
Citation: Duan, B., Liu, D., He, Z. et al. PADP: progressive and adaptive data pruning for efficient incremental learning. Sci Rep 16, 13440 (2026). https://doi.org/10.1038/s41598-026-43959-x
Keywords: incremental learning, data pruning, deep learning efficiency, catastrophic forgetting, sample selection