Clear Sky Science · he
PADP: גזירה מתקדמת והסתגלותית של נתונים ללמידה הדרגתית יעילה
מדוע חשוב ללמוד חכם יותר עם פחות נתונים
מערכות בינה מלאכותית מודרניות רעבות לנתונים ולחישוב, מה שהופך אותן ליקרות לאימון וקשות להרצה על מכשירים יומיומיים כמו טלפונים, מצלמות או רובוטים ביתיים. במקביל, מערכות אלה נדרשות יותר ויותר להמשיך ללמוד בזמן אמת ככל שמופיעים סוגים חדשים של תמונות או מצבים. המאמר מציג שיטה בשם PADP שעוזרת לרשתות נוירוניות ללמוד ביעילות רבה יותר על ידי קבלת ההחלטה, בזמן האימון, אילו דוגמאות באמת ראויות לתשומת לב ואילו אפשר לדלג עליהן בבטחה, וכל זאת בלי לאבד ידע חשוב מהעבר.
להדריך מכונות בצעדים קטנים
רוב מערכות זיהוי התמונה מאומנות פעם אחת על ערמת נתונים קבועה ואז יוצאות לשימוש. בעולם האמיתי, עם זאת, מופיעים כל העת קטגוריות חדשות: מצלמת אבטחה עשויה להזדקק לזיהוי עצמים חדשים, או מערכת רפואית תתמודד עם מחלות חדשות. תהליך זה של צמיחה שלב אחרי שלב, המכונה למידה הדרגתית, מביא אתגר מרכזי: כאשר המודל מתמקד במחלקות חדשות הוא נוטה לשכוח את הישנות — בעיה המכונה שכחה קטסטרופלית. במקביל, אימון על כל הנתונים הזמינים בכל שלב חדש הוא בזבזני ולעיתים בלתי אפשרי על מכשירים עם זיכרון ואנרגיה מוגבלים. הכותבים טוענים שכדי להפוך את הלמידה ההדרגתית לפרקטית, נדרשות שיטות שמפחיתות את מאמץ האימון ובאותו הזמן שומרות בקפידה על הדוגמאות הישנות והחדשות החשובות ביותר.
בחירת דוגמאות קשות ובלתי יציבות
PADP מתמודדת עם זה על ידי דירוג כל דוגמה באימון לפי כמה היא מועילה למודל ברגעים שונים בזמן. הציון הראשון, שנקרא ציון הקושי המידי, מודד עד כמה תחזית המודל הנוכחית שונה מהתשובה הנכונה. אם המודל יציב ובטוח ונכון לגבי תמונה, תמונה זו נחשבת לקלה ופחות קריטית לראות שוב. אם הוא מתקשה, התמונה נתפסת כקשה ושווה שמירה. הציון השני, שונות הציון של הקושי, בוחן כיצד ערכי הקושי האלה משתנים במהלך האימון. אם הקושי של דוגמה עולה ויורד בתדירות, זה מאותת על למידה לא יציבה או שכחה, והשיטה מתייחסת לדוגמאות כאלה כמידעיות במיוחד. באמצעות שילוב בין כמה קשה הדבר ברגע נתון לבין כיצד הקושי משתנה, PADP בונה תמונה עשירה יותר של מה שהמודל באמת צריך להתאמן עליו.
גזירה של נתונים צעד אחר צעד, לא בבת אחת
במקום להשליך כמויות גדולות של נתונים בהחלטה יחידה, PADP מעדנת את קבוצת האימון באופן הדרגתי ככל שהלמידה מתקדמת. לאחר תקופת חימום ראשונית, השיטה מעריכה שוב ושוב את כל הדוגמאות המשמשות כרגע, מדורגת אותן לפי ציון הקושי המשולב, ומסירה חלק מאלו שנראות הכי פחות מועילות. יחס הגזירה גדל בהדרגה עם הזמן, כך שההחלטות הראשוניות שמרניות וההחלטות המאוחרות יותר תוקפניות יותר ברגע שהבנת המודל התייצבה. מנגנון פשוט אך חשוב מבטיח שלכל מחלקה יישאר לפחות מספר מינימלי של דוגמאות, כדי שמחלקות נדירות לא יימחקו בטעות. הגזירה ההדרגתית והמודעת למחלקות זו שומרת על נתוני אימון רזים בלי לוותר על גיוון.
