Clear Sky Science · ja
PADP: 効率的な増分学習のための漸進的かつ適応的なデータ削減
少ないデータから賢く学ぶことが重要な理由
現代の人工知能システムは大量のデータと計算資源を必要とするため、学習にコストがかかり、スマートフォンやカメラ、家庭用ロボットのような日常的なデバイスで動かすのが難しくなります。同時に、こうしたシステムは新しい種類の画像や状況が現れるたびに継続的に学習し続ける必要が増しています。本論文はPADPと呼ばれる手法を紹介します。PADPは学習中にどの例が本当に注目する価値があるか、どれを安全に省略できるかを判断しつつ、過去の重要な知識を失わないようにしてニューラルネットワークの学習をより効率化します。
段階的に機械を教える
多くの画像認識システムは一度固定されたデータで訓練されてから展開されますが、現実には新しいカテゴリが次々と現れます。防犯カメラが新しい物体を認識する必要が出たり、医療システムが新たな疾患に対処したりすることがその例です。この段階的な過程は増分学習と呼ばれ、大きな課題をもたらします。モデルが新しいクラスに集中すると、古いクラスを忘れがちになる—これが壊滅的忘却です。さらに、毎段階で利用可能なすべてのデータで学習するのは無駄が多く、メモリや電力が限られたデバイスでは不可能なこともあります。著者らは、増分学習を実用化するには、学習負荷を減らしつつ過去と新しい例の中で最も有用なものを慎重に保存する方法が必要だと論じています。
難しい例と不安定な例を選ぶ
PADPは各訓練例を、その時点でモデルにとってどれだけ有用かに応じてスコア付けすることでこの課題に対処します。最初のスコアである「瞬時難度スコア」は、モデルの現在の予測が正解とどれだけ乖離しているかを測ります。モデルが一貫して自信を持って正しく分類できる画像は簡単と見なされ、再度見る価値は低いと判断されます。一方、モデルが苦戦する画像は難しいと判断され保持に値します。二つ目のスコアである「難度変動スコア」は、訓練の過程でこれらの難度値がどのように変化するかを見ます。ある例の難度が上下に大きく振れる場合、それは学習の不安定さや忘却を示し、そのような例は特に情報量が多いと扱われます。今の難しさと難度の推移を組み合わせることで、PADPはモデルが練習すべき対象のより豊かな像を構築します。
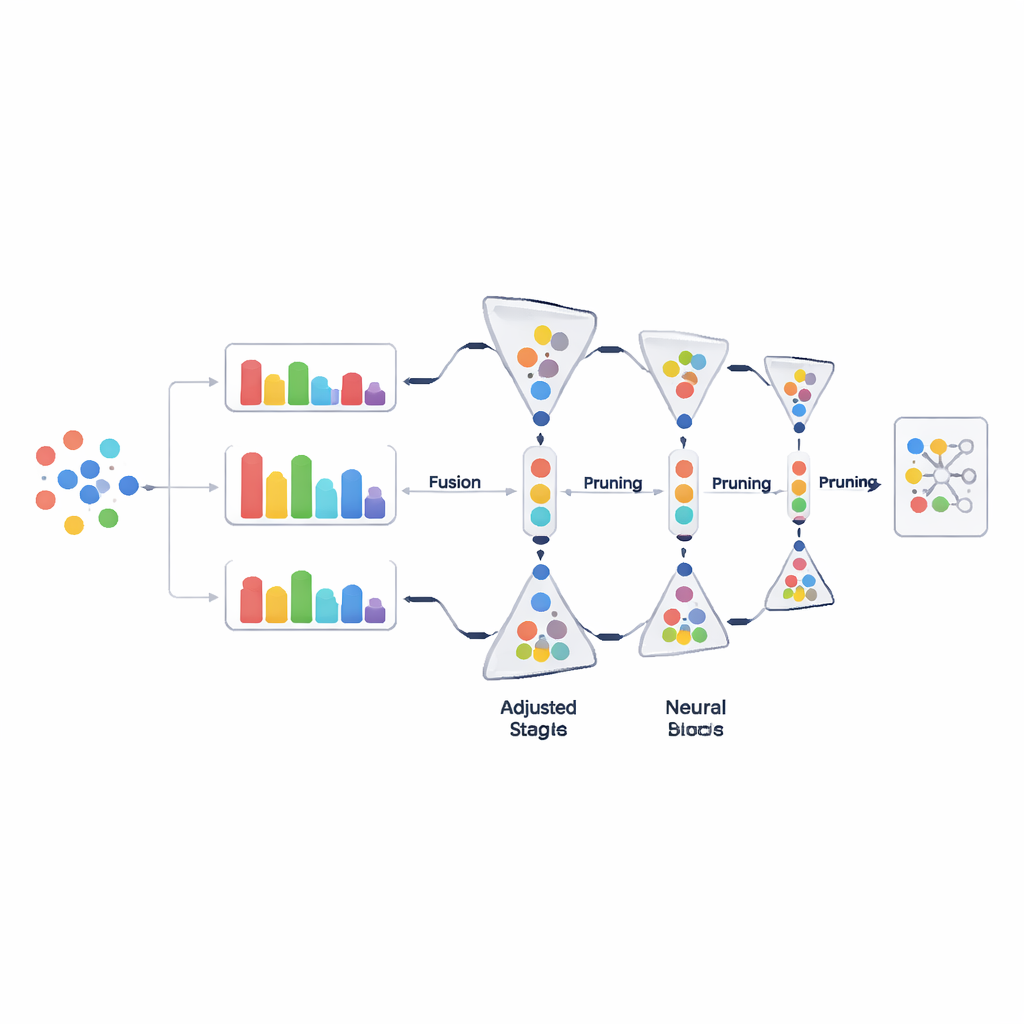
一度にではなく段階的にデータを削る
