Clear Sky Science · pt
PADP: poda de dados progressiva e adaptativa para aprendizado incremental eficiente
Por que aprender melhor com menos dados importa
Sistemas modernos de inteligência artificial consomem muitos dados e poder de processamento, o que os torna caros para treinar e difíceis de executar em dispositivos do dia a dia como celulares, câmeras ou robôs domésticos. Ao mesmo tempo, esses sistemas precisam continuar aprendendo ao longo do tempo conforme surgem novos tipos de imagens ou situações. Este artigo apresenta um método chamado PADP que ajuda redes neurais a aprender de forma mais eficiente decidindo, durante o treinamento, quais exemplos realmente merecem atenção e quais podem ser ignorados com segurança, sem perder conhecimentos importantes adquiridos anteriormente.
Ensinando máquinas em pequenos passos
A maioria dos sistemas de reconhecimento de imagens é treinada uma vez sobre um conjunto fixo de dados e então implantada. No mundo real, porém, novas classes continuam a aparecer: uma câmera de segurança pode precisar reconhecer novos objetos, ou um sistema médico pode ter de lidar com doenças inéditas. Esse processo passo a passo, conhecido como aprendizado incremental, impõe um grande desafio: quando um modelo se concentra em classes novas, tende a esquecer as antigas, um problema chamado esquecimento catastrófico. Ao mesmo tempo, treinar com todos os dados disponíveis a cada novo passo é desperdício e muitas vezes impossível em dispositivos com memória e energia limitadas. Os autores argumentam que, para tornar o aprendizado incremental prático, precisamos de métodos que reduzam o esforço de treinamento e, ao mesmo tempo, preservem cuidadosamente os exemplos antigos e novos mais úteis.
Selecionando exemplos difíceis e instáveis
O PADP resolve isso pontuando cada exemplo de treinamento de acordo com sua utilidade para o modelo em diferentes momentos do treinamento. A primeira pontuação, chamada de score de dificuldade instantânea, mede o quanto a previsão atual do modelo difere da resposta correta. Se o modelo está consistentemente confiante e correto sobre uma imagem, essa imagem é considerada fácil e menos crítica para ver novamente. Se ele tem dificuldade, a imagem é tratada como difícil e vale a pena ser mantida. A segunda pontuação, a variação do score de dificuldade, observa como esses valores de dificuldade mudam ao longo do treinamento. Se a dificuldade de um exemplo oscila, isso sinaliza aprendizado instável ou esquecimento, e o método considera tais exemplos especialmente informativos. Ao combinar o quão difícil um exemplo é no presente com como sua dificuldade evolui, o PADP constrói uma imagem mais rica do que o modelo realmente precisa praticar.
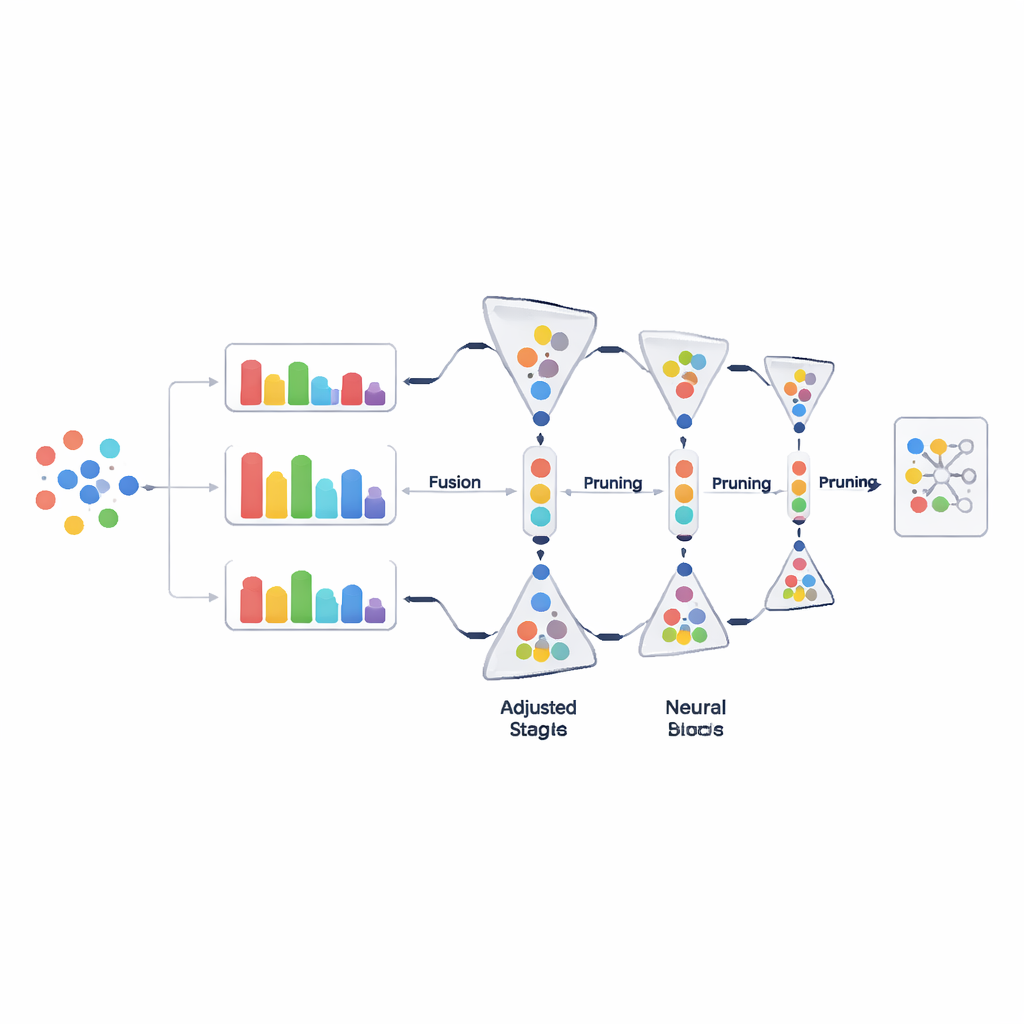
Poda de dados passo a passo, não tudo de uma vez