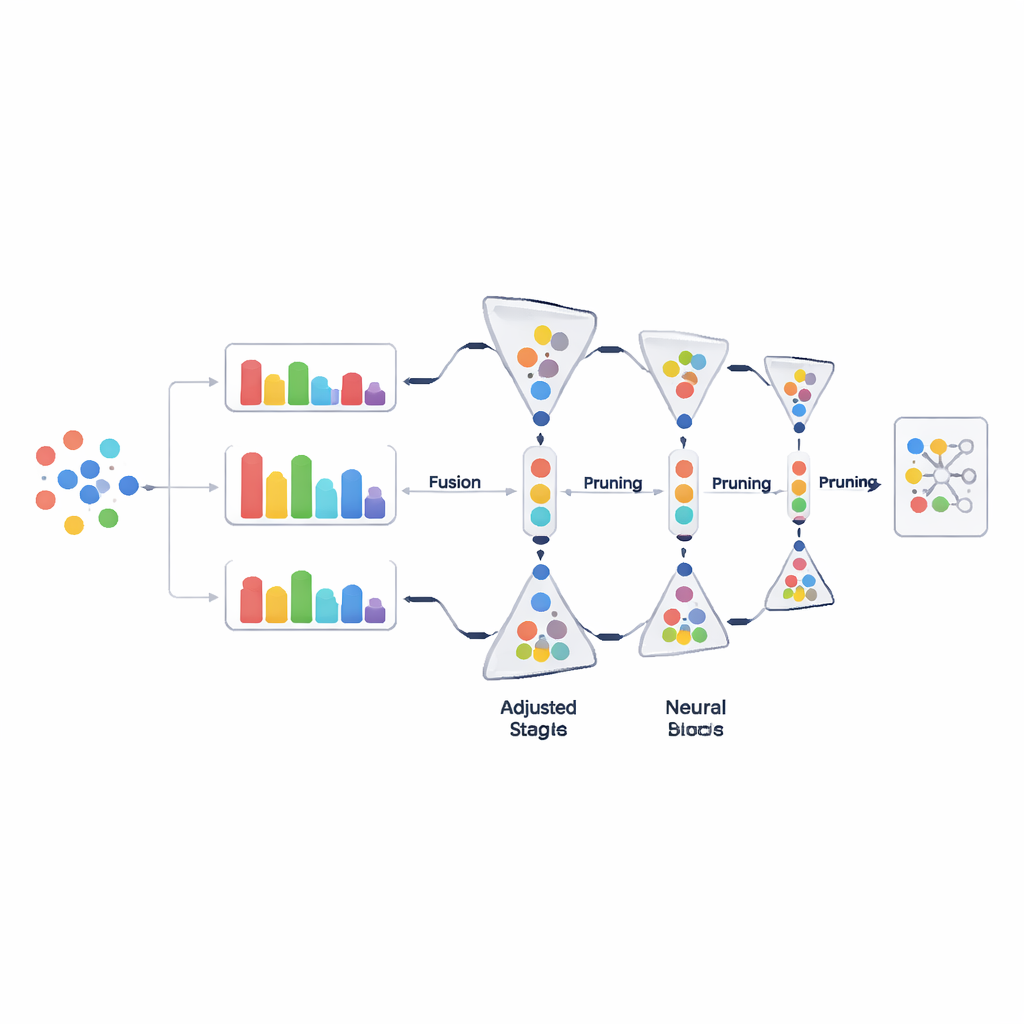
תוצאות חזקות יותר עם פחות אימון
החוקרים בחנו את PADP על שתי מאגרי תמונות סטנדרטיים, CIFAR-100 ו-Tiny-ImageNet, במספר סביבות של למידה הדרגתית והשוו אותה לטכניקות רבות קיימות לבחירה או גזירת נתונים. בהשוואות ישירות, גרסה של PADP עם יעדי גזירה קבועים השיגה דיוק גבוה יותר מכל הבסיסים ברמות גזירה זהות, ואף עלתה על הדיוק של אימון על כל מערכי הנתונים במקרים מסוימים. הגרסה ההסתגלותית המוגדרת כברירת מחדל, שאינה דורשת יחס גזירה מראש, שיפרה את הדיוק בכ-עד כ־6 נקודות אחוז לעומת אימון על כל הנתונים תוך קיצוץ זמן האימון בעד כ־53 אחוזים. השיטה גם הוטמעה במספר מסגרות שונות של למידה הדרגתית והפחיתה בעקביות את השכחה של מחלקות ישנות תוך שיפור או לפחות שמירה על הדיוק הכולל, מה שמרמז שהיתרונות שלה רחבים ולא תלוים בעיצוב מודל יחיד.
מה משמעות הדבר עבור בינה יומיומית
במלים פשוטות, PADP מלמדת רשתות נוירוניות להתאמן בחוכמה, לא בחומרה. על ידי שיפוט מתמשך אילו תמונות קלות, אילו מורכבות, ואילו המודל ממשיך ללמוד מחדש או לשכוח, היא יכולה לגזור חזרה נתוני אימון מיותרים מבלי לפגוע בביצועים — ולעיתים אפילו לשפר אותם. במקביל, היא מגנה על מחלקות פחות שכיחות מפני היעלמות במהלך הגזירה. השילוב הזה של יעילות ויציבות חשוב במיוחד עבור מערכות בינה מלאכותית שחייבות להתעדכן עם הזמן על מכשירים מוגבלי משאבים. בעוד שהעבודה הנוכחית מתמקדת בסיווג תמונות, הרעיון הבסיסי של גזירה פרוגרסיבית המודעת לקושי עשוי לעזור למערכות עתידיות בתחומים רבים ללמוד מיומנויות חדשות על הדרך מבלי לשכוח מה שהן כבר יודעות.
ציטוט: Duan, B., Liu, D., He, Z. et al. PADP: progressive and adaptive data pruning for efficient incremental learning. Sci Rep 16, 13440 (2026). https://doi.org/10.1038/s41598-026-43959-x
מילות מפתח: למידה הדרגתית, גזירת נתונים, יעילות בלמידה עמוקה, שכחה קטסטרופלית, בחירת דגימות