大量のデータを一度に捨てる代わりに、PADPは学習の進行に合わせて訓練セットを漸進的に刈り込んでいきます。初期のウォームアップ期間の後、手法は現在使われている全ての例を繰り返し評価し、結合された難度スコアでランク付けして、最も効果が薄そうな例の一部を削除します。剪定比率は時間とともに段階的に大きくなり、初期の決定は保守的で、モデルの理解が安定した後はより積極的になります。単純だが重要な保護策として、各クラスが最低限の例数を保持することが保証されており、希少なカテゴリが意図せず消されることを防ぎます。この漸進的かつクラスに配慮したトリミングにより、訓練データの多様性を損なうことなく軽量化が図れます。
少ない学習でより高い性能
研究者らはPADPを二つの標準的な画像データセット、CIFAR-100とTiny-ImageNetで複数の増分学習設定下で評価し、データ選択や剪定の既存手法と比較しました。直接比較では、固定の剪定目標を持つPADPの変種が同じ剪定率で全てのベースラインよりも高い精度を達成し、場合によってはフルデータでの訓練を上回る精度を示しました。事前設定の剪定比率を必要としないデフォルトの適応版は、フルデータ学習に対して最大で約6パーセンテージポイントの精度向上を示し、訓練時間を最大で約53パーセント削減しました。さらにこの手法は複数の増分学習フレームワークにも組み込め、古いクラスの忘却を一貫して減らしつつ、全体の精度を向上させるか少なくとも維持することが示され、単一のモデル設計に依存しない広い有用性を示唆しています。
日常のAIにとっての意義
平たく言えば、PADPはニューラルネットワークに「より多く」ではなく「より賢く」練習させます。どの画像が簡単で、どれが難しく、どれをモデルが繰り返し再学習したり忘れたりしているかを継続的に判断することで、冗長な訓練を削減しつつ性能を損なわず、しばしば改善すらももたらします。同時に、剪定の過程で希少クラスが消えるのを防ぎます。この効率と安定性の組み合わせは、リソースの限られたデバイス上で継続的に自己更新する必要があるAIシステムにとって特に重要です。本研究は画像分類に焦点を当てていますが、難度認識に基づく漸進的データ剪定という基本的な考え方は、将来的に多くの領域で新しいスキルを学びつつ既存の知識を保持するのに役立つ可能性があります。
引用: Duan, B., Liu, D., He, Z. et al. PADP: progressive and adaptive data pruning for efficient incremental learning. Sci Rep 16, 13440 (2026). https://doi.org/10.1038/s41598-026-43959-x
キーワード: 増分学習, データ削減, ディープラーニングの効率化, 壊滅的忘却, サンプル選択