Clear Sky Science · fr
PADP : élagage de données progressif et adaptatif pour un apprentissage incrémental efficace
Pourquoi il est important d'apprendre mieux avec moins de données
Les systèmes d'intelligence artificielle modernes sont gourmands en données et en puissance de calcul, ce qui les rend coûteux à entraîner et difficiles à faire fonctionner sur des dispositifs courants comme les téléphones, les caméras ou les robots domestiques. Parallèlement, ces systèmes doivent de plus en plus continuer à apprendre au fil du temps lorsque de nouveaux types d'images ou de situations apparaissent. Cet article présente une méthode appelée PADP qui aide les réseaux neuronaux à apprendre plus efficacement en décidant, pendant l'entraînement, quels exemples méritent vraiment d'être retenus et lesquels peuvent être ignorés sans risque, tout en évitant la perte de connaissances importantes acquises auparavant.
Apprendre par petites étapes
La plupart des systèmes de reconnaissance d'images sont entraînés une fois sur un jeu de données fixe puis déployés. Dans la réalité, cependant, de nouvelles catégories continuent d'apparaître : une caméra de surveillance peut devoir reconnaître de nouveaux objets, ou un système médical peut devoir gérer de nouvelles maladies. Ce processus étape par étape, appelé apprentissage incrémental, pose un défi majeur : lorsqu'un modèle se concentre sur de nouvelles classes, il a tendance à oublier les anciennes, un problème nommé oubli catastrophique. En même temps, entraîner sur l'ensemble des données disponibles à chaque nouvelle étape est coûteux et souvent impossible sur des dispositifs à mémoire et énergie limitées. Les auteurs soutiennent que pour rendre l'apprentissage incrémental pratique, il faut des méthodes qui réduisent l'effort d'entraînement tout en préservant soigneusement les exemples anciens et nouveaux les plus utiles.
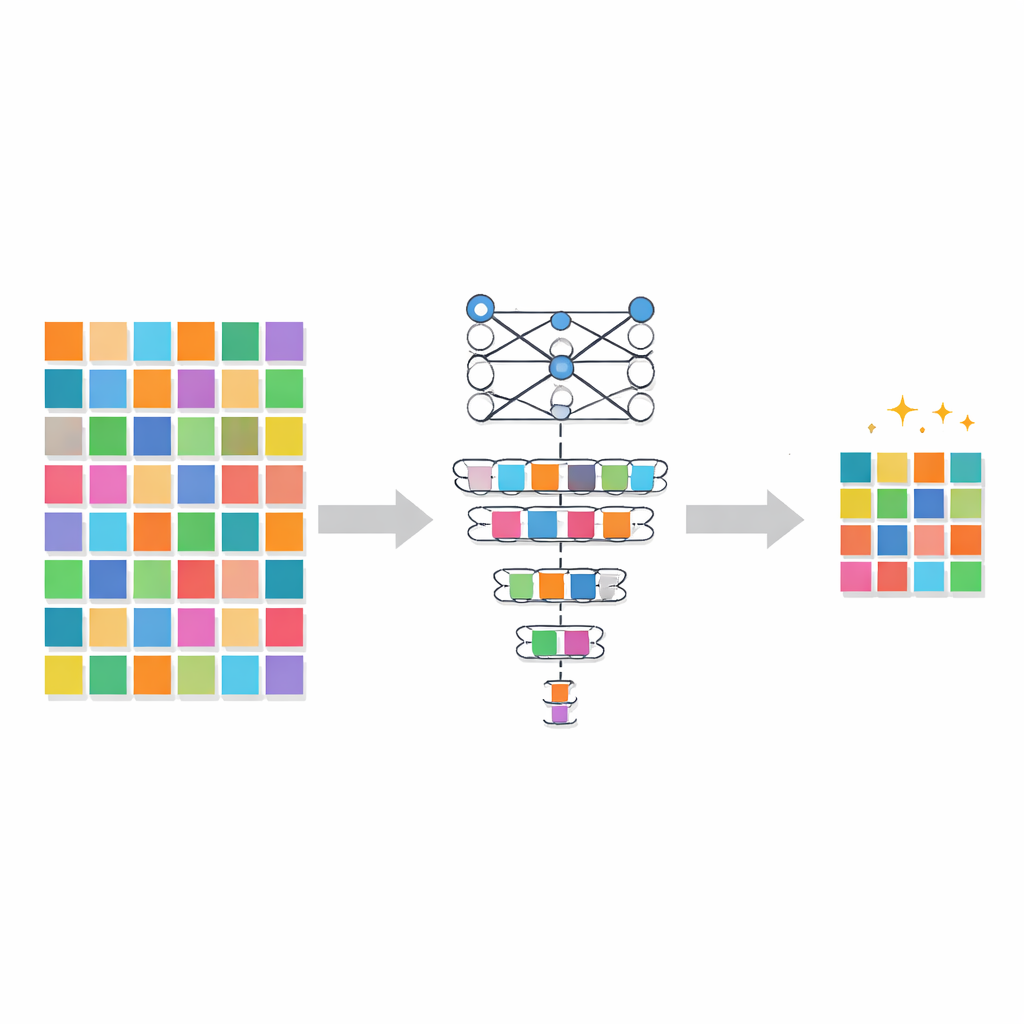
Sélectionner les exemples difficiles et instables