Em vez de descartar grandes blocos de dados em uma única decisão, o PADP vai podando o conjunto de treinamento progressivamente conforme o aprendizado avança. Após um período inicial de aquecimento, o método avalia repetidamente todos os exemplos em uso, os classifica pelo score combinado de dificuldade e remove uma parcela daqueles que parecem menos úteis. A razão de poda cresce gradualmente ao longo do tempo, de modo que decisões precoces são conservadoras e as posteriores se tornam mais agressivas quando a compreensão do modelo se estabiliza. Uma salvaguarda simples, mas importante, garante que cada classe mantenha pelo menos um número mínimo de exemplos, para que categorias raras não sejam eliminadas inadvertidamente. Esse corte gradual e sensível por classe mantém os dados de treinamento enxutos sem sacrificar a variedade.
Resultados melhores com menos treinamento
Os pesquisadores testaram o PADP em duas coleções padrão de imagens, CIFAR-100 e Tiny-ImageNet, sob vários cenários de aprendizado incremental e o compararam com diversas técnicas existentes de seleção ou poda de dados. Em comparações diretas, uma variante do PADP com metas de poda fixas alcançou maior acurácia do que todas as linhas de base nos mesmos níveis de poda e, em alguns casos, até superou a acurácia do treinamento com os conjuntos completos. A versão adaptativa padrão, que não requer uma razão de poda pré-definida, melhorou a acurácia em até cerca de 6 pontos percentuais em relação ao treinamento com todos os dados, ao mesmo tempo em que reduziu o tempo de treinamento em cerca de 53%. O método também foi integrado a diversos frameworks de aprendizado incremental e reduziu de forma consistente o esquecimento de classes antigas enquanto aumentava ou pelo menos mantinha a acurácia geral, o que sugere que seus benefícios são amplos e não dependem de um único projeto de modelo.
O que isso significa para a IA do dia a dia
Em termos simples, o PADP ensina redes neurais a praticarem de forma mais inteligente, não mais intensamente. Ao julgar continuamente quais imagens são fáceis, quais são desafiadoras e quais o modelo continua reaprendendo ou esquecendo, ele pode cortar treinos redundantes sem prejudicar o desempenho — e frequentemente até melhorá-lo. Ao mesmo tempo, protege classes menos comuns de desaparecerem durante a poda. Essa combinação de eficiência e estabilidade é especialmente importante para sistemas de IA que precisam se atualizar ao longo do tempo em dispositivos com recursos limitados. Embora o trabalho atual foque em classificação de imagens, a ideia subjacente de poda progressiva e consciente da dificuldade pode ajudar futuros sistemas em muitos domínios a aprender novas habilidades na prática sem esquecer o que já sabem.
Citação: Duan, B., Liu, D., He, Z. et al. PADP: progressive and adaptive data pruning for efficient incremental learning. Sci Rep 16, 13440 (2026). https://doi.org/10.1038/s41598-026-43959-x
Palavras-chave: aprendizado incremental, poda de dados, eficiência em deep learning, esquecimento catastrófico, seleção de amostras