PADP aborde ce problème en notant chaque exemple d'entraînement selon son utilité pour le modèle à différents instants. Le premier score, appelé score de difficulté instantané, mesure à quel point la prédiction actuelle du modèle diffère de la réponse correcte. Si le modèle est de façon constante confiant et correct sur une image, cette image est considérée comme facile et moins critique à réviser. S'il a des difficultés, l'image est traitée comme difficile et mérite d'être conservée. Le second score, la variation du score de difficulté, observe comment ces valeurs de difficulté évoluent au cours de l'entraînement. Si la difficulté d'un exemple fluctue fortement, cela signale un apprentissage instable ou un oubli, et la méthode considère ces exemples comme particulièrement informatifs. En combinant la difficulté présente d'un exemple et l'évolution de cette difficulté, PADP construit une image plus riche de ce que le modèle a vraiment besoin de pratiquer.
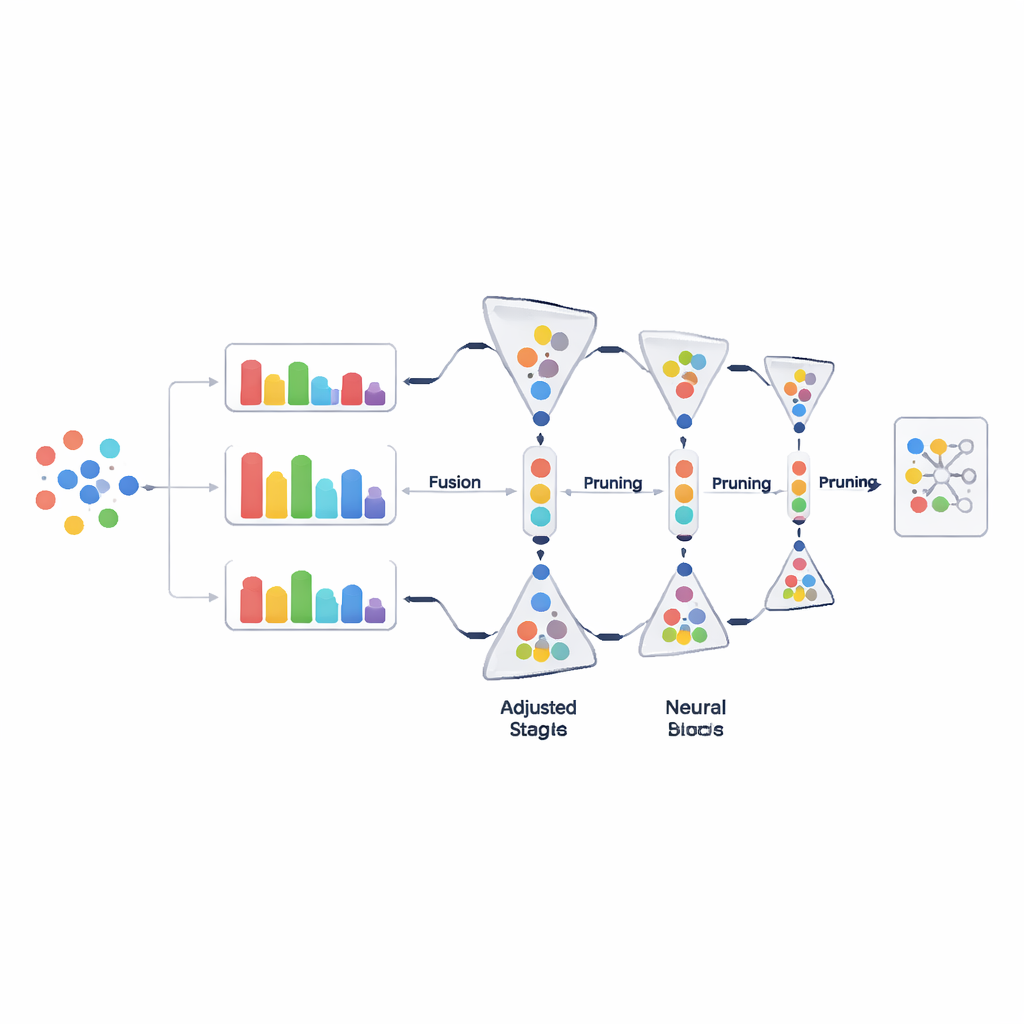
Élagage progressif des données, pas tout d'un coup
Plutôt que de supprimer de gros morceaux de données en une seule décision, PADP taille l'ensemble d'entraînement progressivement au fur et à mesure de l'apprentissage. Après une période d'échauffement initiale, la méthode évalue à répétition tous les exemples actuellement utilisés, les classe selon le score de difficulté combiné, et retire une portion de ceux qui semblent les moins utiles. Le ratio d'élagage augmente progressivement dans le temps, de sorte que les décisions prises tôt sont conservatrices et que les suivantes deviennent plus agressives une fois que la compréhension du modèle s'est stabilisée. Une précaution simple mais importante garantit que chaque classe conserve au moins un nombre minimal d'exemples, afin que les catégories rares ne soient pas effacées par inadvertance. Cette coupe progressive et consciente des classes garde les données d'entraînement maigres sans sacrifier la diversité.
Des résultats supérieurs avec moins d'entraînement
Les chercheurs ont testé PADP sur deux collections d'images standards, CIFAR-100 et Tiny-ImageNet, dans plusieurs scénarios d'apprentissage incrémental et l'ont comparé à de nombreuses techniques existantes de sélection ou d'élagage de données. En comparaison directe, une variante de PADP avec des cibles d'élagage fixes a atteint une précision supérieure à toutes les méthodes de référence aux mêmes niveaux d'élagage, et a même dépassé la précision obtenue en entraînant sur l'intégralité des jeux de données dans certains cas. La version adaptative par défaut, qui ne nécessite pas de ratio d'élagage prédéfini, a amélioré la précision d'environ 6 points de pourcentage par rapport à l'entraînement sur l'ensemble des données tout en réduisant le temps d'entraînement d'environ 53 % dans certains cas. La méthode s'est aussi intégrée à plusieurs cadres d'apprentissage incrémental différents et a systématiquement réduit l'oubli des anciennes classes tout en améliorant ou en maintenant la précision globale, ce qui suggère que ses bénéfices sont larges et non liés à un seul design de modèle.
Ce que cela signifie pour l'IA du quotidien
En termes clairs, PADP apprend aux réseaux neuronaux à s'exercer plus intelligemment que plus intensément. En jugeant en continu quelles images sont faciles, quelles images sont délicates et lesquelles le modèle réapprend ou oublie, il peut éliminer les redondances d'entraînement sans nuire aux performances — et améliore souvent celles-ci. En même temps, il protège les classes moins fréquentes de la disparition lors de cet élagage. Cette combinaison d'efficacité et de stabilité est particulièrement importante pour les systèmes d'IA qui doivent se mettre à jour au fil du temps sur des appareils aux ressources limitées. Bien que le travail actuel se concentre sur la classification d'images, l'idée sous-jacente d'un élagage de données progressif et conscient de la difficulté pourrait aider les systèmes futurs dans de nombreux domaines à apprendre de nouvelles compétences à la volée sans oublier ce qu'ils savent déjà.
Citation: Duan, B., Liu, D., He, Z. et al. PADP: progressive and adaptive data pruning for efficient incremental learning. Sci Rep 16, 13440 (2026). https://doi.org/10.1038/s41598-026-43959-x
Mots-clés: apprentissage incrémental, élagage de données, efficacité de l'apprentissage profond, oubli catastrophique, sélection d'échantillons